精度与加速#
现代GPU架构通常可以使用较低精度张量数据或计算操作来节省内存和提高吞吐量。然而,在某些情况下,较低精度会引起数值稳定性问题,并进一步导致可重现性问题。因此,请确保您正在使用适当的精度。
TensorFloat-32 (TF32)#
引言#
NVIDIA为NVIDIA Ampere GPU及更新版本引入了一种新的数学模式TensorFloat-32 (TF32),详情请参阅 借助 NVIDIA TF32 Tensor Core 加速 AI 训练, TRAINING NEURAL NETWORKS WITH TENSOR CORES, CUDA 11 和 Ampere 架构。
TF32采用8个指数位、10个尾数位和一个符号位。
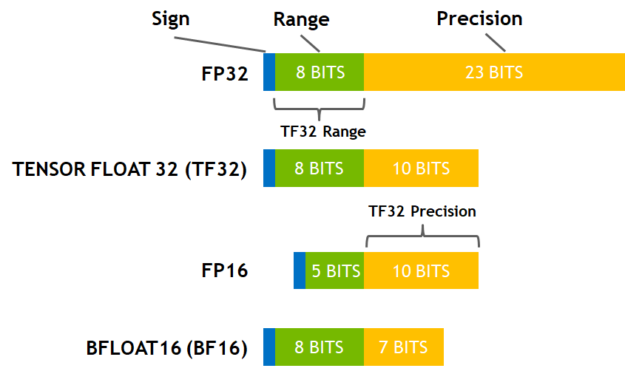
潜在影响#
尽管NVIDIA已经表明TF32模式对于大多数AI工作负载可以达到与float32相同的精度和收敛性,但一些用户仍然发现它对他们的应用程序有显著影响,详情请参阅 PyTorch and TensorFloat32。需要高精度矩阵操作的用户,例如传统的计算机图形操作和核方法,可能会受到TF32精度的影响。
请注意,所有使用 cuda.matmul 的操作都可能受到TF32模式的影响,因此影响范围非常广泛。
设置#
PyTorch TF32 默认值
torch.backends.cuda.matmul.allow_tf32 = False # in PyTorch 1.12 and later.
torch.backends.cudnn.allow_tf32 = True
请注意,存在可以覆盖上述标志的环境变量。例如,在 借助 NVIDIA TF32 Tensor Core 加速 AI 训练 中提及的环境变量 NVIDIA_TF32_OVERRIDE 以及 PyTorch 使用的 TORCH_ALLOW_TF32_CUBLAS_OVERRIDE。因此,在某些情况下,这些标志可能会被意外更改或覆盖。
如果您正在使用 NGC PyTorch 容器,该容器包含一个层 ENV TORCH_ALLOW_TF32_CUBLAS_OVERRIDE=1。默认值 torch.backends.cuda.matmul.allow_tf32 将被覆盖为 True。要恢复上游默认值,请在容器中运行 unset TORCH_ALLOW_TF32_CUBLAS_OVERRIDE,并相应地使用 Pytorch API torch.set_float32_matmul_precision, torch.backends.cudnn.allow_tf32=False。
我们建议用户在不确定时打印出这两个标志进行确认。
如果您通过实验确认您的模型在TF32模式下没有精度或收敛问题,并且您拥有NVIDIA Ampere GPU或更高版本,您可以将上述两个标志设置为 True 以加速您的模型。