转换#
通用接口#
Transform#
- class monai.transforms.Transform[source]#
Transform的抽象类。转换是一个可调用对象,用于处理data。它可能是有状态的,并可能就地修改
data,实现时应注意改变自身状态时的线程安全。当从多进程上下文中使用时,转换的实例变量是只读的。非线程安全的转换应继承
monai.transforms.ThreadUnsafe。该转换未使用的
data内容仍可能在复合转换的后续转换中使用。在
data中存储过多信息可能会导致内存问题或 IPC 同步问题,尤其是在 PyTorch DataLoader 的多进程环境中。
另请参阅
- abstract __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
MapTransform#
- class monai.transforms.MapTransform(keys, allow_missing_keys=False)[source]#
monai.transforms.Transform的子类,假定self.__call__的输入data是一个可变映射(MutableMapping),例如dict。keys参数将用于获取和设置实际要转换的数据项。也就是说,此转换的可调用对象应遵循以下模式def __call__(self, data): for key in self.keys: if key in data: # update output data with some_transform_function(data[key]). else: # raise exception unless allow_missing_keys==True. return data
- 抛出异常:
ValueError – 当
keys是一个空的可迭代对象时。TypeError – 当
keys类型不在Union[Hashable, Iterable[Hashable]]中时。
- abstract __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- call_update(data)[source]#
此函数应在每次 self.__call__(data) 后调用,使用 MetaTensor data[key] 中的内容更新 data[key_transforms] 和 data[key_meta_dict],以实现 MetaTensor 0.9.0 版本向后兼容。
RandomizableTrait#
LazyTrait#
- class monai.transforms.LazyTrait[source]#
一个接口,指示转换能够使用 MONAI 的延迟重采样功能执行。为此,实现类需要能够将其操作描述为伴随元数据的仿射矩阵或网格。此接口可供将转换适配到 MONAI 框架的人员以及 MONAI 转换的实现者扩展。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
MultiSampleTrait#
Randomizable#
- class monai.transforms.Randomizable[source]#
一个用于本地处理随机状态的接口,目前基于类变量 R,它是 np.random.RandomState 的实例。这提供了组件特有的确定性灵活性,而不会影响全局状态。建议将此 API 与
monai.data.DataLoader一起使用,以确保预处理管线的确定性行为。此 API 不是线程安全的。此外,深度复制此类的实例通常会导致随机性不足,因为随机状态会被复制。
LazyTransform#
RandomizableTransform#
- class monai.transforms.RandomizableTransform(prob=1.0, do_transform=True)[source]#
一个用于本地处理随机状态的接口,目前基于类变量 R,它是 np.random.RandomState 的实例。此类引入了一个随机化标志 _do_transform,主要用于随机数据增强转换。例如
from monai.transforms import RandomizableTransform class RandShiftIntensity100(RandomizableTransform): def randomize(self): super().randomize(None) self._offset = self.R.uniform(low=0, high=100) def __call__(self, img): self.randomize() if not self._do_transform: return img return img + self._offset transform = RandShiftIntensity() transform.set_random_state(seed=0) print(transform(10))
Compose#
- class monai.transforms.Compose(transforms=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
Compose提供了将一系列可调用对象按顺序串联起来的能力。序列中的每个转换必须接受一个参数并返回一个值。Compose可以通过两种方式使用使用接受并返回单个 ndarray / tensor / 类 tensor 参数的一系列转换。
使用接受并返回包含一个或多个参数的字典的一系列转换。此类转换必须具有直通语义,即字典中未使用的值必须复制到返回字典中。要求在每个转换的输入和输出之间复制字典。
如果某个转换以数据项字典作为输入,并在转换链中返回数据项序列,则当 map_items 为 True(默认值)时,所有后续转换将应用于此列表中的每个项。如果 map_items 为 False,则返回的序列将整体传递给链中的下一个可调用对象。
例如
Compose([transformA, transformB, transformC], map_items=True)(data_dict) 可以对输入的 data_dict 执行以下基于 patch 的转换
transformA 对 data_dict 中 ‘img’ 字段的强度进行归一化。
transformB 从 data_dict 的 ‘img’ 和 ‘seg’ 中裁剪出图像 patch,并返回包含三个 patch 样本的列表
{'img': 3x100x100 data, 'seg': 1x100x100 data, 'shape': (100, 100)} applying transformB ----------> [{'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)}, {'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)}, {'img': 3x20x20 data, 'seg': 1x20x20 data, 'shape': (20, 20)},]
transformC 然后随机旋转或翻转 transformB 返回的列表中每个字典项的 ‘img’ 和 ‘seg’。
如果用户调用了 set_determinism(),则组合的转换将设置相同的全局随机种子。
使用直通字典操作时,可以利用
monai.transforms.adaptors.adaptor包装不符合要求的转换。这种方法允许您使用来自其他不兼容库的转换,而只需最少的额外工作。注意
在许多情况下,Compose 不是创建预处理管线的最佳方式。预处理通常不是严格顺序的操作系列,当一组非顺序函数必须按顺序调用时,会产生很多复杂性。
示例:图像和标签 图像通常需要某种归一化,而标签不需要。然后通常通过随机旋转、翻转和变形来增强两者。Compose 可以与一系列转换一起使用,这些转换接受包含 ‘image’ 和 ‘label’ 条目的字典。这可能需要在将 torchvision 转换传递给 Compose 之前对其进行包装。或者,可以创建一个具有 __call__ 函数的类,该函数调用您的预处理函数,同时考虑到并非所有函数都应用于标签。
延迟重采样
延迟重采样是 1.2 版本中引入的一项实验性功能。其目的是减少执行转换管线时必须执行的重采样操作数量。这可以显著提高管线的执行速度和内存使用性能,还可以显著减少连续执行多个空间重采样时发生的信息丢失。
延迟重采样可以通过
lazy参数启用或禁用,可以在初始化时指定,也可以在调用时覆盖。False(默认):不执行任何延迟重采样
None:根据转换实例的 ‘lazy’ 属性执行延迟重采样。
True:如果可能,总是执行延迟重采样。这将忽略转换实例的
lazy属性。
请参阅 延迟重采样主题 了解此功能的更多详细信息和使用示例。
- 参数:
transforms – 可调用对象的序列。
map_items – 如果输入 data 是列表或元组,是否将转换应用于其中的每个项。默认为 True。
unpack_items – 是否将输入 data 使用 * 解包作为转换的可调用函数的参数。默认为 False。
log_stats – 这个可选参数允许您按名称指定一个日志记录器来记录管线执行情况。将其设置为 False 会禁用日志记录。将其设置为 True 会启用向默认日志记录器记录日志。设置一个字符串会覆盖执行日志记录的日志记录器名称。
lazy – 是否为延迟转换启用 延迟重采样。如果为 False,转换将逐个执行。如果为 True,所有延迟转换将通过累积更改并尽可能少地重采样来执行。如果 lazy 为 None,Compose 将对其 lazy 属性设置为 True 的延迟转换执行延迟计算。
overrides – 这个可选参数允许您指定一个参数字典,在执行管线时应该覆盖这些参数。然后将与给定转换兼容的每个参数应用于该转换,之后再执行它。请注意,当前只有在为管线或给定转换启用 延迟重采样 时,覆盖参数才会生效。如果 lazy 为 False,它们将被忽略。当前支持的参数有:{
"mode","padding_mode","dtype","align_corners","resample_mode",device}。
- flatten()[source]#
返回一个包含简单转换列表的 Composition,而不是任何嵌套的 Compositions。
例如,t1 = Compose([x, x, x, x, Compose([Compose([x, x]), x, x])]).flatten() 将得到等同于 t1 = Compose([x, x, x, x, x, x, x, x]) 的结果。
- get_index_of_first(predicate)[source]#
get_index_of_first 接受一个
predicate,并返回满足该谓词(即使谓词返回 True)的第一个转换的索引。如果找不到满足predicate的转换,则返回 None。示例
c = Compose([Flip(…), Rotate90(…), Zoom(…), RandRotate(…), Resize(…)])
print(c.get_index_of_first(lambda t: isinstance(t, RandomTrait))) >>> 3 print(c.get_index_of_first(lambda t: isinstance(t, Compose))) >>> None
注意
这仅对该实例直接持有的转换执行。如果此实例包含嵌套的
Compose转换或其他包含转换的转换,则不会迭代到它们内部。- 参数:
predicate – 接受单个参数并返回布尔值的可调用对象。调用时
compose (传递的是此 Compose 包含的转换序列中的一个转换)
实例。
- 返回值:
序列中第一个转换的索引,对于该转换,
predicate返回 True。如果没有转换满足predicate,则为 None
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
InvertibleTransform#
- class monai.transforms.InvertibleTransform[source]#
可逆转换的类。
此类的存在是为了实现
invert方法。这使得图像在训练和推理过程中可以被裁剪、旋转、填充等,之后在保存到文件之前可以恢复到原始大小,以便在外部查看器中进行比较。调用
inverse方法时逆操作会单独应用于每个键,这允许为每个标签传递不同的参数(例如,图像和标签使用不同的插值)。
逆转换以 LIFO(后进先出)顺序应用。随着逆操作的应用,其条目会从详细说明已应用转换的列表中移除。也就是说,在前向传播期间,已应用转换的列表会增长,而在逆操作期间,它会缩减回空列表。
我们当前检查转换的
id()在前向和逆向方向上是相同的。这是一个有用的检查,用于确保逆操作按正确顺序处理。致开发者:将转换转换为可逆转换时,您需要
从此类继承。
在
__call__中,添加对push_transform的调用。逆操作可能需要的任何额外信息可以包含在字典
extra_info中。无论do_transform是 True 还是 False,此字典应具有相同的键,并且只能包含 pytorch 数据加载器的 collate 函数接受的对象(例如,不允许 None)。实现
inverse方法。确保执行逆操作后,调用pop_transform。
TraceableTransform#
- class monai.transforms.TraceableTransform[source]#
维护一个应用于数据的转换堆栈。
- 数据可以是以下两种类型之一
一个 MetaTensor(这是首选数据类型)。
- 一个包含数组/张量和辅助元数据的数据字典。在此
情况下,必须提供一个键(这种基于字典的方法已弃用)。
如果 data 是 MetaTensor 类型,则应用的转换将添加到
data.applied_operations中。- 如果 data 是一个字典,则可能发生以下两种情况之一
如果 data[key] 是一个 MetaTensor,则应用的转换将添加到
data[key].applied_operations中。- 否则,应用的转换将使用以下方法附加到相邻列表中
trace_key。例如,如果键是 image,则转换将附加到 image_transforms 中(这种基于字典的方法已弃用)。
- 希望很清楚,共有三种可能性
data 是 MetaTensor
data 是字典,data[key] 是 MetaTensor
data 是字典,data[key] 不是 MetaTensor(这种方法已弃用)。
必须实现此转换类的
__call__方法,以便在数据转换期间存储转换信息。已应用转换堆栈中的信息必须与默认的 collate 函数兼容,只存储字符串、数字和数组。
可以通过 self.set_tracing 或在初始化类时设置 MONAI_TRACE_TRANSFORM 来启用 tracing。
- get_most_recent_transform(data, key=None, check=True, pop=False)[source]#
获取堆栈中最近的转换。
- 参数:
data – 数据字典或 MetaTensor。
key (
Optional[Hashable]) – 如果 data 是一个字典,则 data[key] 将被修改。check (
bool) – 如果为 True,检查 self 是否与最近应用的转换类型相同。pop (
bool) – 如果为 True,在返回转换时将其移除。
- 返回值:
最近应用的转换的字典
- 抛出异常:
- RuntimeError – data 既不是 MetaTensor 也不是字典
- pop_transform(data, key=None, check=True)[source]#
返回并弹出最近的转换。
- 参数:
data – 数据字典或 MetaTensor
key (
Optional[Hashable]) – 如果 data 是一个字典,则 data[key] 将被修改check (
bool) – 如果为 True,检查 self 是否与最近应用的转换类型相同。
- 返回值:
最近应用的转换的字典
- 抛出异常:
- RuntimeError – data 既不是 MetaTensor 也不是字典
- push_transform(data, *args, **kwargs)[source]#
将应用于
data的转换推入堆栈。- 参数:
data – 数据字典或 MetaTensor。
args – track_transform_meta 的额外位置参数。
kwargs – 传递给 track_transform_meta 的额外关键字参数,设置
replace=True(默认为 False)以根据self.get_transform_info()重写 applied_operation/pending_operation 中最后的变换信息。
- trace_transform(to_trace)#
使用上下文管理器临时设置变换的跟踪状态。
- classmethod track_transform_meta(data, key=None, sp_size=None, affine=None, extra_info=None, orig_size=None, transform_info=None, lazy=False)[source]#
更新
data的已应用/待处理变换元数据的堆栈。- 参数:
data – 数据字典或 MetaTensor。
key – 如果 data 是字典,则修改 data[key]。
sp_size – 应用变换时预期的输出空间大小。它可以是 tensor 或 numpy,但会转换为整数列表。
affine – 变换在图像空间中的仿射表示(空间变换)。应用变换时,meta_tensor.affine 将更新为
meta_tensor.affine @ affine。extra_info – 如果需要,可以这个字典中存储与已应用变换相关的任何额外信息。计算逆变换时通常需要这些信息。
orig_size – 有时在逆变换过程中,了解原始图像的大小很有用,可以在此处提供。
transform_info – 来自 self.get_transform_info() 的信息。
lazy – 是否将变换推送到 pending_operations 或 applied_operations。
- 返回值:
为了向后兼容,如果
data是字典,则返回更新了data[key]的字典。否则,此函数返回更新了变换元数据的 MetaObj。
BatchInverseTransform#
- class monai.transforms.BatchInverseTransform(transform, loader, collate_fn=<function no_collation>, num_workers=0, detach=True, pad_batch=True, fill_value=None)[source]#
对一批数据执行逆变换。如果您已经推理了一批图像并希望对它们全部进行逆变换,这将非常有用。
- __init__(transform, loader, collate_fn=<function no_collation>, num_workers=0, detach=True, pad_batch=True, fill_value=None)[source]#
- 参数:
transform – 可对输入数据执行操作的数据变换。
loader – 用于运行 transforms 并生成一批数据的数据加载器。
collate_fn – 逆变换后如何整理数据。默认不执行任何整理,因此输出将是大小为批次大小的列表。
num_workers – 运行数据加载器进行逆变换时的 worker 数量,默认为 0,因为只运行 1 次迭代,多进程可能更慢。如果变换非常慢,可以设置 num_workers 进行多进程处理。如果设置为 None,则使用变换数据加载器的 num_workers。
detach – 是否分离 tensors。标量 tensors 将分离为数字类型而不是 torch tensors。
pad_batch – 当批次中的项指示不同的批次大小时,是否将所有序列填充到最长的序列。如果为 False,批次大小将是最短序列的长度。
fill_value – 当 pad_batch=True 时用于填充序列的值。
Decollated#
- class monai.transforms.Decollated(keys=None, detach=True, pad_batch=True, fill_value=None, allow_missing_keys=False)[source]#
解包一批数据。如果输入是字典,它还支持仅解包指定的键。请注意,与大多数 MapTransforms 不同,它会删除未指定的其他键。如果 keys=None,它将解包输入中的所有数据。它将标量值复制到解包列表的每个项中。
- 参数:
keys – 要解包的相应项的键,请注意它将删除未指定的其他键。如果为 None,将解包所有键。另请参阅:
monai.transforms.compose.MapTransform。detach – 是否分离 tensors。标量 tensors 将分离为数字类型而不是 torch tensors。
pad_batch – 当批次中的项指示不同的批次大小时,是否将所有序列填充到最长的序列。如果为 False,批次大小将是最短序列的长度。
fill_value – 当 pad_batch=True 时用于填充序列的值。
allow_missing_keys – 如果键丢失,则不引发异常。
OneOf#
- class monai.transforms.OneOf(transforms=None, weights=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
OneOf提供了从一组可调用对象中随机选择一个变换的能力,每个变换具有预定义的概率。- 参数:
transforms – 可调用对象的序列。
weights – 与 transforms 中每个可调用对象对应的概率。概率会归一化,使其总和为一。
map_items – 如果输入 data 是列表或元组,是否将转换应用于其中的每个项。默认为 True。
unpack_items – 是否将输入 data 使用 * 解包作为转换的可调用函数的参数。默认为 False。
log_stats – 这个可选参数允许您按名称指定一个日志记录器来记录管线执行情况。将其设置为 False 会禁用日志记录。将其设置为 True 会启用向默认日志记录器记录日志。设置一个字符串会覆盖执行日志记录的日志记录器名称。
lazy – 是否为延迟转换启用 延迟重采样。如果为 False,转换将逐个执行。如果为 True,所有延迟转换将通过累积更改并尽可能少地重采样来执行。如果 lazy 为 None,Compose 将对其 lazy 属性设置为 True 的延迟转换执行延迟计算。
overrides – 这个可选参数允许您指定一个参数字典,在执行管线时应该覆盖这些参数。然后将与给定转换兼容的每个参数应用于该转换,之后再执行它。请注意,当前只有在为管线或给定转换启用 延迟重采样 时,覆盖参数才会生效。如果 lazy 为 False,它们将被忽略。当前支持的参数有:{
"mode","padding_mode","dtype","align_corners","resample_mode",device}。
RandomOrder#
- class monai.transforms.RandomOrder(transforms=None, map_items=True, unpack_items=False, log_stats=False, lazy=False, overrides=None)[source]#
RandomOrder提供了以随机顺序应用转换列表的能力。- 参数:
transforms – 可调用对象的序列。
map_items – 如果输入 data 是列表或元组,是否将转换应用于其中的每个项。默认为 True。
unpack_items – 是否将输入 data 使用 * 解包作为转换的可调用函数的参数。默认为 False。
log_stats – 这个可选参数允许您按名称指定一个日志记录器来记录管线执行情况。将其设置为 False 会禁用日志记录。将其设置为 True 会启用向默认日志记录器记录日志。设置一个字符串会覆盖执行日志记录的日志记录器名称。
lazy – 是否为延迟转换启用 延迟重采样。如果为 False,转换将逐个执行。如果为 True,所有延迟转换将通过累积更改并尽可能少地重采样来执行。如果 lazy 为 None,Compose 将对其 lazy 属性设置为 True 的延迟转换执行延迟计算。
overrides – 这个可选参数允许您指定一个参数字典,在执行管线时应该覆盖这些参数。然后将与给定转换兼容的每个参数应用于该转换,之后再执行它。请注意,当前只有在为管线或给定转换启用 延迟重采样 时,覆盖参数才会生效。如果 lazy 为 False,它们将被忽略。当前支持的参数有:{
"mode","padding_mode","dtype","align_corners","resample_mode",device}。
SomeOf#
- class monai.transforms.SomeOf(transforms=None, map_items=True, unpack_items=False, log_stats=False, num_transforms=None, replace=False, weights=None, lazy=False, overrides=None)[source]#
SomeOf在每次调用时采样不同的变换序列进行应用。它可以配置为在每次调用时采样固定数量或可变数量的变换。样本均匀抽取,或根据用户提供的变换权重抽取。当每次调用采样可变数量的变换时,要采样的变换数量将从用户提供的范围内均匀采样。
- 参数:
transforms – 可调用对象列表。
map_items – 如果输入 data 是列表或元组,是否对其中的每个项应用变换。默认为 True。
unpack_items – 是否使用 * 解包输入 data 作为变换可调用函数的参数。默认为 False。
log_stats – 这个可选参数允许您按名称指定一个日志记录器来记录管线执行情况。将其设置为 False 会禁用日志记录。将其设置为 True 会启用向默认日志记录器记录日志。设置一个字符串会覆盖执行日志记录的日志记录器名称。
num_transforms – 一个 2 元组、整数或 None。2 元组指定每次迭代采样的最小和最大(包含)变换数量。如果给定一个整数,上下限相等。None 将其设置为 len(transforms)。默认为 None。
replace – 是否有放回采样。默认为 False。
weights – 用于采样变换的权重。将被归一化为 1。默认:None (均匀)。
lazy – 是否为延迟转换启用 延迟重采样。如果为 False,转换将逐个执行。如果为 True,所有延迟转换将通过累积更改并尽可能少地重采样来执行。如果 lazy 为 None,Compose 将对其 lazy 属性设置为 True 的延迟转换执行延迟计算。
overrides – 这个可选参数允许您指定一个参数字典,在执行管线时应该覆盖这些参数。然后将与给定转换兼容的每个参数应用于该转换,之后再执行它。请注意,当前只有在为管线或给定转换启用 延迟重采样 时,覆盖参数才会生效。如果 lazy 为 False,它们将被忽略。当前支持的参数有:{
"mode","padding_mode","dtype","align_corners","resample_mode",device}。
函数式变换#
裁剪和填充(函数式)#
一组用于空间操作的“函数式”变换。
- monai.transforms.croppad.functional.crop_func(img, slices, lazy, transform_info)[source]#
对 MetaTensor 进行裁剪的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img (
Tensor) – 要变换的数据,假设 img 是通道优先的,并且裁剪不应用于通道维度。slices (
tuple[slice, …]) – 根据指定的 center & size、start & end 或 slices 计算的裁剪切片。lazy (
bool) – 指示操作是否应延迟执行的标志。transform_info (
dict) – 包含与已应用变换相关的有用信息的字典。
- 返回类型:
Tensor
- monai.transforms.croppad.functional.crop_or_pad_nd(img, translation_mat, spatial_size, mode, **kwargs)[source]#
使用平移矩阵和空间大小进行裁剪或填充。平移系数被四舍五入到最接近的整数。更通用的实现请参见
monai.transforms.SpatialResample。- 参数:
img (
Tensor) – 要变换的数据,假设 img 是通道优先的,并且填充不应用于通道维度。translation_mat – 应用于图像的平移矩阵。例如,由
monai.transforms.utils.create_translate()生成的平移矩阵。平移系数被四舍五入到最接近的整数。spatial_size (
tuple[int, …]) – 输出图像的空间大小。mode (
str) – 填充模式。kwargs – np.pad 或 torch.pad 函数的其他参数。
- monai.transforms.croppad.functional.pad_func(img, to_pad, transform_info, mode=constant, lazy=False, **kwargs)[source]#
对 MetaTensor 进行填充的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。使用 torch.nn.functional.pad,除非 mode 或 kwargs 在 torch 中不可用,此时将使用 np.pad。
- 参数:
img (
Tensor) – 要变换的数据,假设 img 是通道优先的,并且填充不应用于通道维度。to_pad (
tuple[tuple[int,int]]) – 每个维度要填充的数量 [(low_H, high_H), (low_W, high_W), …]。请注意,这包括通道维度。transform_info (
dict) – 包含与已应用变换相关的有用信息的字典。mode (
str) – 可用模式:(Numpy){"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch){"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy (
bool) – 指示操作是否应延迟执行的标志。transform_info – 包含与已应用变换相关的有用信息的字典。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回类型:
Tensor
- monai.transforms.croppad.functional.pad_nd(img, to_pad, mode=constant, **kwargs)[source]#
在每个维度上按给定数量填充 img。
使用 torch.nn.functional.pad,除非 mode 或 kwargs 在 torch 中不可用,此时将使用 np.pad。
- 参数:
img (~NdarrayTensor) – 要变换的数据,假设 img 是通道优先的,并且填充不应用于通道维度。
to_pad (
list[tuple[int,int]]) – 每个维度要填充的数量 [(low_H, high_H), (low_W, high_W), …]。默认为 self.to_pad。mode (
str) – 可用模式:(Numpy){"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch){"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlkwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回类型:
~NdarrayTensor
空间变换(函数式)#
一组用于空间操作的“函数式”变换。
- monai.transforms.spatial.functional.affine_func(img, affine, grid, resampler, sp_size, mode, padding_mode, do_resampling, image_only, lazy, transform_info)[source]#
仿射变换的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
affine – 要应用的仿射变换,可以是 3x3 或 4x4 矩阵。这应该针对体素空间空间中心 (
float(size - 1)/2) 进行定义。grid – 在非延迟模式下用于预计算网格以进行重采样。
resampler – 重采样函数,另请参阅:
monai.transforms.Resample。sp_size – 输出图像空间大小。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,并且该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldo_resampling – 是否进行重采样,这是一个标志,用于在更新元数据但跳过实际(可能很重)的重采样操作的用例。
image_only – 如果为 True,则仅返回图像体积,否则返回 (image, affine)。
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- monai.transforms.spatial.functional.flip(img, sp_axes, lazy, transform_info)[source]#
翻转的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
sp_axes – 沿其翻转的空间轴。如果为 None,将沿输入数组的所有轴翻转。如果轴为负数,则从最后一个轴计数到第一个轴。如果轴是整数元组,则沿元组中指定的所有轴执行翻转。
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- monai.transforms.spatial.functional.orientation(img, original_affine, spatial_ornt, lazy, transform_info)[source]#
根据 spatial_ornt 将输入图像的方向更改为指定的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
original_affine – 输入图像的原始仿射矩阵。
spatial_ornt – 空间轴的方向,另请参阅 https://nipy.org/nibabel/reference/nibabel.orientations.html
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- 返回类型:
Tensor
- monai.transforms.spatial.functional.resize(img, out_size, mode, align_corners, dtype, input_ndim, anti_aliasing, anti_aliasing_sigma, lazy, transform_info)[source]#
调整大小的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
out_size – 调整大小操作后预期的空间维度形状。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – 这仅在 mode 为 ‘linear’、‘bilinear’、‘bicubic’ 或 ‘trilinear’ 时有效。
dtype – 重采样计算的数据类型。如果为 None,使用输入数据的数据类型。
input_ndim – 空间维度数量。
anti_aliasing – 在下采样之前是否应用高斯滤波器平滑图像。在对图像进行下采样以避免混叠伪影时,进行滤波至关重要。另请参阅
skimage.transform.resizeanti_aliasing_sigma – {float, tuple of floats},可选。用于抗锯齿时的高斯滤波标准差。
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- monai.transforms.spatial.functional.rotate(img, angle, output_shape, mode, padding_mode, align_corners, dtype, lazy, transform_info)[source]#
旋转的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
angle – 旋转角度(弧度)。对于 2D 应为 float,对于 3D 应为三个 floats。
output_shape – 旋转后数据的输出形状。
mode – {
"bilinear","nearest"} 插值模式,用于计算输出值。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 重采样计算的数据类型。如果为 None,使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为
float32。lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- monai.transforms.spatial.functional.rotate90(img, axes, k, lazy, transform_info)[source]#
旋转 90 度的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
axes – 2 个整数,定义了与 2 个空间轴一起旋转的平面。如果轴为负数,则从最后一个轴计数到第一个轴。
k – 旋转 90 度的次数。
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- monai.transforms.spatial.functional.spatial_resample(img, dst_affine, spatial_size, mode, padding_mode, align_corners, dtype_pt, lazy, transform_info)[source]#
将输入图像重新采样到指定的
dst_affine矩阵和spatial_size的函数式实现。此函数根据lazy(默认为False)急切或延迟执行。- 参数:
img – 要重新采样的数据,假设 img 是通道优先的。
dst_affine – 目标仿射矩阵,如果为 None,使用输入仿射矩阵,实际上不进行重采样。
spatial_size – 输出空间大小,如果分量为
-1,使用相应的输入空间大小。mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,并且该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – 在几何上,我们将输入的像素视为正方形而不是点。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype_pt – 重采样计算的数据 dtype。
lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
- 返回类型:
Tensor
- monai.transforms.spatial.functional.zoom(img, scale_factor, keep_size, mode, padding_mode, align_corners, dtype, lazy, transform_info)[source]#
缩放的函数式实现。此函数根据
lazy(默认为False)急切或延迟执行。- 参数:
img – 要更改的数据,假设 img 是通道优先的。
scale_factor – 沿空间轴的缩放因子。如果是一个 float,则每个空间轴的缩放相同。如果是一个序列,则缩放应包含每个空间轴一个值。
keep_size – 是否保持原始大小(如果需要进行填充/切片)。
mode – {
"bilinear","nearest"} 插值模式,用于计算输出值。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 重采样计算的数据类型。如果为 None,使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为
float32。lazy – 指示操作是否应延迟执行的标志
transform_info – 包含与已应用变换相关的有用信息的字典。
普通变换#
裁剪和填充#
PadListDataCollate#
- class monai.transforms.PadListDataCollate(method=symmetric, mode=constant, **kwargs)[source]#
与 MONAI 的
list_data_collate相同,不同之处在于任何 tensors 都被中心填充以匹配每个维度中最大 tensor 的形状。如果某些应用的变换生成了不同大小的批次数据,此变换很有用。这可用于列表和字典数据。请注意,对于字典数据,如果输入批次具有不同的空间形状,它可能会将变换信息添加到可逆变换列表中,因此需要先调用静态方法:inverse,然后再对其他变换进行逆变换。
请注意,通常用户不会显式使用 __call__ 方法。相反,它会传递给 DataLoader。这意味着 __call__ 处理从 DataLoader 中取出的数据,其中包含批次维度。然而,inverse 对包含形状为 C,H,W,[D] 的图像的字典进行操作。这种不对称性是必要的,以便我们可以通过多进程传递逆变换。
- 参数:
method (
str) – 填充方法(参见monai.transforms.SpatialPad)mode (
str) – 填充模式(参见monai.transforms.SpatialPad)kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
Pad#
- class monai.transforms.Pad(to_pad=None, mode=constant, lazy=False, **kwargs)[source]#
在每个维度上按给定数量执行填充。
使用 torch.nn.functional.pad,除非 mode 或 kwargs 在 torch 中不可用,此时将使用 np.pad。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
to_pad – 每个维度(包括通道)的填充量 [(low_H, high_H), (low_W, high_W), …]。如果为 None,必须在运行时在 __call__ 中提供。
mode – 可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch){"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 需要 pytorch >= 1.10 以获得最佳兼容性。lazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- __call__(img, to_pad=None, mode=None, lazy=None, **kwargs)[source]#
- 参数:
对 img 应用变换,假设 img 是通道优先的,并且填充不应用于通道维度。
to_pad – 每个维度要填充的数量 [(low_H, high_H), (low_W, high_W), …]。默认为 self.to_pad。
mode – 可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} (PyTorch){"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy – 一个标志,用于覆盖此调用的延迟行为(如果设置)。默认为 None。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- compute_pad_width(spatial_shape)[source]#
根据空间形状动态计算填充宽度。输出是包括通道在内的所有维度的填充量。
- 参数:
spatial_shape (
Sequence[int]) – 原始图像的空间形状。- 返回类型:
tuple[tuple[int,int]]
SpatialPad#
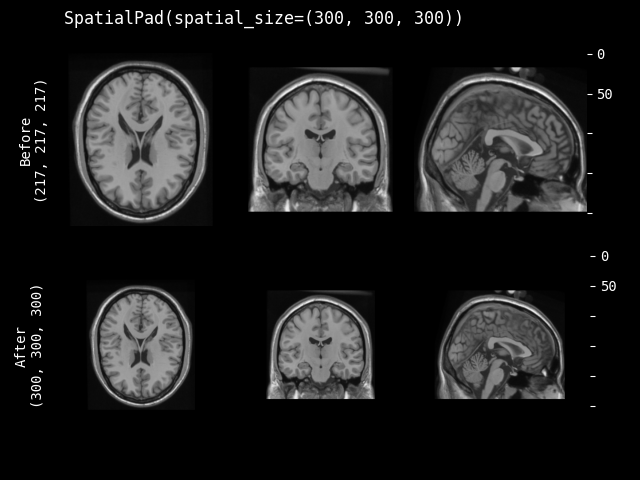
- class monai.transforms.SpatialPad(spatial_size, method=symmetric, mode=constant, lazy=False, **kwargs)[source]#
对数据执行填充,可以在所有边或每维只在一侧对称填充。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 填充后输出数据的空间大小,如果输入数据某个维度的大小大于填充大小,则该维度不进行填充。如果其分量具有非正值,则使用输入图像的相应大小(不进行填充)。例如:如果输入数据的空间大小是 [30, 30, 30],并且 spatial_size=[32, 25, -1],则输出数据的空间大小将是 [32, 30, 30]。
method – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
BorderPad#
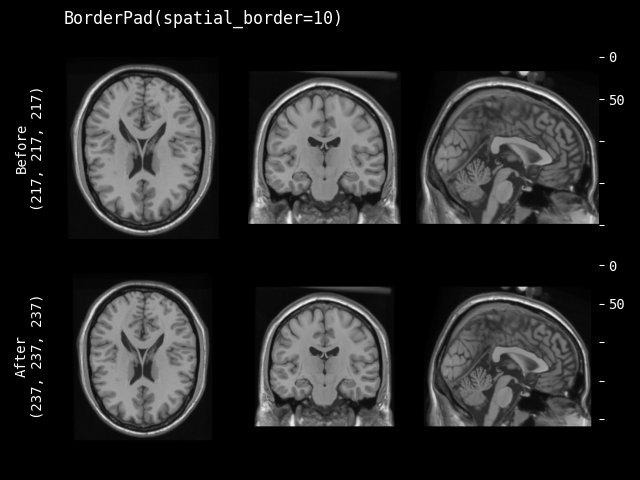
- class monai.transforms.BorderPad(spatial_border, mode=constant, lazy=False, **kwargs)[source]#
通过在每个维度上添加指定的边界来填充输入数据。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_border –
每个空间边界的指定大小。任何负值将被设置为 0。它可以是 3 种形状
单个整数,所有边界都填充相同的尺寸。
长度等于图像形状的长度,每个空间维度单独填充。例如,图像形状(CHW)是 [1, 4, 4],spatial_border 是 [2, 1],H 维度的每个边界填充 2,W 维度的每个边界填充 1,结果形状是 [1, 8, 6]。
长度等于图像形状长度的 2 倍,每个维度的每个边界单独填充。例如,图像形状(CHW)是 [1, 4, 4],spatial_border 是 [1, 2, 3, 4],H 维度的顶部填充 1,H 维度的底部填充 2,W 维度的左侧填充 3,W 维度的右侧填充 4。结果形状是 [1, 7, 11]。
mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
DivisiblePad#
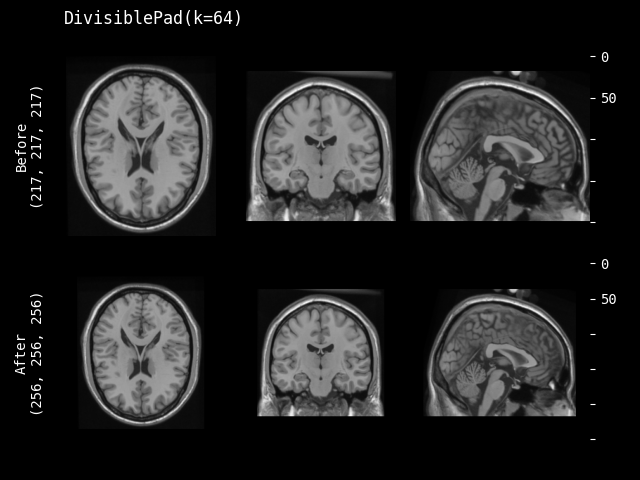
- class monai.transforms.DivisiblePad(k, mode=constant, method=symmetric, lazy=False, **kwargs)[source]#
填充输入数据,使其空间大小能被 k 整除。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(k, mode=constant, method=symmetric, lazy=False, **kwargs)[source]#
- 参数:
k – 每个空间维度的目标 k。如果 k 为负或 0,则保留原始大小。如果 k 是整数,则相同的 k 将应用于所有输入空间维度。
mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlmethod – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。lazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
Crop#
- class monai.transforms.Crop(lazy=False)[source]#
对输入图像执行裁剪操作。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
lazy (
bool) – 指示此变换是否应延迟执行的标志。默认为 False。
- static compute_slices(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None)[source]#
根据指定的 center & size、start & end 或 slices 计算裁剪切片。
- 参数:
roi_center – 裁剪 ROI 中心的体素坐标。
roi_size – 裁剪 ROI 的大小,如果 ROI 大小的某个维度大于图像大小,则该维度不进行裁剪。
roi_start – 裁剪 ROI 起始的体素坐标。
roi_end – 裁剪 ROI 结束的体素坐标,如果某个坐标超出图像范围,则使用图像的结束坐标。
roi_slices – 每个空间维度的切片列表。
SpatialCrop#
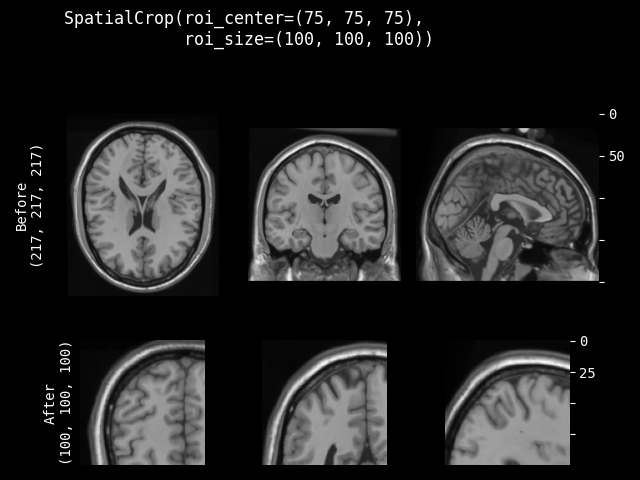
- class monai.transforms.SpatialCrop(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, lazy=False)[源代码]#
通用裁剪器,用于生成感兴趣区域(ROI)的子体素区域。如果预期的 ROI 大小的某个维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。它支持裁剪 ND 空间(通道优先)数据。
- 裁剪区域可以通过多种方式进行参数化
每个空间维度的切片列表(允许使用负索引和 None)
空间中心和大小
ROI 的起始和结束坐标
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, lazy=False)[源代码]#
- 参数:
roi_center – 裁剪 ROI 中心的体素坐标。
roi_size – 裁剪 ROI 的大小,如果 ROI 大小的某个维度大于图像大小,则该维度不进行裁剪。
roi_start – 裁剪 ROI 起始的体素坐标。
roi_end – 裁剪 ROI 结束的体素坐标,如果某个坐标超出图像范围,则使用图像的结束坐标。
roi_slices – 每个空间维度的切片列表。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
CenterSpatialCrop#
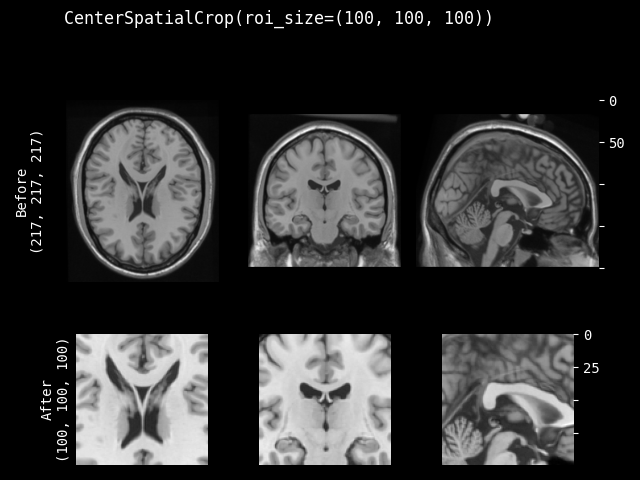
- class monai.transforms.CenterSpatialCrop(roi_size, lazy=False)[源代码]#
在图像中心以指定的 ROI 大小进行裁剪。如果预期的 ROI 大小的某个维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
roi_size – 裁剪区域的空间大小,例如 [224,224,128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
RandSpatialCrop#
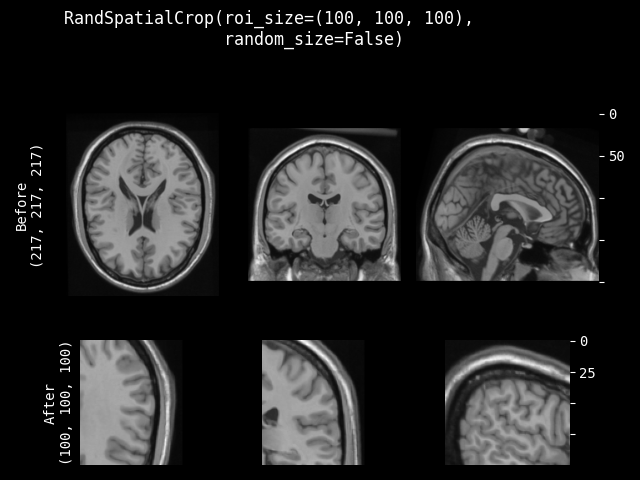
- class monai.transforms.RandSpatialCrop(roi_size, max_roi_size=None, random_center=True, random_size=False, lazy=False)[源代码]#
以随机大小或特定大小的 ROI 裁剪图像。它可以在随机位置作为中心进行裁剪,也可以在图像中心进行裁剪。并且允许设置最小和最大大小来限制随机生成的 ROI。
注意:即使 random_size=False,如果预期的 ROI 大小的某个维度大于输入图像大小,也不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
roi_size – 如果 random_size 为 True,则指定最小裁剪区域。如果 random_size 为 False,则指定要裁剪的预期 ROI 大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
max_roi_size – 如果 random_size 为 True 且 roi_size 指定了最小裁剪区域大小,则 max_roi_size 可以指定最大裁剪区域大小。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用输入图像的相应大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 以随机大小或特定大小的 ROI 进行裁剪。如果为 True,实际大小将从 randint(roi_size, max_roi_size + 1) 中采样。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
RandSpatialCropSamples#
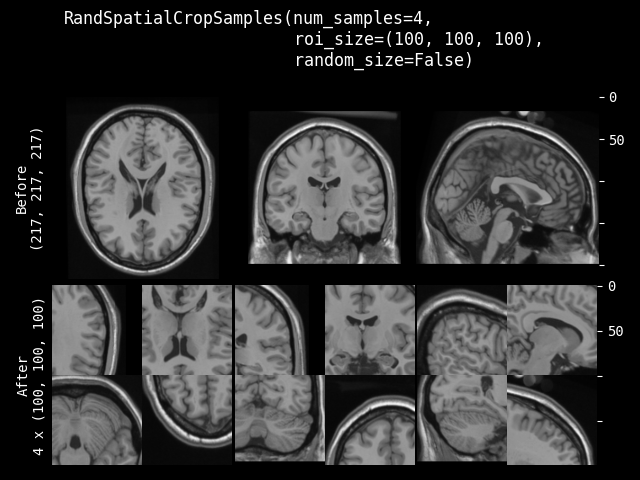
- class monai.transforms.RandSpatialCropSamples(roi_size, num_samples, max_roi_size=None, random_center=True, random_size=False, lazy=False)[源代码]#
以随机大小或特定大小的 ROI 裁剪图像,以生成包含 N 个样本的列表。它可以在随机位置作为中心进行裁剪,也可以在图像中心进行裁剪。并且允许设置最小大小来限制随机生成的 ROI。它将返回一个裁剪图像的列表。
注意:即使 random_size=False,如果预期的 ROI 大小的某个维度大于输入图像大小,也不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
roi_size – 如果 random_size 为 True,则指定最小裁剪区域。如果 random_size 为 False,则指定要裁剪的预期 ROI 大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
num_samples – 在返回列表中获取的样本(裁剪区域)数量。
max_roi_size – 如果 random_size 为 True 且 roi_size 指定了最小裁剪区域大小,则 max_roi_size 可以指定最大裁剪区域大小。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用输入图像的相应大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 以随机大小或特定大小的 ROI 进行裁剪。实际大小将从 randint(roi_size, img_size) 中采样。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- 抛出异常:
ValueError – 当
num_samples为非正数时。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
CropForeground#
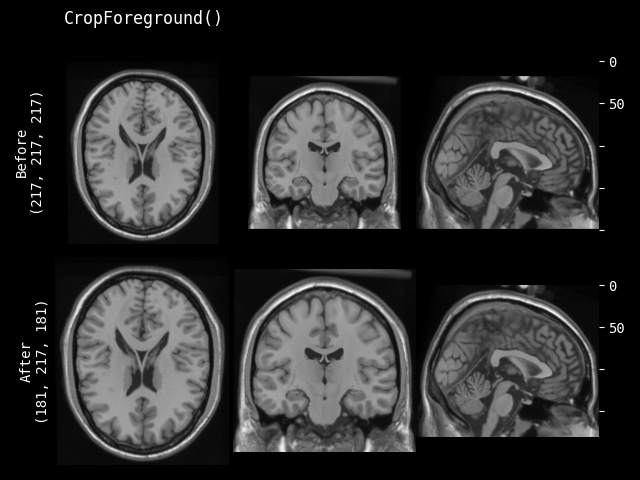
- class monai.transforms.CropForeground(select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, return_coords=False, k_divisible=1, mode=constant, lazy=False, **pad_kwargs)[源代码]#
使用边界框裁剪图像。边界框是通过在 `channel_indices` 通道中使用 `select_fn` 选择前景生成的。在边界框的每个空间维度中都会添加 `margin`。典型的用法是当整个医学图像中的有效部分很小时,帮助训练和评估。用户可以定义任意函数来从整个图像或指定通道中选择预期的前景。它还可以为前景对象的边界框的每个维度添加 `margin`。例如
image = np.array( [[[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 2, 0], [0, 1, 2, 1, 0], [0, 0, 0, 0, 0]]]) # 1x5x5, single channel 5x5 image def threshold_at_one(x): # threshold at 1 return x > 1 cropper = CropForeground(select_fn=threshold_at_one, margin=0) print(cropper(image)) [[[2, 1], [3, 2], [2, 1]]]
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, return_coords=False, k_divisible=1, mode=constant, lazy=False, **pad_kwargs)[源代码]#
- 参数:
select_fn – 用于选择预期前景的函数,默认选择大于 0 的值。
channel_indices – 如果已定义,则仅在图像的指定通道上选择前景。如果为 None,则在整个图像上选择前景。
margin – 向边界框的空间维度添加 margin 值,如果只提供一个值,则将其用于所有维度。
allow_smaller – 计算带 margin 的框大小时,是否允许图像边缘小于最终框边缘。如果为 False,则填充输出框的一部分可能超出原始图像;如果为 True,则将使用图像边缘作为框边缘。默认为 True。
return_coords – 是否返回前景的空间边界框坐标。
k_divisible – 使每个空间维度可被 k 整除,默认值为 1。如果 k_divisible 是一个整数,则相同的 k 将应用于所有输入空间维度。
mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy – 指示此变换是否应延迟执行的标志。默认为 False。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
RandWeightedCrop#
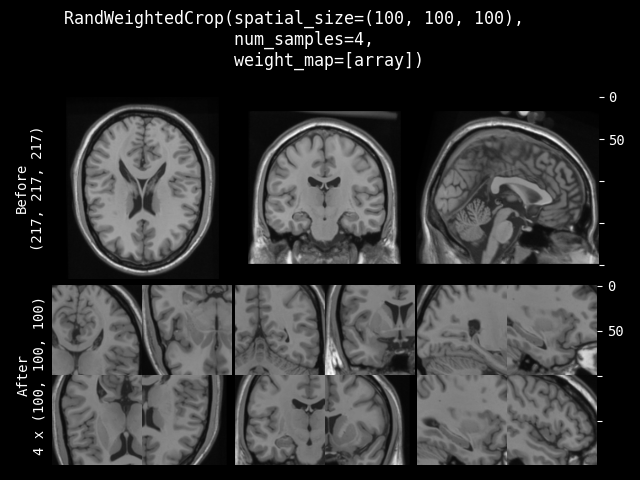
- class monai.transforms.RandWeightedCrop(spatial_size, num_samples=1, weight_map=None, lazy=False)[源代码]#
根据提供的 weight_map 采样 num_samples 个图像块。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 图像块的空间大小,例如 [224, 224, 128]。如果其分量包含非正值,则将使用 img 的相应大小。
num_samples – 在返回列表中获取的样本(图像块)数量。
weight_map – 用于生成图像块样本的权重图。权重必须是非负的。每个元素表示空间位置的采样权重。0 表示不进行采样。它应该是形状为单通道的数组,例如 (1, spatial_dim_0, spatial_dim_1, …)。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- __call__(img, weight_map=None, randomize=True, lazy=None)[源代码]#
- 参数:
img – 用于采样图像块的输入图像。假设 img 是一个通道优先的数组。
weight_map – 用于生成图像块样本的权重图。权重必须是非负的。每个元素表示空间位置的采样权重。0 表示不进行采样。它应该是一个形状为单通道的数组,例如 (1, spatial_dim_0, spatial_dim_1, …)
randomize – 是否执行随机操作,默认为 True。
lazy – 一个标志,用于覆盖此调用的延迟行为(如果设置)。默认为 None。
- 返回值:
图像块列表
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandCropByPosNegLabel#
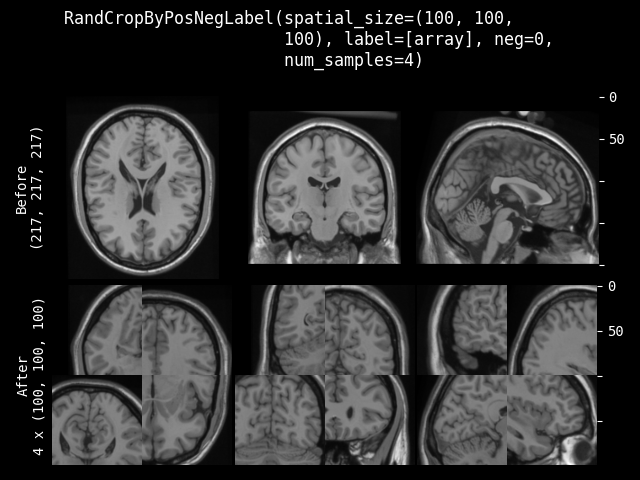
- class monai.transforms.RandCropByPosNegLabel(spatial_size, label=None, pos=1.0, neg=1.0, num_samples=1, image=None, image_threshold=0.0, fg_indices=None, bg_indices=None, allow_smaller=False, lazy=False)[源代码]#
根据 Pos Neg Ratio,随机裁剪固定大小的区域,中心可以是前景体素或背景体素。并将返回所有裁剪图像的数组列表。例如,从 (5 x 5) 数组中以 pos/neg=1 裁剪两个 (3 x 3) 数组。
[[[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [[0, 1, 2], [[2, 1, 0], [0, 1, 3, 0, 0], --> [0, 1, 3], [3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0]] [0, 0, 0]] [0, 0, 0, 0, 0]]]
如果预期的空间大小的某个维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期大小,并且多个图像的裁剪结果可能不具有完全相同的形状。如果裁剪 ROI 部分超出图像范围,将自动调整裁剪中心以确保有效的裁剪 ROI。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 裁剪区域的空间大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用 label 的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 spatial_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
label – 用于查找前景/背景的标签图像,如果为 None,则必须在 self.__call__ 中设置。非零值表示前景,零值表示背景。
pos – 与 neg 一起用于计算比率
pos / (pos + neg),该比率表示将前景体素选为中心的概率,而不是背景体素。neg – 与 pos 一起用于计算比率
pos / (pos + neg),该比率表示将前景体素选为中心的概率,而不是背景体素。num_samples – 在每个列表中获取的样本(裁剪区域)数量。
image – 可选的图像数据,用于帮助选择有效区域,可以与 img 相同,也可以是另一个图像数组。如果不为 None,则使用
label == 0 & image > image_threshold来选择负样本(背景)中心。因此,裁剪中心只会来自有效的图像区域。image_threshold – 如果启用了 image,则使用
image > image_threshold来确定有效的图像内容区域。fg_indices – 如果提供了预计算的 label 的前景索引,将忽略上述 image 和 image_threshold,并基于这些索引随机选择裁剪中心,需要同时提供 fg_indices 和 bg_indices,期望是展平后的 1 维空间索引数组。典型用法是首先调用 FgBgToIndices 变换并缓存结果。
bg_indices – 如果提供了预计算的 label 的背景索引,将忽略上述 image 和 image_threshold,并基于这些索引随机选择裁剪中心,需要同时提供 fg_indices 和 bg_indices,期望是展平后的 1 维空间索引数组。典型用法是首先调用 FgBgToIndices 变换并缓存结果。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- 抛出异常:
ValueError – 当
pos或neg为负数时。ValueError – 当
pos=0且neg=0时。值不兼容。
- __call__(img, label=None, image=None, fg_indices=None, bg_indices=None, randomize=True, lazy=None)[源代码]#
- 参数:
img – 根据 label 和 image 的 pos/neg 比率从中裁剪样本的输入数据。假设 img 是一个通道优先的数组。
label – 用于查找前景/背景的标签图像,如果为 None,则使用 self.label。
image – 可选的图像数据,用于帮助选择有效区域,可以与 img 相同,也可以是另一个图像数组。使用
label == 0 & image > image_threshold来选择负样本(背景)中心。因此,裁剪中心只会存在于有效的图像区域。如果为 None,则使用 self.image。fg_indices – 用于随机选择裁剪中心的前景索引,需要同时提供 fg_indices 和 bg_indices。
bg_indices – 用于随机选择裁剪中心的背景索引,需要同时提供 fg_indices 和 bg_indices。
randomize – 是否执行随机操作,默认为 True。
lazy – 一个标志,用于覆盖此调用的延迟行为(如果设置)。默认为 None。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- randomize(label=None, fg_indices=None, bg_indices=None, image=None)[源代码]#
在此方法中,应使用
self.R而非 np.random 来引入随机因素。所有
self.R调用都发生在此处,以便我们能更好地识别同步随机状态的错误。此方法可以根据输入数据的属性生成随机因素。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
RandCropByLabelClasses#
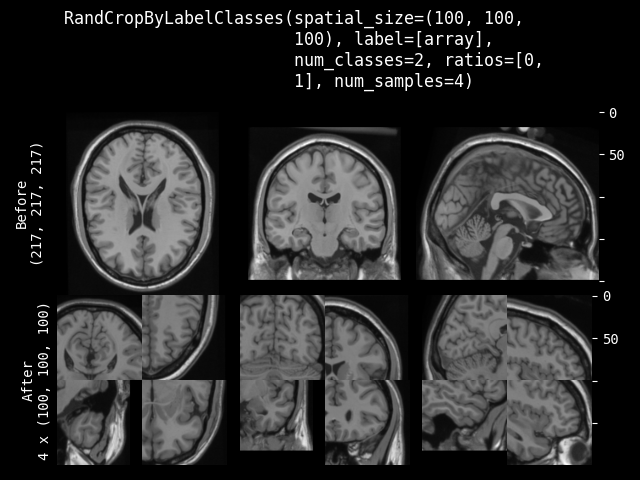
- class monai.transforms.RandCropByLabelClasses(spatial_size, ratios=None, label=None, num_classes=None, num_samples=1, image=None, image_threshold=0.0, indices=None, allow_smaller=False, warn=True, max_samples_per_class=None, lazy=False)[源代码]#
根据指定的每个类别的比率,随机裁剪固定大小的区域,中心属于某个类别。标签数据可以是 One-Hot 格式数组或 Argmax 数据。并将返回所有裁剪图像的数组列表。例如,从 (5 x 5) 数组中以 ratios=[1, 2, 3, 1] 裁剪两个 (3 x 3) 数组。
image = np.array([ [[0.0, 0.3, 0.4, 0.2, 0.0], [0.0, 0.1, 0.2, 0.1, 0.4], [0.0, 0.3, 0.5, 0.2, 0.0], [0.1, 0.2, 0.1, 0.1, 0.0], [0.0, 0.1, 0.2, 0.1, 0.0]] ]) label = np.array([ [[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]] ]) cropper = RandCropByLabelClasses( spatial_size=[3, 3], ratios=[1, 2, 3, 1], num_classes=4, num_samples=2, ) label_samples = cropper(img=label, label=label, image=image) The 2 randomly cropped samples of `label` can be: [[0, 1, 2], [[0, 0, 0], [0, 1, 3], [1, 2, 1], [0, 0, 0]] [1, 3, 0]]如果预期的空间大小的某个维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期大小,并且多个图像的裁剪结果可能不具有完全相同的形状。如果裁剪 ROI 部分超出图像范围,将自动调整裁剪中心以确保有效的裁剪 ROI。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 裁剪区域的空间大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用 label 的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 spatial_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
ratios – 指定标签中每个类别用于生成裁剪中心的比率,包括背景类别。如果为 None,则每个类别将具有相同的比率来生成裁剪中心。
label – 用于查找每个类别的标签图像,如果为 None,则必须在 self.__call__ 中设置。
num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
num_samples – 在每个列表中获取的样本(裁剪区域)数量。
image – 如果 image 不为 None,则仅返回图像有效区域(
image > image_threshold)内的每个类别的索引。image_threshold – 如果启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅在该区域中选择类别索引。indices – 如果提供了预计算的每个类别的索引,将忽略上述 image 和 image_threshold,并基于这些索引随机选择裁剪中心,期望是展平后的 1 维空间索引数组。典型用法是首先调用 ClassesToIndices 变换并缓存结果以获得更好的性能。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
warn – 如果为 True,则如果标签中不存在某个类别,则打印警告。
max_samples_per_class – 每个类别中要采样的索引的最大长度,以减少内存消耗。默认为 None,不进行子采样。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- __call__(img, label=None, image=None, indices=None, randomize=True, lazy=None)[源代码]#
- 参数:
img – 根据每个类别的比率从中裁剪样本的输入数据,假设 img 是一个通道优先的数组。
label – 用于查找每个类别索引的标签图像,如果为 None,则使用 self.label。
image – 可选的图像数据,用于帮助选择有效区域,可以与 img 相同,也可以是另一个图像数组。使用
image > image_threshold来仅在有效区域选择中心。如果为 None,则使用 self.image。indices – 图像中每个类别的索引列表,用于随机选择裁剪中心。
randomize – 是否执行随机操作,默认为 True。
lazy – 一个标志,用于覆盖此调用的延迟行为(如果设置)。默认为 None。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- randomize(label=None, indices=None, image=None)[源代码]#
在此方法中,应使用
self.R而非 np.random 来引入随机因素。所有
self.R调用都发生在此处,以便我们能更好地识别同步随机状态的错误。此方法可以根据输入数据的属性生成随机因素。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
ResizeWithPadOrCrop#
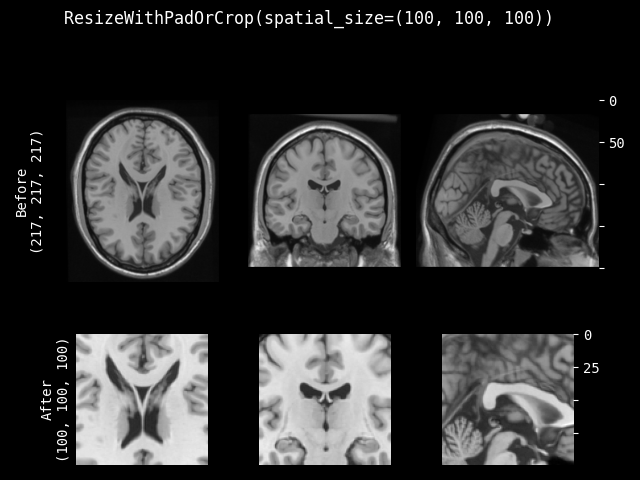
- class monai.transforms.ResizeWithPadOrCrop(spatial_size, method=symmetric, mode=constant, lazy=False, **pad_kwargs)[源代码]#
通过中心裁剪图像或使用用户指定模式均匀填充图像,将图像调整到目标空间大小。当维度小于目标大小时,沿该维度进行对称填充。当维度大于目标大小时,沿该维度进行中心裁剪。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 填充或裁剪后输出数据的空间大小。如果包含非正值,则将使用输入图像的相应大小(不进行填充)。
method – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlpad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- __call__(img, mode=None, lazy=None, **pad_kwargs)[源代码]#
- 参数:
img – 要填充或裁剪的数据,假设 img 是通道优先的,且填充或裁剪不应用于通道维度。
mode – numpy 数组可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmllazy – 一个标志,用于覆盖此调用的延迟行为(如果设置)。默认为 None。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
BoundingRect#
- class monai.transforms.BoundingRect(select_fn=<function is_positive>)[源代码]#
计算输入图像 img 的轴对齐边界矩形坐标。坐标的输出格式为(形状为 [channel, 2 * spatial dims])
- [[1st_spatial_dim_start, 1st_spatial_dim_end,
2nd_spatial_dim_start, 2nd_spatial_dim_end, …, Nth_spatial_dim_start, Nth_spatial_dim_end],
…
[1st_spatial_dim_start, 1st_spatial_dim_end, 2nd_spatial_dim_start, 2nd_spatial_dim_end, …, Nth_spatial_dim_start, Nth_spatial_dim_end]]
边界框的边缘与输入图像的边缘对齐。如果没有正强度值,此函数返回 [0, 0, …]。
- 参数:
select_fn (
Callable) – 用于选择预期前景的函数,默认选择大于 0 的值。
- __call__(img)[源代码]#
另请参阅:
monai.transforms.utils.generate_spatial_bounding_box.- 返回类型:
ndarray
RandScaleCrop#
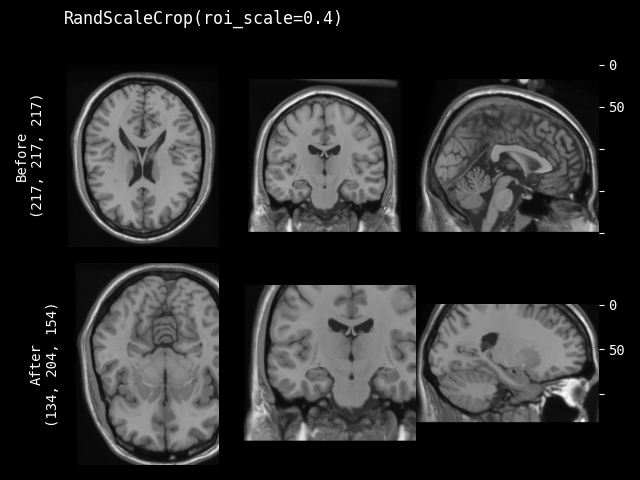
- class monai.transforms.RandScaleCrop(roi_scale, max_roi_scale=None, random_center=True, random_size=False, lazy=False)[源代码]#
monai.transforms.RandSpatialCrop的子类。以随机大小或特定大小的 ROI 裁剪图像。它可以在随机位置作为中心进行裁剪,也可以在图像中心进行裁剪。并且允许设置图像大小的最小和最大缩放比例来限制随机生成的 ROI。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
roi_scale – 如果 random_size 为 True,则指定最小裁剪大小:roi_scale * image spatial size。如果 random_size 为 False,则指定预期的图像大小缩放比例进行裁剪,例如 [0.3, 0.4, 0.5]。如果其分量包含非正值,则将使用 1.0 代替,表示输入图像大小。
max_roi_scale – 如果 random_size 为 True 且 roi_scale 指定了最小裁剪区域大小,则 max_roi_scale 可以指定最大裁剪区域大小:max_roi_scale * image spatial size。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用 1.0 代替,表示输入图像大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 以随机大小或由 roi_scale * image spatial size 指定的 ROI 大小进行裁剪。如果为 True,则实际大小将从 randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1) 中采样。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
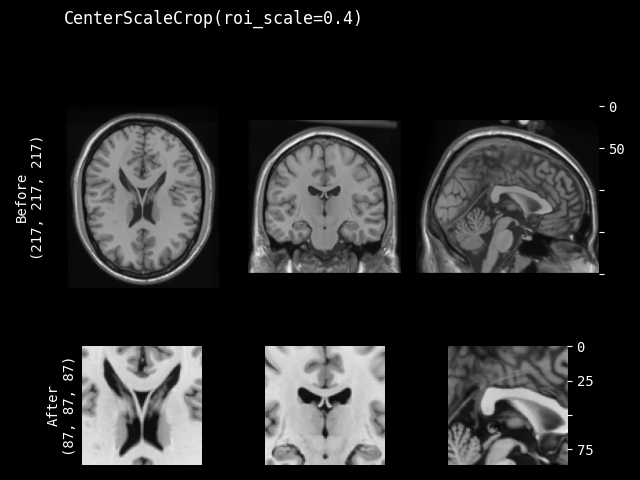
CenterScaleCrop#
强度#
RandGaussianNoise#
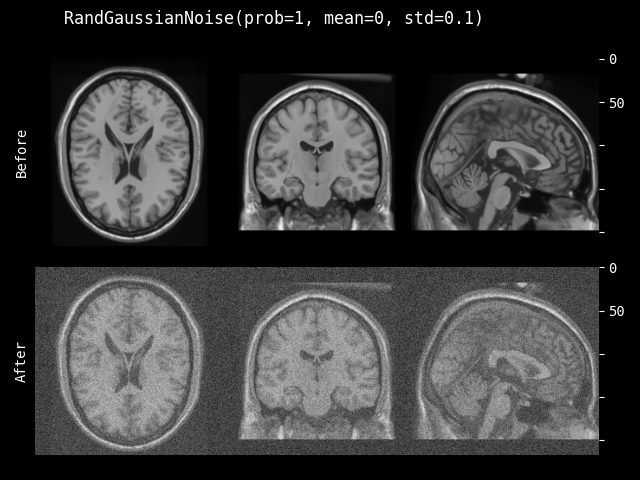
- class monai.transforms.RandGaussianNoise(prob=0.1, mean=0.0, std=0.1, dtype=<class 'numpy.float32'>, sample_std=True)[源代码]#
给图像添加高斯噪声。
- 参数:
prob (
float) – 添加高斯噪声的概率。mean (
float) – 分布的均值或“中心”。std (
float) – 分布的标准差(离散度)。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。sample_std (
bool) – 如果为 True,则从 0 到 std 均匀采样高斯分布的离散度。
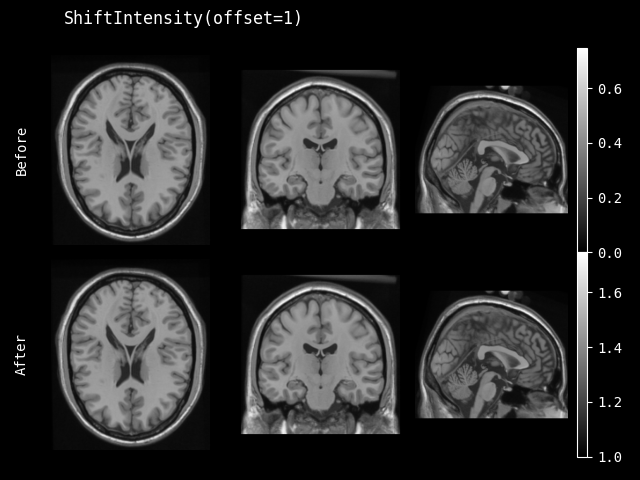
ShiftIntensity#
RandShiftIntensity#
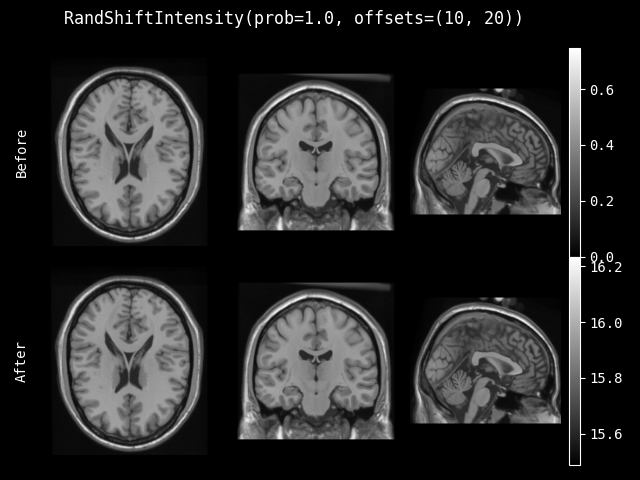
- class monai.transforms.RandShiftIntensity(offsets, safe=False, prob=0.1, channel_wise=False)[source]#
使用随机选择的偏移量随机调整强度。
- __call__(img, factor=None, randomize=True)[source]#
将变换应用于 img。
- 参数:
img – 输入图像以调整强度。
factor – 用于乘以随机偏移量然后进行调整的因子。在运行时可以是某些图像特定值,例如:max(img) 等。
- __init__(offsets, safe=False, prob=0.1, channel_wise=False)[source]#
- 参数:
offsets – 用于随机调整的偏移量范围。如果是一个数字,则偏移量值从 (-offsets, offsets) 中选取。
safe – 如果为 True,则在强度溢出时进行安全的数据类型转换。默认为 False。例如,[256, -12] -> [array(0), array(244)]。如果为 True,则 [256, -12] -> [array(255), array(0)]。
prob – 调整的概率。
channel_wise – 如果为 True,则对每个通道分别调整强度。对于每个通道,将选择一个随机偏移量。如果为 True,请确保第一个维度表示图像的通道。
StdShiftIntensity#
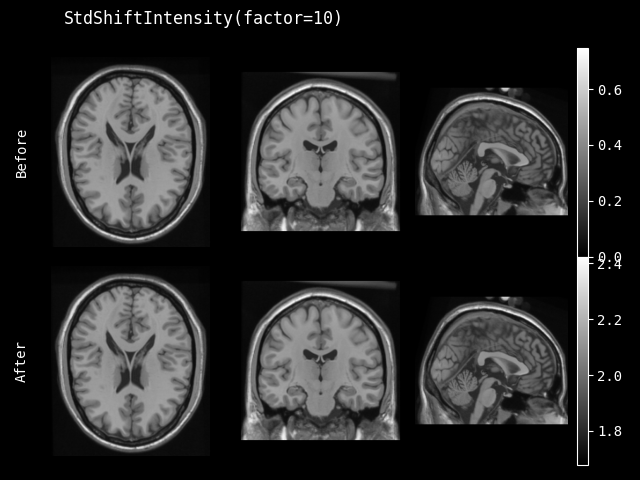
- class monai.transforms.StdShiftIntensity(factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
使用因子和图像的标准差来调整图像强度,调整方式为:
v = v + factor * std(v)。此转换可以只关注非零值或整个图像,也可以分别计算每个通道的标准差。- 参数:
factor (
float) – 按v = v + factor * std(v)调整的因子。nonzero (
bool) – 是否只计算非零值。channel_wise (
bool) – 如果为 True,则对每个通道分别计算。如果为 True,请确保第一个维度表示图像的通道。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
RandStdShiftIntensity#
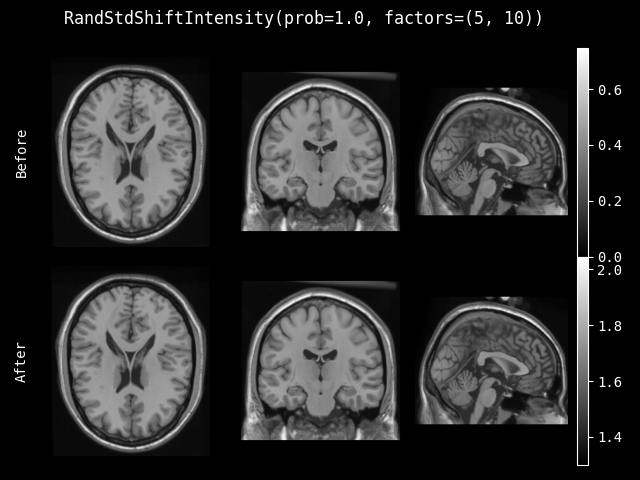
- class monai.transforms.RandStdShiftIntensity(factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
使用因子和图像的标准差来调整图像强度,调整方式为:
v = v + factor * std(v),其中 factor 是随机选取的。- __init__(factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
factors – 如果是元组,则随机选取范围为 (min(factors), max(factors))。如果是一个数字,则范围为 (-factors, factors)。
prob – 标准差调整的概率。
nonzero – 是否只计算非零值。
channel_wise – 如果为 True,则对每个通道分别计算。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
RandBiasField#
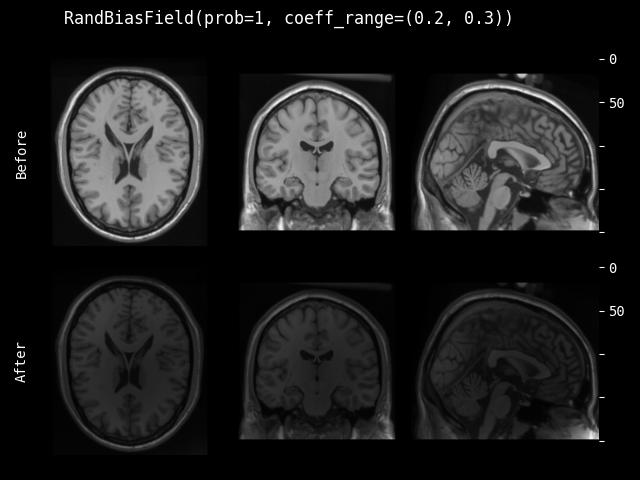
- class monai.transforms.RandBiasField(degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1)[source]#
针对 MR 图像的随机偏置场增强。偏置场被视为平滑变化的基(多项式)函数的线性组合,如 Automated Model-Based Tissue Classification of MR Images of the Brain 中所述。此实现改编自 NiftyNet。参考 Longitudinal segmentation of age-related white matter hyperintensities。
- 参数:
degree (
int) – 多项式的自由度。该值应不小于 1。默认为 3。coeff_range (
tuple[float,float]) – 随机系数的范围。默认为 (0.0, 0.1)。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。prob (
float) – 执行随机偏置场的概率。
ScaleIntensity#
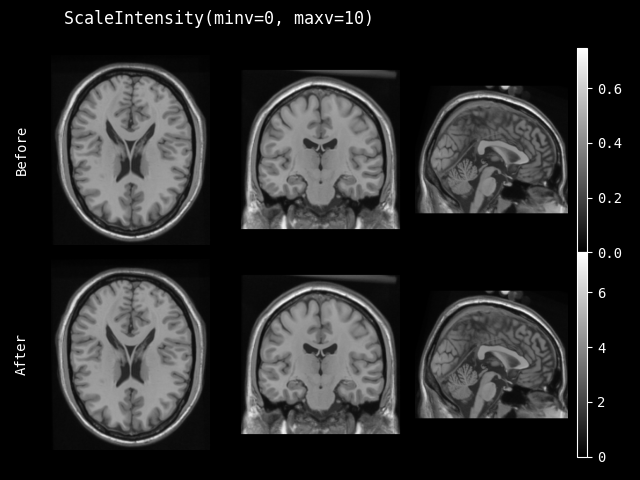
- class monai.transforms.ScaleIntensity(minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
将输入图像的强度缩放到给定的值范围 (minv, maxv)。如果未提供 minv 和 maxv,则使用 factor 按
v = v * (1 + factor)对图像进行缩放。- __call__(img)[source]#
将变换应用于 img。
- 抛出异常:
ValueError – 当
self.minv=None或self.maxv=None且self.factor=None时。值不兼容。- 返回类型:
Union[ndarray,Tensor]
- __init__(minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
minv – 输出数据的最小值。
maxv – 输出数据的最大值。
factor – 按
v = v * (1 + factor)进行缩放的因子。要使用此参数,请将 minv 和 maxv 都设置为 None。channel_wise – 如果为 True,则对每个通道分别进行缩放。如果为 True,请确保第一个维度表示图像的通道。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
ClipIntensityPercentiles#
- class monai.transforms.ClipIntensityPercentiles(lower, upper, sharpness_factor=None, channel_wise=False, return_clipping_values=False, dtype=<class 'numpy.float32'>)[source]#
根据输入图像的强度分布应用裁剪。如果提供了 sharpness_factor,强度值将根据 f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) 进行软裁剪。参考 https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291
软裁剪保留了值的顺序,并在任何地方保持了梯度。例如
image = torch.Tensor( [[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]]) # Hard clipping from lower and upper image intensity percentiles hard_clipper = ClipIntensityPercentiles(30, 70) print(hard_clipper(image)) metatensor([[[2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.], [2., 2., 3., 4., 4.]]]) # Soft clipping from lower and upper image intensity percentiles soft_clipper = ClipIntensityPercentiles(30, 70, 10.) print(soft_clipper(image)) metatensor([[[2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000], [2.0000, 2.0693, 3.0000, 3.9307, 4.0000]]])
- __init__(lower, upper, sharpness_factor=None, channel_wise=False, return_clipping_values=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
lower – 较低强度百分位数。在硬裁剪的情况下,None 的效果与 0 相同,即不裁剪最低输入值。然而,在软裁剪的情况下,None 和零会有两种不同的效果:None 将不对低值应用裁剪,而零仍将根据软裁剪变换转换较低值。更多详细信息请查看:https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291。
upper – 较高强度百分位数。与 lower 相同,但这次针对最高值。如果我们希望执行软裁剪,如果为 None,则这侧将没有效果,而如果设置为 100,则值将通过相应的裁剪方程传递。
sharpness_factor – 如果不为 None,强度值将根据 f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) 进行软裁剪。默认为 None。
channel_wise – 如果为 True,则分别计算每个通道的强度百分位数并进行归一化。默认为 False。
return_clipping_values – 是否在张量元信息中返回计算出的百分位数。如果进行软裁剪且请求的百分位数为 None,则在元信息中返回 None 作为相应的裁剪值。如果 channel_wise 设置为 True,裁剪值将存储在一个列表中,其中每个元素对应一个通道。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
RandScaleIntensity#
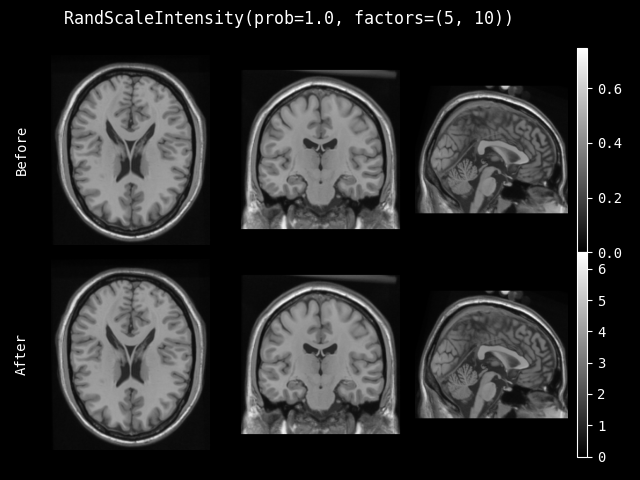
- class monai.transforms.RandScaleIntensity(factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
随机缩放输入图像的强度,缩放方式为
v = v * (1 + factor),其中 factor 是随机选取的。- __init__(factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
factors – 用于随机缩放的因子范围,缩放方式为
v = v * (1 + factor)。如果是一个数字,因子值从 (-factors, factors) 中选取。prob – 缩放的概率。
channel_wise – 如果为 True,则对每个通道分别进行缩放。如果为 True,请确保第一个维度表示图像的通道。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
ScaleIntensityFixedMean#
- class monai.transforms.ScaleIntensityFixedMean(factor=0, preserve_range=False, fixed_mean=True, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
通过
v = v * (1 + factor)缩放输入图像的强度,然后平移输出,使输出图像与输入图像具有相同的均值。- __call__(img, factor=None)[source]#
将变换应用于 img。:type img:
Union[ndarray,Tensor] :param img: 输入张量/数组 :param factor: 按v = v * (1 + factor)缩放的因子- 返回类型:
Union[ndarray,Tensor]
- __init__(factor=0, preserve_range=False, fixed_mean=True, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
factor (
float) – 按v = v * (1 + factor)缩放的因子。preserve_range (
bool) – 将输出数组/张量裁剪到输入数组/张量的范围。fixed_mean (
bool) – 在使用 factor 缩放之前减去平均强度,然后在缩放之后加上相同的值,以确保输出与输入具有相同的均值。channel_wise (
bool) – 如果为 True,则对每个通道分别进行缩放。如果 channel_wise 为 True,preserve_range 和 fixed_mean 也将分别应用于每个通道。如果为 True,请确保第一个维度表示图像的通道。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
RandScaleIntensityFixedMean#
- class monai.transforms.RandScaleIntensityFixedMean(prob=0.1, factors=0, fixed_mean=True, preserve_range=False, dtype=<class 'numpy.float32'>)[source]#
通过
v = v * (1 + factor)随机缩放输入图像的强度,其中 factor 是随机选取的。在使用 factor 缩放之前减去平均强度,然后在缩放之后加上相同的值,以确保输出与输入具有相同的均值。- __init__(prob=0.1, factors=0, fixed_mean=True, preserve_range=False, dtype=<class 'numpy.float32'>)[source]#
- 参数:
factors – 用于随机缩放的因子范围,缩放方式为
v = v * (1 + factor)。如果是一个数字,因子值从 (-factors, factors) 中选取。preserve_range – 将输出数组/张量裁剪到输入数组/张量的范围。
fixed_mean – 在使用 factor 缩放之前减去平均强度,然后在缩放之后加上相同的值,以确保输出与输入具有相同的均值。
channel_wise – 如果为 True,则对每个通道分别进行缩放。如果 channel_wise 为 True,preserve_range 和 fixed_mean 也将分别应用于每个通道。如果为 True,请确保第一个维度表示图像的通道。
the (如果 channel_wise 为 True,则在每个通道上单独进行。请确保第一维度代表)
True. (图像的通道如果)
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
NormalizeIntensity#
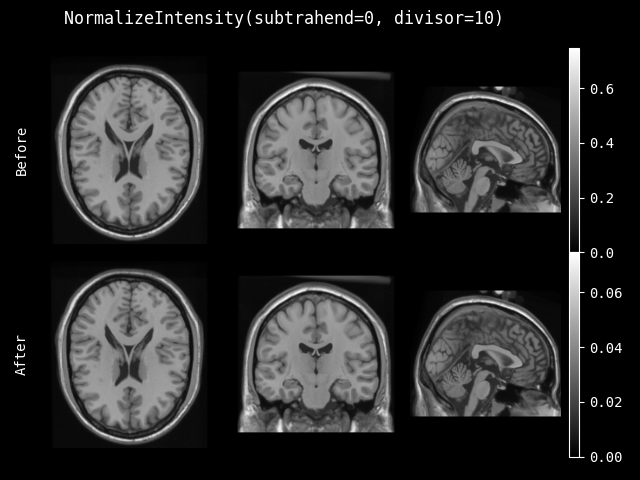
- class monai.transforms.NormalizeIntensity(subtrahend=None, divisor=None, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
根据 subtrahend 和 divisor 归一化输入:(img - subtrahend) / divisor。如果未提供 subtrahend 或 divisor,则使用输入图像的计算均值或标准差。此变换可以仅归一化非零值或整个图像,也可以分别计算每个通道的均值和标准差。当 channel_wise 为 True 时,如果 subtrahend 和 divisor 不为 None,则它们的第一个维度应为图像通道数。
- 参数:
subtrahend – 减去的量(通常是均值)。
divisor – 除以的量(通常是标准差)。
nonzero – 是否只归一化非零值。
channel_wise – 如果为 True,则对每个通道分别计算,否则直接在整个图像上计算。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
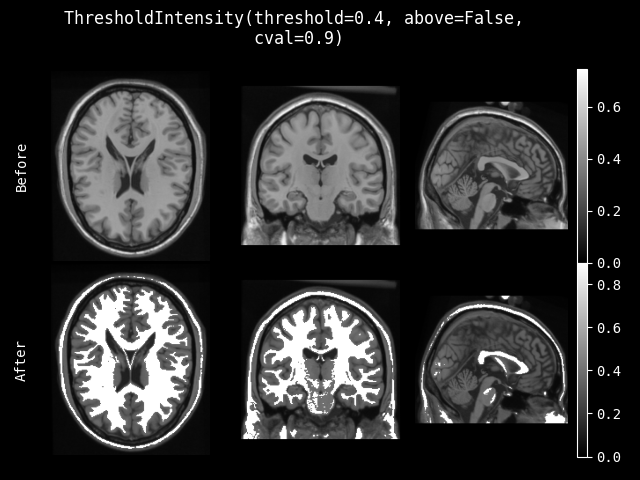
ThresholdIntensity#
ScaleIntensityRange#
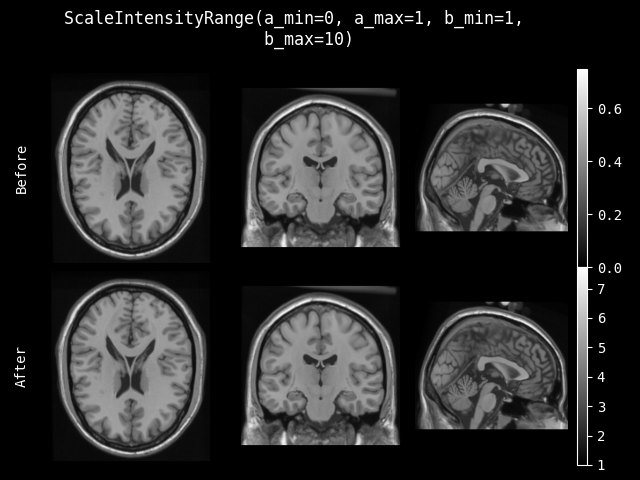
- class monai.transforms.ScaleIntensityRange(a_min, a_max, b_min=None, b_max=None, clip=False, dtype=<class 'numpy.float32'>)[source]#
对整个 numpy 数组应用特定的强度缩放。使用裁剪选项将范围从 [a_min, a_max] 缩放到 [b_min, b_max]。
当 b_min 或 b_max 为 None 时,将跳过 scaled_array * (b_max - b_min) + b_min。如果 clip=True,当 b_min/b_max 为 None 时,不会对相应的边界执行裁剪。
- 参数:
a_min – 强度原始范围最小值。
a_max – 强度原始范围最大值。
b_min – 强度目标范围最小值。
b_max – 强度目标范围最大值。
clip – 是否在缩放后执行裁剪。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
ScaleIntensityRangePercentiles#
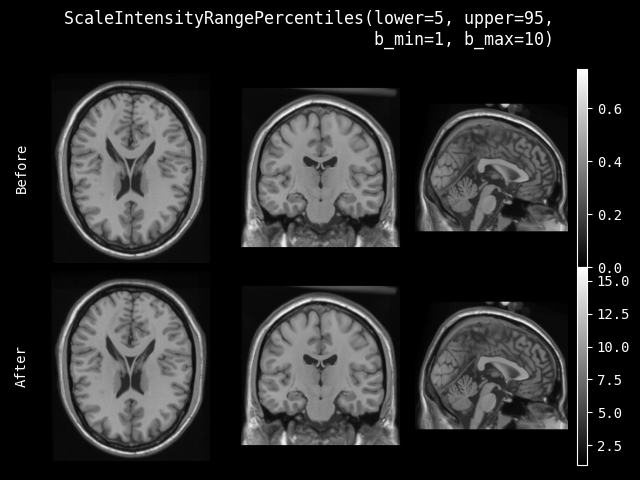
- class monai.transforms.ScaleIntensityRangePercentiles(lower, upper, b_min, b_max, clip=False, relative=False, channel_wise=False, dtype=<class 'numpy.float32'>)[source]#
根据输入的强度分布对 numpy 数组应用范围缩放。
默认情况下,此转换将从 [较低强度百分位数, 较高强度百分位数] 缩放到 [b_min, b_max],其中 {较低,较高}_强度_百分位数是
img对应百分位数处的强度值。relative参数也可以设置为从 [较低强度百分位数, 较高强度百分位数] 缩放到输出范围 [b_min, b_max] 的较低和较高百分位数。例如
image = torch.Tensor( [[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5], [1, 2, 3, 4, 5]]]) # Scale from lower and upper image intensity percentiles # to output range [b_min, b_max] scaler = ScaleIntensityRangePercentiles(10, 90, 0, 200, False, False) print(scaler(image)) metatensor([[[ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.], [ 0., 50., 100., 150., 200.]]]) # Scale from lower and upper image intensity percentiles # to lower and upper percentiles of the output range [b_min, b_max] rel_scaler = ScaleIntensityRangePercentiles(10, 90, 0, 200, False, True) print(rel_scaler(image)) metatensor([[[ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.], [ 20., 60., 100., 140., 180.]]])
- 参数:
lower – 较低强度百分位数。
upper – 较高强度百分位数。
b_min – 强度目标范围最小值。
b_max – 强度目标范围最大值。
clip – 是否在缩放后执行裁剪。
relative – 是否缩放到 [b_min, b_max] 的相应百分位数。
channel_wise – 如果为 True,则分别计算每个通道的强度百分位数并进行归一化。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
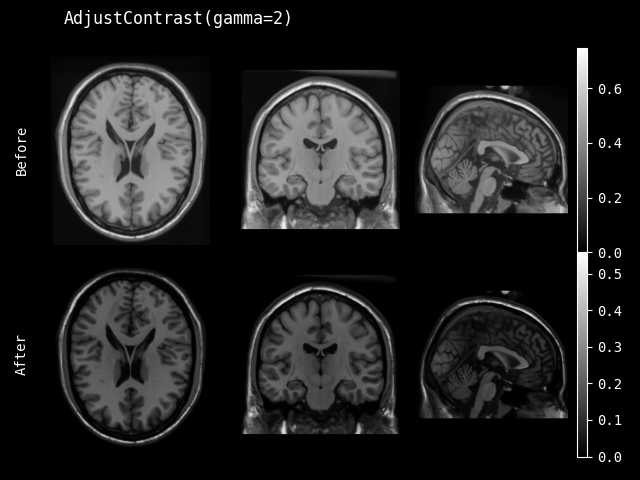
AdjustContrast#
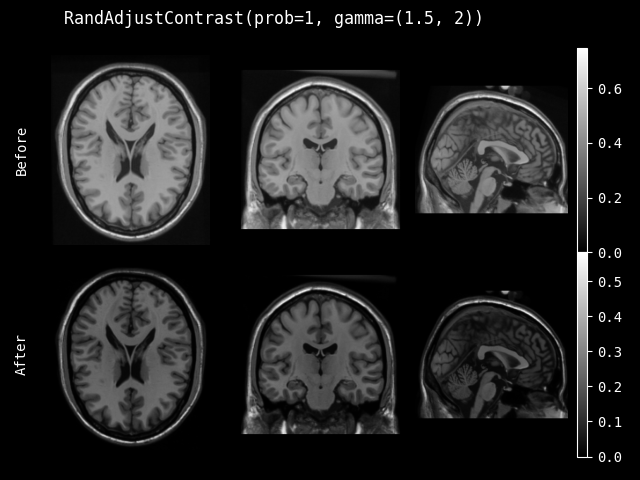
RandAdjustContrast#
MaskIntensity#
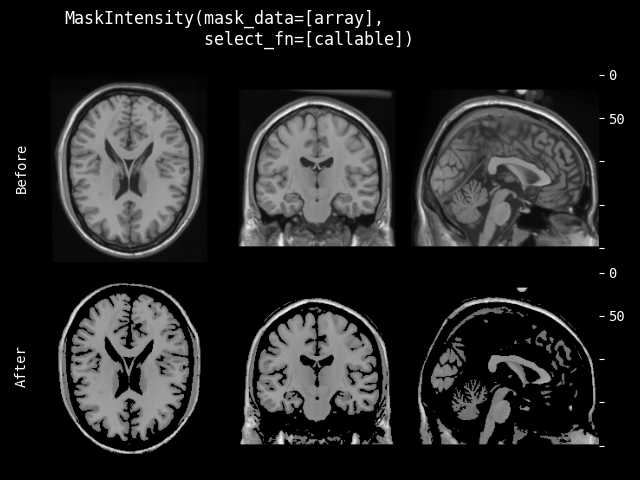
- class monai.transforms.MaskIntensity(mask_data=None, select_fn=<function is_positive>)[source]#
使用指定的掩码数据遮蔽输入图像的强度值。掩码数据必须与输入图像具有相同的空间尺寸,并且输入图像中与掩码数据中选定值对应的所有强度值将保持原始值,其他值将设置为 0。
- 参数:
mask_data – 如果 mask_data 是单通道,则应用于输入图像的每个通道。如果是多通道,通道数必须与输入数据匹配。输入图像中与掩码数据中选定值对应的强度值将保持原始值,其他值将设置为 0。如果为 None,则必须在运行时指定 mask_data。
select_fn – 用于选择 mask_data 有效值的函数,默认为选择 values > 0。
SavitzkyGolaySmooth#
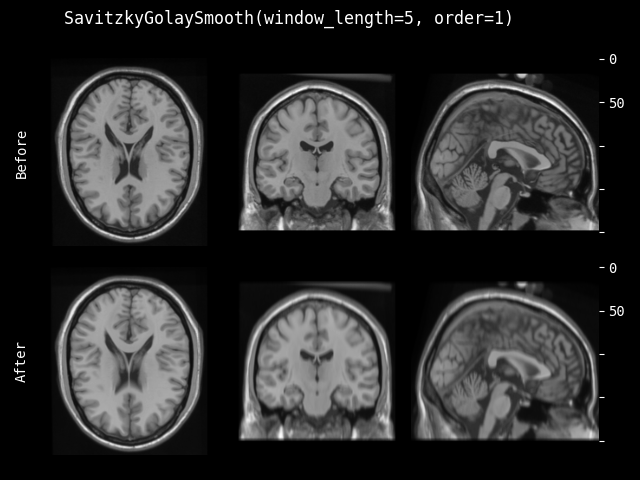
- class monai.transforms.SavitzkyGolaySmooth(window_length, order, axis=1, mode='zeros')[source]#
使用 Savitzky-Golay 滤波器沿给定轴平滑输入数据。
- 参数:
window_length (
int) – 滤波器窗口的长度,必须是正奇整数。order (
int) – 拟合到每个窗口的多项式阶数,必须小于window_length。axis (
int) – 可选轴,用于应用滤波器核。默认为 1(第一个空间维度)。mode (
str) – 可选的填充模式,传递给卷积类。'zeros'、'reflect'、'replicate'或'circular'。默认为:'zeros'。有关更多信息,请参阅torch.nn.Conv1d()。
MedianSmooth#
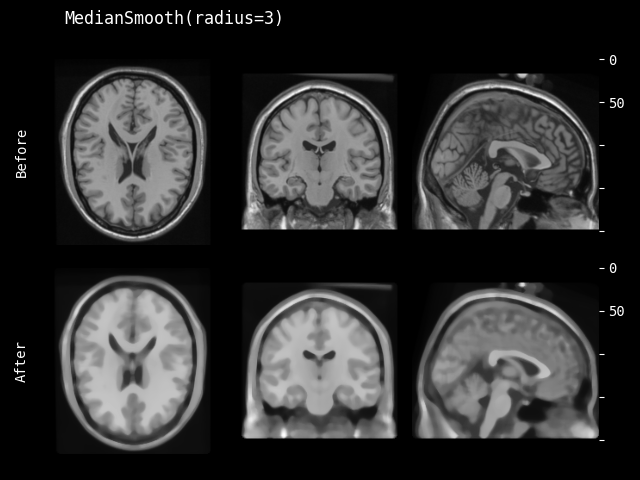
- class monai.transforms.MedianSmooth(radius=1)[source]#
根据指定的 radius 参数对输入数据应用中值滤波器。提供了默认值 radius=1 作为参考。
另请参阅:
monai.networks.layers.median_filter()- 参数:
radius – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
~NdarrayTensor
GaussianSmooth#
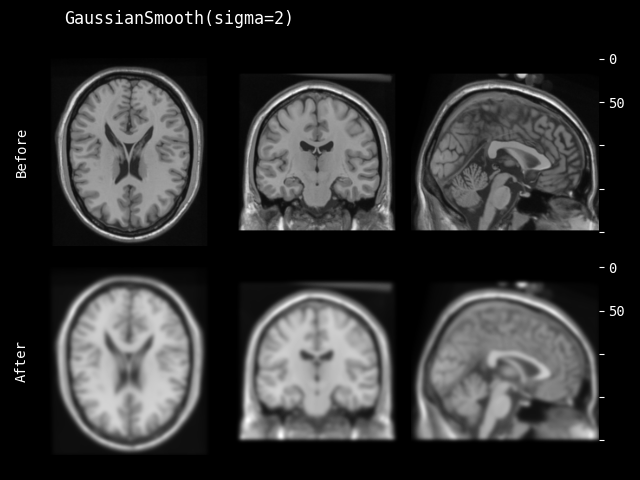
- class monai.transforms.GaussianSmooth(sigma=1.0, approx='erf')[source]#
根据指定的 sigma 参数对输入数据应用高斯平滑。提供了默认值 sigma=1.0 作为参考。
- 参数:
sigma – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
~NdarrayTensor
RandGaussianSmooth#
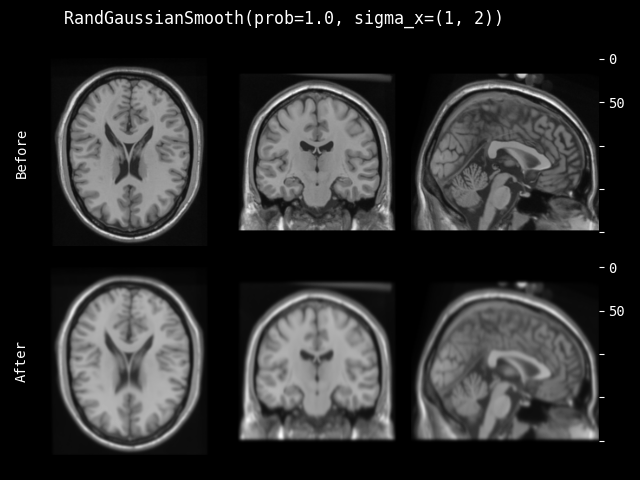
- class monai.transforms.RandGaussianSmooth(sigma_x=(0.25, 1.5), sigma_y=(0.25, 1.5), sigma_z=(0.25, 1.5), prob=0.1, approx='erf')[source]#
根据随机选择的 sigma 参数对输入数据应用高斯平滑。
- 参数:
sigma_x (
tuple[float,float]) – 随机选择第一个空间维度的 sigma 值。sigma_y (
tuple[float,float]) – 如果存在,随机选择第二个空间维度的 sigma 值。sigma_z (
tuple[float,float]) – 如果存在,随机选择第三个空间维度的 sigma 值。prob (
float) – 高斯平滑的概率。approx (
str) – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅monai.networks.layers.GaussianFilter()。
- __call__(img, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
GaussianSharpen#
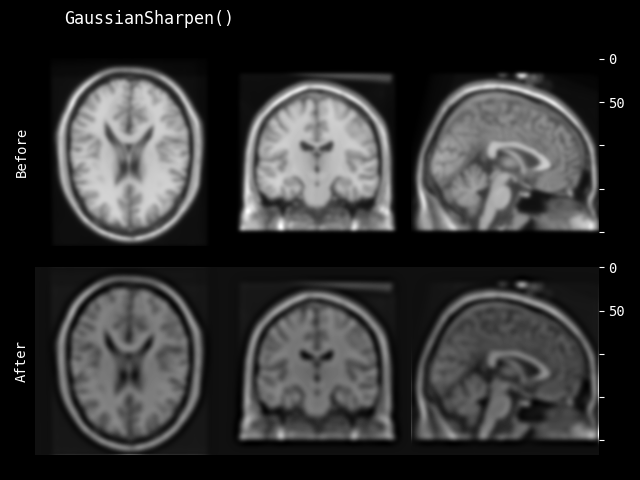
- class monai.transforms.GaussianSharpen(sigma1=3.0, sigma2=1.0, alpha=30.0, approx='erf')[source]#
使用高斯模糊滤波器锐化图像。参考:http://scipy-lectures.org/advanced/image_processing/auto_examples/plot_sharpen.html。算法如下所示
blurred_f = gaussian_filter(img, sigma1) filter_blurred_f = gaussian_filter(blurred_f, sigma2) img = blurred_f + alpha * (blurred_f - filter_blurred_f)
提供了一组默认值 sigma1=3.0、sigma2=1.0 和 alpha=30.0 作为参考。
- 参数:
sigma1 – 第一个高斯核的 sigma 参数。如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
sigma2 – 第二个高斯核的 sigma 参数。如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
alpha – 用于计算最终结果的权重参数。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
~NdarrayTensor
RandGaussianSharpen#
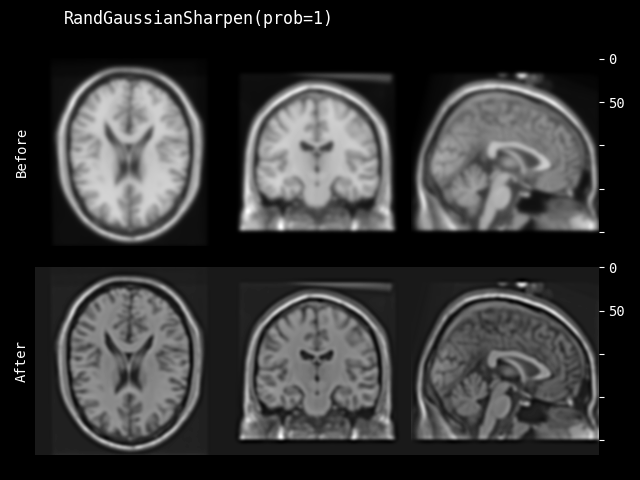
- class monai.transforms.RandGaussianSharpen(sigma1_x=(0.5, 1.0), sigma1_y=(0.5, 1.0), sigma1_z=(0.5, 1.0), sigma2_x=0.5, sigma2_y=0.5, sigma2_z=0.5, alpha=(10.0, 30.0), approx='erf', prob=0.1)[source]#
根据随机选择的 sigma1、sigma2 和 alpha,使用高斯模糊滤波器锐化图像。算法为
monai.transforms.GaussianSharpen。- 参数:
sigma1_x – 随机选择第一个高斯核的第一个空间维度的 sigma 值。
sigma1_y – 如果存在,随机选择第一个高斯核的第二个空间维度的 sigma 值。
sigma1_z – 如果存在,随机选择第一个高斯核的第三个空间维度的 sigma 值。
sigma2_x – 随机选择用于第二个高斯核第一空间维度的 sigma 值。如果只提供一个值 X,则它必须小于 sigma1_x 并在 [X, sigma1_x] 范围内随机选择。
sigma2_y – 随机选择用于第二个高斯核第二空间维度(如果存在)的 sigma 值。如果只提供一个值 Y,则它必须小于 sigma1_y 并在 [Y, sigma1_y] 范围内随机选择。
sigma2_z – 随机选择用于第二个高斯核第三空间维度(如果存在)的 sigma 值。如果只提供一个值 Z,则它必须小于 sigma1_z 并在 [Z, sigma1_z] 范围内随机选择。
alpha – 随机选择权重参数以计算最终结果。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。prob – 高斯锐化的概率。
- __call__(img, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
RandHistogramShift#
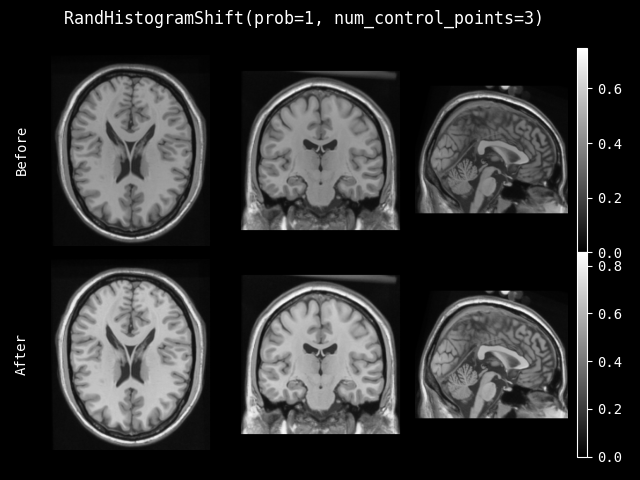
- class monai.transforms.RandHistogramShift(num_control_points=10, prob=0.1)[source]#
对图像的强度直方图应用随机非线性变换。
- 参数:
num_control_points – 控制非线性强度映射的控制点数量。控制点数量越少,允许的强度偏移越大。如果提供两个值,则控制点数量从范围 (min_value, max_value) 中选择。
prob – 直方图偏移的概率。
- __call__(img, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
DetectEnvelope#
GibbsNoise#
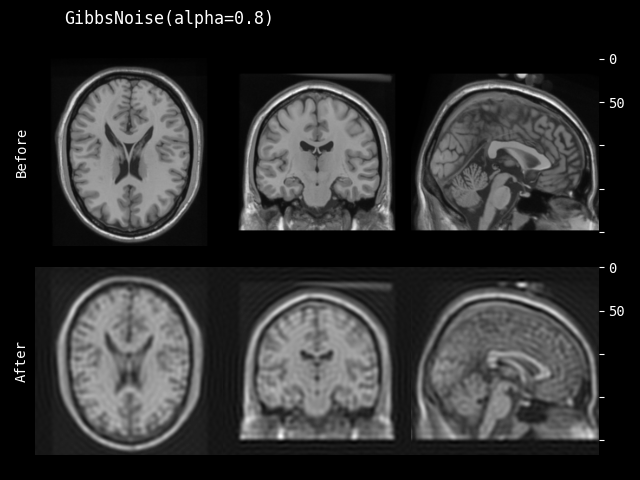
- class monai.transforms.GibbsNoise(alpha=0.1)[source]#
该变换对 2D/3D MRI 图像应用 Gibbs 噪声。Gibbs 伪影是 MRI 扫描中常见的伪影类型之一。
该变换应用于数据中的所有通道。
关于 Gibbs 伪影的一般信息,请参阅
An Image-based Approach to Understanding the Physics of MR Artifacts.
The AAPM/RSNA Physics Tutorial for Residents
- 参数:
alpha (
float) – 参数化应用的 Gibbs 噪声滤波器强度。取值范围为 [0,1],其中 alpha = 0 等同于恒等映射。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
RandGibbsNoise#
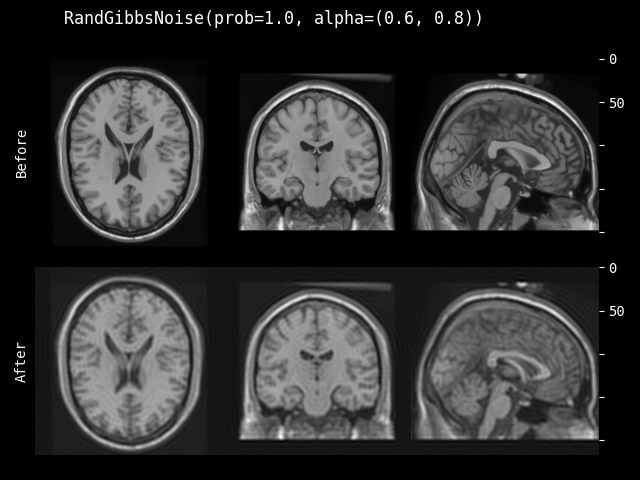
- class monai.transforms.RandGibbsNoise(prob=0.1, alpha=(0.0, 1.0))[source]#
通过 Gibbs 伪影进行自然图像增强。该变换随机对 2D/3D MRI 图像应用 Gibbs 噪声。Gibbs 伪影是 MRI 扫描中常见的伪影类型之一。
该变换应用于数据中的所有通道。
关于 Gibbs 伪影的一般信息,请参阅:https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- 参数:
prob (float) – 应用变换的概率。
alpha (float, Sequence(float)) – 参数化应用的 Gibbs 噪声滤波器强度。取值范围为 [0,1],其中 alpha = 0 等同于恒等映射。如果给定一个长度为 2 的列表 [a,b],则 alpha 值将从区间 [a,b] 中均匀采样。0 <= a <= b <= 1。如果给定一个浮点数,则 alpha 值将从区间 [0, alpha] 中均匀采样。
- __call__(img, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
KSpaceSpikeNoise#
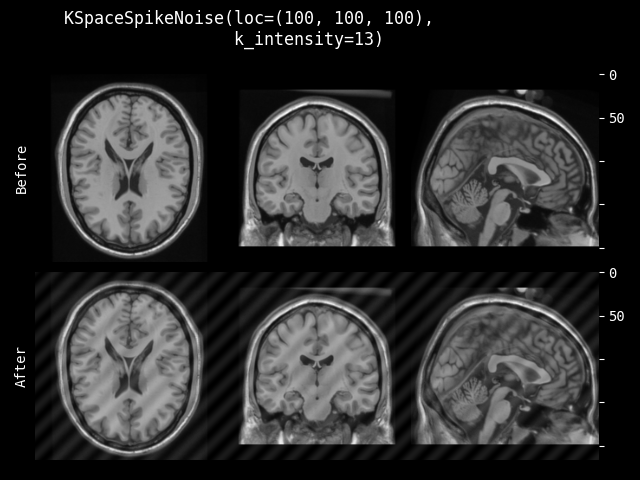
- class monai.transforms.KSpaceSpikeNoise(loc, k_intensity=None)[source]#
在给定位置和强度下,在 k 空间应用局部尖峰。尖峰(人字形)伪影是一种可能在 MRI 扫描期间发生的数据采集伪影。
关于尖峰伪影的一般信息,请参阅
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- 参数:
loc – 尖峰的空间位置。对于具有 3D 空间维度的图像,用户可以提供 (C, X, Y, Z) 来固定受影响的通道 C,或者提供 (X, Y, Z) 以在所有通道中放置相同的尖峰。对于 2D 情况,用户可以提供 (C, X, Y) 或 (X, Y)。
k_intensity – 图像 k 空间版本的对数强度值。如果 loc 只传递一个位置或未指定通道,则此参数应接收一个浮点数。如果 loc 给定了一个位置序列,则此参数应接收一个强度序列。此值应进行测试,因为它取决于数据。默认值是每个通道对数强度的均值的 2.5 倍。
示例
处理 4D 数据时,
KSpaceSpikeNoise(loc = ((3,60,64,32), (64,60,32)), k_intensity = (13,14))将在 [3, 60, 64, 32] 处放置一个对数强度为 13 的尖峰,并在每个通道的 [: , 64, 60, 32] 处分别放置一个对数强度为 14 的尖峰。
RandKSpaceSpikeNoise#
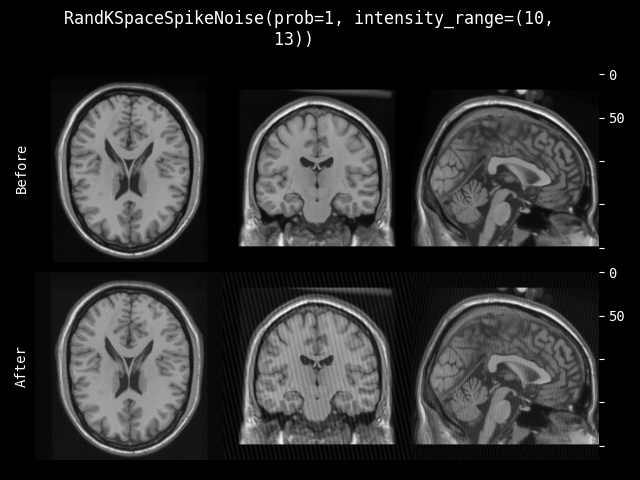
- class monai.transforms.RandKSpaceSpikeNoise(prob=0.1, intensity_range=None, channel_wise=True)[source]#
通过尖峰伪影进行自然数据增强。该变换在 k 空间应用局部尖峰,是
monai.transforms.KSpaceSpikeNoise的随机版本。尖峰(人字形)伪影是一种可能在 MRI 扫描期间发生的数据采集伪影。关于尖峰伪影的一般信息,请参阅
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- 参数:
prob – 应用变换的概率,可以一次性应用于所有通道,或者在
channel_wise = True时按通道应用。intensity_range – 传入一个元组 (a, b) 以从区间 (a, b) 中为所有通道均匀采样对数强度。或者传入一个区间序列 ((a0, b0), (a1, b1), …) 以分别采样每个通道。在第二种情况下,2 元组的数量必须与通道数匹配。默认范围为 (0.95x, 1.10x),其中 x 是每个通道的平均对数强度。
channel_wise – 独立处理每个通道。默认为 True。
示例
要以 0.5 的概率随机应用 k 空间尖峰,并为每个通道独立地从区间 [11, 12] 中采样对数强度,可以使用
RandKSpaceSpikeNoise(prob=0.5, intensity_range=(11, 12), channel_wise=True)
RandRicianNoise#
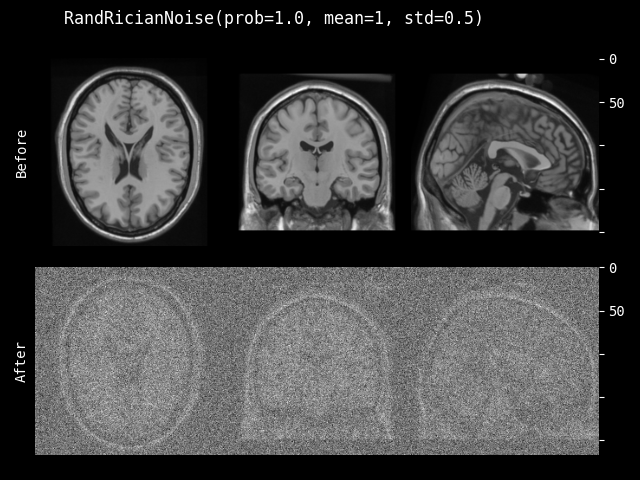
- class monai.transforms.RandRicianNoise(prob=0.1, mean=0.0, std=1.0, channel_wise=False, relative=False, sample_std=True, dtype=<class 'numpy.float32'>)[source]#
为图像添加 Rician 噪声。MRI 中的 Rician 噪声是在两个通道中具有相同方差的高斯噪声的复数数据上执行幅度操作的结果,如 Noise in Magnitude Magnetic Resonance Images 中所述。此变换改编自 DIPY。另请参阅:The rician distribution of noisy mri data。
- 参数:
prob – 添加 Rician 噪声的概率。
mean – 构成 Rician 噪声的采样高斯分布的均值或“中心”。
std – 构成 Rician 噪声的采样高斯分布的标准差(分布范围)。
channel_wise – 如果为 True,则独立处理图像的每个通道。
relative – 如果为 True,则采样高斯分布的分布范围将是 std 乘以图像或通道强度直方图的标准差。
sample_std – 如果为 True,则从 0 到 std 范围内均匀采样高斯分布的分布范围。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
RandCoarseTransform#
- class monai.transforms.RandCoarseTransform(holes, spatial_size, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
随机选择图像中的粗略区域,然后对这些区域执行变换操作。它是各种区域变换的基类。参考论文:https://arxiv.org/abs/1708.04552
- 参数:
holes – 要丢弃的区域数量,如果 max_holes 不是 None,则使用此参数作为随机选择预期区域数量的最小值。
spatial_size – 要丢弃区域的空间大小,如果 max_spatial_size 不是 None,则使用此参数作为随机选择每个区域大小的最小空间大小。如果 spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
max_holes – 如果不是 None,定义随机选择预期区域数量的最大值。
max_spatial_size – 如果不是 None,定义随机选择每个区域大小的最大空间大小。如果 max_spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 max_spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 应用变换的概率。
- __call__(img, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
RandCoarseDropout#
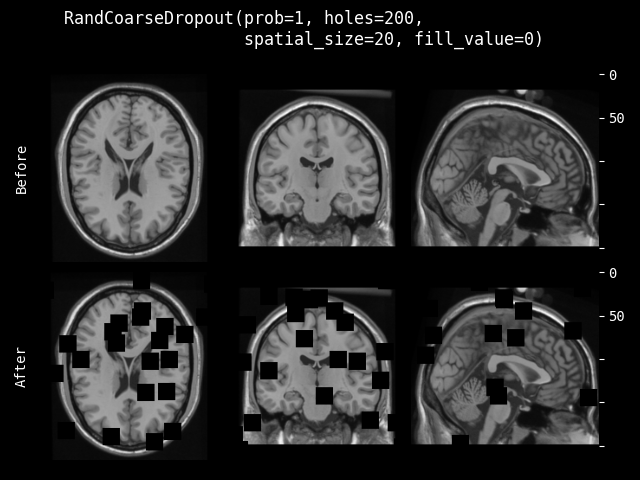
- class monai.transforms.RandCoarseDropout(holes, spatial_size, dropout_holes=True, fill_value=None, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
随机粗略丢弃图像中的区域,然后用指定值填充矩形区域。或者保留矩形区域,用指定值填充其他区域。参考论文:https://arxiv.org/abs/1708.04552, https://arxiv.org/pdf/1604.07379 和其他实现:https://albumentations.ai/docs/api_reference/augmentations/transforms/ #albumentations.augmentations.transforms.CoarseDropout。
- 参数:
holes – 要丢弃的区域数量,如果 max_holes 不是 None,则使用此参数作为随机选择预期区域数量的最小值。
spatial_size – 要丢弃区域的空间大小,如果 max_spatial_size 不是 None,则使用此参数作为随机选择每个区域大小的最小空间大小。如果 spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
dropout_holes – 如果为 True,则丢弃孔洞区域并填充值;如果为 False,则保留孔洞并丢弃外部区域并填充值。默认为 True。
fill_value – 用于填充丢弃区域的目标值,如果提供一个数字,将用作常数值填充所有区域。如果为 min 和 max 提供一个元组,将从范围 [min, max) 中为每个像素/体素随机选择值。如果为 None,将计算输入图像的 min 和 max 值,然后随机选择值进行填充,默认为 None。
max_holes – 如果不是 None,定义随机选择预期区域数量的最大值。
max_spatial_size – 如果不是 None,定义随机选择每个区域大小的最大空间大小。如果 max_spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 max_spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 应用变换的概率。
RandCoarseShuffle#
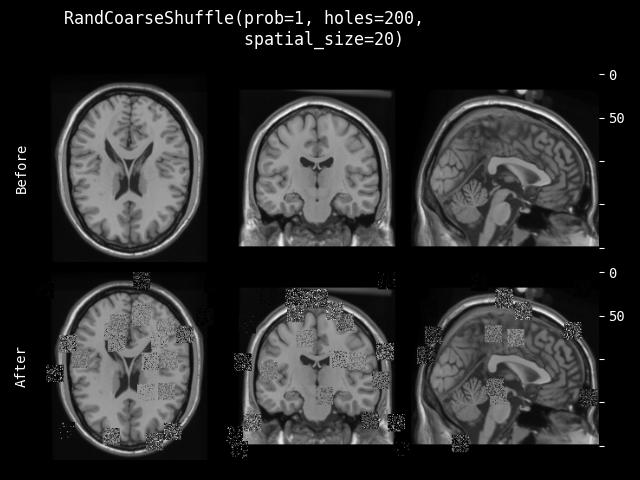
- class monai.transforms.RandCoarseShuffle(holes, spatial_size, max_holes=None, max_spatial_size=None, prob=0.1)[source]#
随机选择图像中的区域,然后打乱每个区域内的像素。它会单独打乱每个通道。参考论文:Kang, Guoliang, et al. “Patchshuffle regularization.” arXiv preprint arXiv:1707.07103 (2017). https://arxiv.org/abs/1707.07103
- 参数:
holes – 要丢弃的区域数量,如果 max_holes 不是 None,则使用此参数作为随机选择预期区域数量的最小值。
spatial_size – 要丢弃区域的空间大小,如果 max_spatial_size 不是 None,则使用此参数作为随机选择每个区域大小的最小空间大小。如果 spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
max_holes – 如果不是 None,定义随机选择预期区域数量的最大值。
max_spatial_size – 如果不是 None,定义随机选择每个区域大小的最大空间大小。如果 max_spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 max_spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 应用变换的概率。
HistogramNormalize#
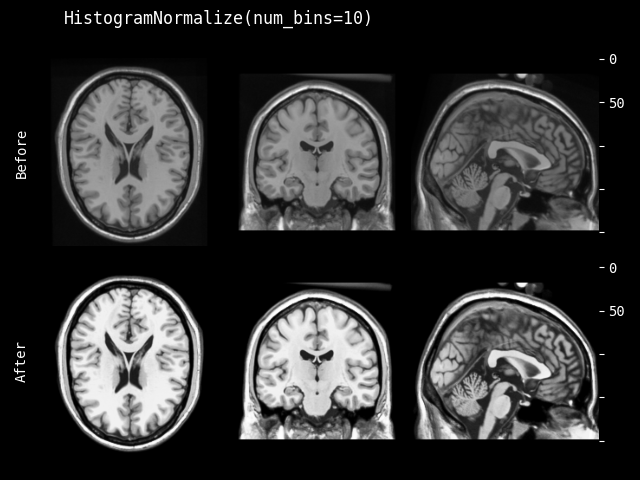
- class monai.transforms.HistogramNormalize(num_bins=256, min=0, max=255, mask=None, dtype=<class 'numpy.float32'>)[source]#
将直方图归一化应用于输入图像。参考:facebookresearch/CovidPrognosis。
- 参数:
num_bins – 直方图中使用的 bin 数量,默认为 256。更多详情请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.histogram.html。
min – 用于归一化输入图像的最小值,默认为 0。
max – 用于归一化输入图像的最大值,默认为 255。
mask – 如果提供,必须是布尔值或 0 和 1 的 ndarray,且形状与 image 相同。只有 mask==True 的点用于均衡化。也可以在运行时与 img 一起提供掩码。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
- __call__(img, mask=None)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
ForegroundMask#
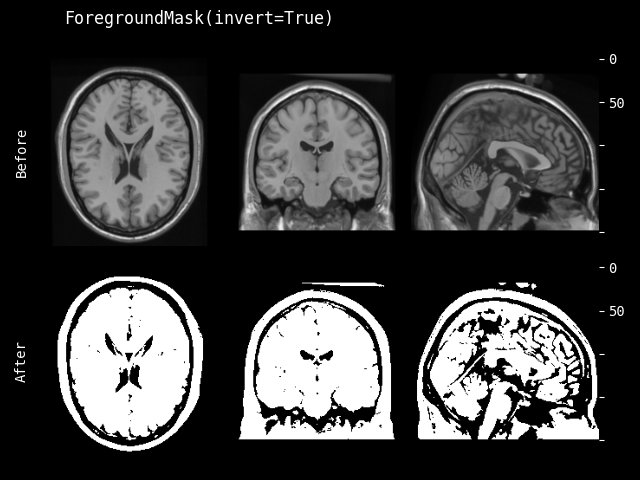
- class monai.transforms.ForegroundMask(threshold='otsu', hsv_threshold=None, invert=False)[source]#
创建一个二值掩码,根据 RGB 或 HSV 颜色空间中的阈值定义前景。该变换接收 RGB(或灰度)图像,默认情况下,假定前景具有低值(暗),而背景具有高值(白)。否则,将 invert 参数设置为 True。
- 参数:
threshold – 定义阈值的整数或浮点数,小于该阈值的值被视为前景。它也可以是一个可调用对象,接收图像的每个维度并计算阈值,或者一个字符串,从 skimage.filter.threshold_… 定义此类可调用对象。有关可用阈值函数的列表,请参阅 https://scikit-image.cn/docs/stable/api/skimage.filters.html 此外,可以传入一个字典,为每个通道定义此类阈值,例如 {“R”: 100, “G”: “otsu”, “B”: skimage.filter.threshold_mean}
hsv_threshold – 类似于 threshold,但在 HSV 颜色空间(“H”、“S”和“V”)中。与 RBG 不同,在 HSV 中,大于 hsv_threshold 的值被视为前景。
invert – 反转输入图像的强度范围,使 dtype 最大值变为 dtype 最小值,反之亦然。
- __call__(image)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
ComputeHoVerMaps#
- class monai.transforms.ComputeHoVerMaps(dtype='float32')[source]#
从实例掩码计算水平和垂直图。它生成每个区域质心的标准化水平和垂直距离。输入数据大小为 [1xHxW[xD]],计算坐标时将暂时移除通道维度。
- 参数:
dtype (
Union[dtype,type,str,None]) – 输出 Tensor 的数据类型。默认为 “float32”。- 返回值:
一个大小为 [2xHxW[xD]] 的 torch.Tensor,它是水平和垂直图的堆叠。
- __call__(mask)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
IO#
LoadImage#
- class monai.transforms.LoadImage(reader=None, image_only=True, dtype=<class 'numpy.float32'>, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', expanduser=True, *args, **kwargs)[source]#
根据读取器从提供的路径加载图像文件或文件。如果未指定读取器,此类将根据支持的后缀按以下顺序自动选择读取器
调用此加载器时在运行时用户指定的读取器。
在 LoadImage 构造函数中用户指定的读取器。
注册列表中的读取器,从最后一个到第一个。
当前默认读取器:(nii, nii.gz -> NibabelReader),(png, jpg, bmp -> PILReader),(npz, npy -> NumpyReader),(nrrd -> NrrdReader),(DICOM 文件 -> ITKReader)。
请注意,对于 png、jpg、bmp 和其他 2D 格式,读取器默认在加载数组后将
reverse_indexing设置为True来交换轴 0 和 1,因为非医学特定文件格式的空间轴定义与其他常见医学包不同。另请参阅
- __call__(filename, reader=None)[source]#
从给定文件名加载图像文件和元数据。如果未指定 reader,此类将根据注册读取器 self.readers 的相反顺序自动选择读取器。
- 参数:
filename – 路径文件或类文件对象或文件列表。将使用键 filename_or_obj 将文件名保存到 meta_data。如果提供文件列表,则使用第一个文件的文件名保存,并将它们堆叠在一起作为多通道数据。如果提供目录路径而不是文件路径,则将其视为 DICOM 图像序列并读取。
reader – 运行时读取器,用于加载图像文件和元数据。
- __init__(reader=None, image_only=True, dtype=<class 'numpy.float32'>, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', expanduser=True, *args, **kwargs)[source]#
- 参数:
reader – 用于加载图像文件和元数据的读取器 - 如果 reader 为 None,将使用一组默认的 SUPPORTED_READERS。- 如果 reader 是一个字符串,则将其视为类名或带点的路径(例如
"monai.data.ITKReader"),支持的内置读取器类包括"ITKReader"、"NibabelReader"、"NumpyReader"、"PydicomReader"。将使用 *args 和 **kwargs 参数构造一个读取器实例。- 如果 reader 是一个读取器类/实例,它将相应地注册到此加载器。image_only – 如果为 True,则仅返回图像 MetaTensor,否则返回图像和头部字典。
dtype – 如果不是 None,将加载的图像转换为此数据类型。
ensure_channel_first – 如果 True 且同时加载了图像数组和元数据,则自动将图像数组形状转换为通道优先。默认为 False。
simple_keys – 是否移除冗余的元数据键,为向后兼容性默认为 False。
prune_meta_pattern – 与 prune_meta_sep 结合使用,是一个正则表达式,用于匹配和修剪元数据(嵌套字典)中的键,默认为 None,不删除键。
prune_meta_sep – 与 prune_meta_pattern 结合使用,用于匹配和修剪元数据(嵌套字典)中的键。默认为 ".",另请参阅
monai.transforms.DeleteItemsd。例如,prune_meta_pattern=".*_code$", prune_meta_sep=" "会移除以"_code"结尾的元数据键。expanduser – 如果为 True,将文件名转换为 Path 并对其调用 .expanduser,否则保持文件名不变。
args – 如果提供读取器名称,则为读取器的附加参数。
kwargs – 如果提供读取器名称,则为读取器的附加参数。
注意
该变换返回一个 MetaTensor,除非使用了 set_track_meta(False),在这种情况下将返回一个 torch.Tensor。
如果指定了 reader,加载器将尝试使用指定的读取器和默认支持的读取器。这在处理尝试不兼容加载器的异常时可能会引入开销。在这种情况下,建议将最合适的读取器设置为 reader 参数的最后一项。
- register(reader)[source]#
注册图像读取器以加载图像文件和元数据。
- 参数:
reader (
ImageReader) – 要注册到此加载器的读取器实例。
SaveImage#
- class monai.transforms.SaveImage(output_dir='./', output_postfix='trans', output_ext='.nii.gz', output_dtype=<class 'numpy.float32'>, resample=False, mode='nearest', padding_mode=border, scale=None, dtype=<class 'numpy.float64'>, squeeze_end_dims=True, data_root_dir='', separate_folder=True, print_log=True, output_format='', writer=None, channel_dim=0, output_name_formatter=None, folder_layout=None, savepath_in_metadict=False)[source]#
将图像(以 torch tensor 或 numpy ndarray 的形式)和元数据字典保存到文件中。
保存的文件名将是 {input_image_name}_{output_postfix}{output_ext},其中 input_image_name 从提供的元数据字典中提取。如果未提供元数据,则使用从 0 开始的递增索引作为文件名前缀。
- 参数:
output_dir – 输出图像目录。如果
folder_layout不是None,则由folder_layout处理。output_postfix – 追加到所有输出文件名的字符串,默认为 trans。如果
folder_layout不是None,则由folder_layout处理。output_ext – 输出文件扩展名。如果
folder_layout不是None,则由folder_layout处理。output_dtype – 用于保存数据的数据类型(如果不是 None)。默认为
np.float32。resample – 保存数据数组之前是否(如果需要)根据元数据中的
"spatial_shape"(和"original_affine")重新采样图像。mode –
此选项在
resample=True时使用。默认为"nearest"。根据写入器不同,可能的选项包括{
"bilinear","nearest","bicubic"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-sample{
"nearest","linear","bilinear","bicubic","trilinear","area"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#interpolate
padding_mode – 此选项在
resample = True时使用。默认为"border"。可能的选项包括 {"zeros","border","reflection"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-samplescale – {
255,65535} 通过裁剪到 [0, 1] 并缩放到 [0, 255] (uint8) 或 [0, 65535] (uint16) 来后处理数据。默认值为None(不缩放)。dtype – 重采样计算期间的数据类型。默认为
np.float64以获得最佳精度。如果为None,则使用输入数据的数据类型。要设置输出数据类型,请使用output_dtype。squeeze_end_dims – 如果为
True,则任何尾部的单例维度都将被移除(通道已移动到末尾后)。因此,如果输入是 (C,H,W,D),这将变为 (H,W,D,C),然后如果 C==1,它将保存为 (H,W,D)。如果 D 也为 1,它将保存为 (H,W)。如果为False,图像将始终保存为 (H,W,D,C)。data_root_dir –
如果非空,它指定输入文件绝对路径的起始部分。它用于计算
input_file_rel_path,即文件从data_root_dir的相对路径,以在保存时保留文件夹结构,以防不同文件夹中有同名文件。例如,对于以下输入input_file_name:
/foo/bar/test1/image.niioutput_postfix:
segoutput_ext:
.nii.gzoutput_dir:
/outputdata_root_dir:
/foo/bar
输出将是:
/output/test1/image/image_seg.nii.gz如果
folder_layout不是None,则由folder_layout处理。separate_folder – 是否将每个文件保存在单独的文件夹中。例如:对于输入文件名
image.nii,后缀seg和folder_pathoutput,如果separate_folder=True,它将保存为:output/image/image_seg.nii,如果False,则保存为output/image_seg.nii。默认为True。如果folder_layout不是None,则由folder_layout处理。print_log – 保存时是否打印日志。默认为
True。output_format – 指定输出图像写入器的可选文件名扩展名字符串。另请参阅:
monai.data.image_writer.SUPPORTED_WRITERS。writer – 一个自定义的
monai.data.ImageWriter子类,用于保存数据数组。如果为None,则根据output_ext使用monai.data.image_writer中的默认写入器。如果是一个字符串,则将其视为类名或带点的路径(例如"monai.data.ITKWriter");支持的内置写入器类包括"NibabelWriter"、"ITKWriter"、"PILWriter"。channel_dim – 通道维度的索引。默认为
0。None表示没有通道维度。output_name_formatter – 一个可调用函数(返回一个 kwargs 字典),用于格式化输出文件名。如果在
folder_layout中使用自定义的monai.data.FolderLayoutBase类,请考虑提供自己的格式化器。另请参阅:monai.data.folder_layout.default_name_formatter()。folder_layout – 一个自定义的
monai.data.FolderLayoutBase子类,用于定义文件命名方案。如果为None,则使用默认的FolderLayout。savepath_in_metadict – 如果为
True,则向元数据添加一个键"saved_to",其中包含输入图像保存到的路径。
- __call__(img, meta_data=None, filename=None)[source]#
- 参数:
img – 要保存到文件中的目标数据内容。图像应为通道优先,形状为:[C,H,W,[D]]。
meta_data – 与数据对应的元数据的键值对。
filename – str 或类文件对象,用于保存 img。如果指定,将忽略 self.output_name_formatter 和 self.folder_layout。
- set_options(init_kwargs=None, data_kwargs=None, meta_kwargs=None, write_kwargs=None)[source]#
通过更新 self.*_kwargs 字典来设置底层写入器的选项。
参数对应于以下用法
writer = ImageWriter(**init_kwargs)
writer.set_data_array(array, **data_kwargs)
writer.set_metadata(meta_data, **meta_kwargs)
writer.write(filename, **write_kwargs)
WriteFileMapping#
NVIDIA 工具扩展 (NVTX)#
RangePush#
RandRangePush#
RangePop#
RandRangePop#
Mark#
RandMark#
后处理#
激活#
- class monai.transforms.Activations(sigmoid=False, softmax=False, other=None, **kwargs)[源]#
激活操作,通常是 Sigmoid 或 Softmax。
- 参数:
sigmoid – 是否在进行转换前对模型输出执行 sigmoid 函数。默认为
False。softmax – 是否在进行转换前对模型输出执行 softmax 函数。默认为
False。other – 可调用函数,用于执行其他激活层,例如:other = lambda x: torch.tanh(x)。默认为
None。kwargs – 传递给 torch.softmax 的附加参数 (当
softmax=True时使用)。默认为dim=0,未识别的参数将被忽略。
- 抛出异常:
TypeError – 当
other不是Optional[Callable]时。
- __call__(img, sigmoid=None, softmax=None, other=None)[source]#
- 参数:
sigmoid – 在变换前是否对模型输出执行 sigmoid 函数。默认为
self.sigmoid。softmax – 在变换前是否对模型输出执行 softmax 函数。默认为
self.softmax。other – 用于执行其他激活层的可调用函数,例如:other = torch.tanh。默认为
self.other。
- 抛出异常:
ValueError – 当
sigmoid=True且softmax=True时。值不兼容。TypeError – 当
other不是Optional[Callable]时。ValueError – 当
self.other=None且other=None时。值不兼容。
AsDiscrete#
- class monai.transforms.AsDiscrete(argmax=False, to_onehot=None, threshold=None, rounding=None, **kwargs)[source]#
将输入张量/数组转换为离散值,可能的操作包括:
argmax.
将输入值阈值化为二进制值。
将输入值转换为 One-Hot 格式(设置
to_one_hot=N,其中 N 是类别数)。将值四舍五入到最接近的整数。
- 参数:
argmax – 在变换前是否对输入数据执行 argmax 函数。默认为
False。to_onehot – 如果不为 None,则将输入数据转换为具有指定类别数的 one-hot 格式。默认为
None。threshold – 如果不为 None,则根据指定的阈值将浮点值阈值化为整数 0 或 1。默认为
None。rounding – 如果不为 None,则根据指定的选项对数据进行四舍五入,可用选项:[“torchrounding”]。
kwargs – torch.argmax、monai.networks.one_hot 的附加参数。目前支持
dim、keepdim、dtype,无法识别的参数将被忽略。这些参数分别默认为0、True、torch.float。
示例
>>> transform = AsDiscrete(argmax=True) >>> print(transform(np.array([[[0.0, 1.0]], [[2.0, 3.0]]]))) # [[[1.0, 1.0]]]
>>> transform = AsDiscrete(threshold=0.6) >>> print(transform(np.array([[[0.0, 0.5], [0.8, 3.0]]]))) # [[[0.0, 0.0], [1.0, 1.0]]]
>>> transform = AsDiscrete(argmax=True, to_onehot=2, threshold=0.5) >>> print(transform(np.array([[[0.0, 1.0]], [[2.0, 3.0]]]))) # [[[0.0, 0.0]], [[1.0, 1.0]]]
- __call__(img, argmax=None, to_onehot=None, threshold=None, rounding=None)[source]#
- 参数:
img – 要转换的输入张量数据,如果转换为 One-Hot 时没有通道维度,将自动添加。
argmax – 在变换前是否对输入数据执行 argmax 函数。默认为
self.argmax。to_onehot – 如果不为 None,则将输入数据转换为具有指定类别数的 one-hot 格式。默认为
self.to_onehot。threshold – 如果不为 None,则根据指定的阈值将浮点值阈值化为整数 0 或 1。默认为
self.threshold。rounding – 如果不为 None,则根据指定的选项对数据进行四舍五入,可用选项:[“torchrounding”]。
KeepLargestConnectedComponent#
- class monai.transforms.KeepLargestConnectedComponent(applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1)[source]#
只保留图像中最大的连通分量。此变换可用作清理模型输出中过分割区域的后处理步骤。
- 输入假定为通道优先的 PyTorch 张量。
1) 对于非 OneHot 格式数据,值对应于期望的标签,0 被视为背景,过分割像素将被设置为 0。 2) 对于 OneHot 格式数据,每个标签上的值应为 0, 1,过分割像素将在其通道中设置为 0。
例如:使用 applied_labels=[1], is_onehot=False, connectivity=1
[1, 0, 0] [0, 0, 0] [0, 1, 1] => [0, 1 ,1] [0, 1, 1] [0, 1, 1]
使用 applied_labels=[1, 2], is_onehot=False, independent=False, connectivity=1
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [1, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [1, 2, 0, 0 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,0]
使用 applied_labels=[1, 2], is_onehot=False, independent=True, connectivity=1
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [0, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [0, 2, 0, 0 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,0]
使用 applied_labels=[1, 2], is_onehot=False, independent=False, connectivity=2
[0, 0, 1, 0 ,0] [0, 0, 1, 0 ,0] [0, 2, 1, 1 ,1] [0, 2, 1, 1 ,1] [1, 2, 1, 0 ,0] => [1, 2, 1, 0 ,0] [1, 2, 0, 1 ,0] [1, 2, 0, 1 ,0] [2, 2, 0, 0 ,2] [2, 2, 0, 0 ,2]
- __call__(img)[source]#
- 参数:
img (
Union[ndarray,Tensor]) – 形状必须是 (C, spatial_dim1[, spatial_dim2, …])。- 返回类型:
Union[ndarray,Tensor]- 返回值:
形状为 (C, spatial_dim1[, spatial_dim2, …]) 的数组。
- __init__(applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1)[source]#
- 参数:
applied_labels – 对其应用连通分量分析的标签。如果给定,则将分析值在此列表中的体素。如果 None,则将分析所有非零值。
is_onehot – 如果 True,将输入数据视为 OneHot 格式数据,否则视为非 OneHot 格式数据。默认为 None,将多通道数据视为 OneHot,单通道数据视为非 OneHot。
independent – 是否将
applied_labels视为前景标签的联合。如果True,将独立地对每个前景标签执行连通分量分析并返回最大连通分量的交集。如果False,将对前景标签的联合执行分析。默认为 True。connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅:https://scikit-image.cn/docs/dev/api/skimage.measure.html#skimage.measure.label。num_components – 要保留的最大连通分量的数量。
DistanceTransformEDT#
- class monai.transforms.DistanceTransformEDT(sampling=None)[source]#
对输入应用欧几里得距离变换。可以是基于 GPU(使用 CuPy / cuCIM)或基于 CPU(使用 scipy)。要使用 GPU 实现,请确保 cuCIM 可用且数据是 GPU 设备上的 torch.tensor。
请注意,不同库的结果可能有所不同,因此如果可能,请坚持使用一种。详细信息请查阅 SciPy 和 cuCIM 文档和/或
monai.transforms.utils.distance_transform_edt()。- __call__(img)[source]#
- 参数:
img (
Union[ndarray,Tensor]) – 要在其上运行距离变换的输入图像。必须是通道优先的数组,形状必须是:(num_channels, H, W [,D])。可以是任何类型,但将转换为二进制:图像为 True 的地方为 1,其他地方为 0。输入将按通道传递给距离变换,因此此函数的结果将与直接调用 CuPy 或 SciPy 中的distance_transform_edt()不同。sampling – 沿每个维度的元素间距。如果是序列,其长度必须等于输入秩减 1;如果是单个数字,则用于所有轴。如果未指定,则表示单位网格间距。
- 返回类型:
Union[ndarray,Tensor]- 返回值:
形状和数据类型与 img 相同的数组。
RemoveSmallObjects#
- class monai.transforms.RemoveSmallObjects(min_size=64, connectivity=1, independent_channels=True, by_measure=False, pixdim=None)[source]#
使用 skimage.morphology.remove_small_objects 从图像中移除小物体。请参阅:https://scikit-image.cn/docs/dev/api/skimage.morphology.html#remove-small-objects。
数据应该是一热编码的。
- 参数:
min_size – 小于此尺寸(以体素数量计;如果 by_measure 为 True,则以图像单位表示的表面积/体积值)的对象将被移除。
connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅链接的 scikit-image 文档。independent_channels – 是否将通道视为独立的。如果为 true,则来自不同标签的连接岛屿如果小于阈值将被移除。如果为 false,则使用由所有非背景体素组成的岛屿的总大小。
by_measure – 指定的 min_size 是否以体素数量计。如果为 True,则 min_size 表示以图像单位(mm^3, cm^2 等)表示的表面积或体积值。默认为 False。例如,如果 min_size 为 3,by_measure 为 True,且数据单位为 mm,则移除小于 3mm^3 的对象。
pixdim – 输入图像的像素尺寸。如果为单个数字,则用于所有轴。如果是数字序列,序列长度必须等于图像维度。
示例
.. code-block:: python from monai.transforms import RemoveSmallObjects, Spacing, Compose from monai.data import MetaTensor data1 = torch.tensor([[[0, 0, 0, 0, 0], [0, 1, 1, 0, 1], [0, 0, 0, 1, 1]]]) affine = torch.as_tensor([[2,0,0,0], [0,1,0,0], [0,0,1,0], [0,0,0,1]], dtype=torch.float64) data2 = MetaTensor(data1, affine=affine) # remove objects smaller than 3mm^3, input is MetaTensor trans = RemoveSmallObjects(min_size=3, by_measure=True) out = trans(data2) # remove objects smaller than 3mm^3, input is not MetaTensor trans = RemoveSmallObjects(min_size=3, by_measure=True, pixdim=(2, 1, 1)) out = trans(data1) # remove objects smaller than 3 (in pixel) trans = RemoveSmallObjects(min_size=3) out = trans(data2) # If the affine of the data is not identity, you can also add Spacing before. trans = Compose([ Spacing(pixdim=(1, 1, 1)), RemoveSmallObjects(min_size=3) ])
LabelFilter#
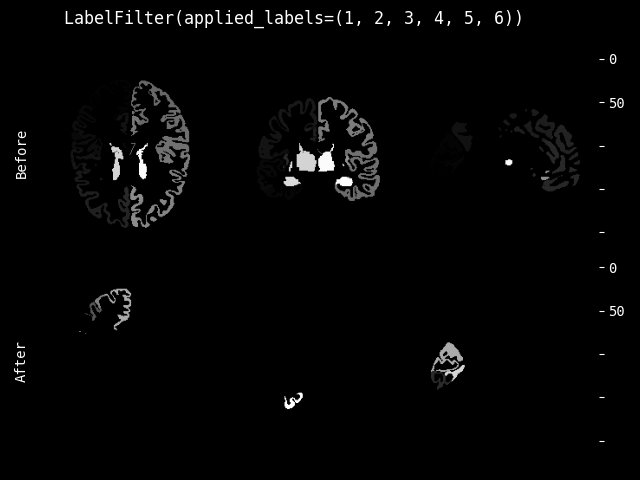
- class monai.transforms.LabelFilter(applied_labels)[source]#
此变换过滤掉标签,可用作只查看特定标签的处理步骤。
应用标签列表定义了要保留哪些标签。
注意
所有与 applied_labels 不匹配的标签都设置为背景标签 (0)。
例如
使用 LabelFilter,applied_labels=[1, 5, 9]
[1, 2, 3] [1, 0, 0] [4, 5, 6] => [0, 5 ,0] [7, 8, 9] [0, 0, 9]
FillHoles#
- class monai.transforms.FillHoles(applied_labels=None, connectivity=None)[source]#
此变换填充图像中的空洞,可用于移除分割内部的伪影。
包围的空洞定义为仅由单一类别包围的背景像素/体素。包围的定义可以使用 connectivity 参数来指定。
1-connectivity 2-connectivity diagonal connection close-up [ ] [ ] [ ] [ ] [ ] | \ | / | <- hop 2 [ ]--[x]--[ ] [ ]--[x]--[ ] [x]--[ ] | / | \ hop 1 [ ] [ ] [ ] [ ]
可以定义对哪些标签应用空洞填充。输入图像假定为形状为 [C, spatial_dim1[, spatial_dim2, …]] 的 PyTorch 张量或 numpy 数组。如果 C = 1,则值对应于期望的标签。如果 C > 1,则期望为 one-hot 编码,其中 C 的索引与标签索引匹配。
注意
标签 0 将被视为背景,包围的空洞将设置为相邻类别标签。
此方法的性能在很大程度上取决于标签数量。如果提供了 applied_labels 列表,则速度会更快一些。限制 applied_labels 的数量会大大减少处理时间。
例如
使用默认参数的 FillHoles
[1, 1, 1, 2, 2, 2, 3, 3] [1, 1, 1, 2, 2, 2, 3, 3] [1, 0, 1, 2, 0, 0, 3, 0] => [1, 1 ,1, 2, 0, 0, 3, 0] [1, 1, 1, 2, 2, 2, 3, 3] [1, 1, 1, 2, 2, 2, 3, 3]
标签 1 中的空洞完全被包围,因此用标签 1 填充。标签 2 和 3 附近的背景标签未完全包围,因此未填充。
- __call__(img)[source]#
填充提供的图像中的空洞。
注意
值 0 被假定为背景标签。
- 参数:
img (
Union[ndarray,Tensor]) – 形状为 [C, spatial_dim1[, spatial_dim2, …]] 的 PyTorch 张量或 numpy 数组。- 抛出异常:
NotImplementedError – 提供的图像不是 PyTorch 张量或 numpy 数组。
- 返回类型:
Union[ndarray,Tensor]- 返回值:
形状为 [C, spatial_dim1[, spatial_dim2, …]] 的 PyTorch 张量或 numpy 数组。
LabelToContour#
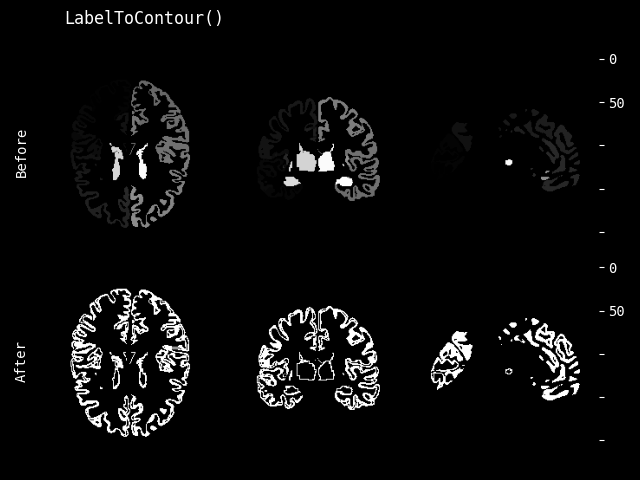
MeanEnsemble#
- class monai.transforms.MeanEnsemble(weights=None)[source]#
对输入数据执行均值集成。输入数据可以是形状为:[C[, H, W, D]] 的 PyTorch 张量列表或元组,也可以是形状为:[E, C[, H, W, D]] 的单个 PyTorch 张量,其中 E 维度表示来自不同模型的输出数据。通常,输入数据是分割任务或分类任务的模型输出。它还支持为输入数据添加 weights。
- 参数:
weights – 对于形状为:[E, C, H, W[, D]] 的输入数据,可以是数字列表或元组。也可以是 Numpy ndarray 或 PyTorch 张量数据。weights 将从最高维度添加到输入数据,例如:1. 如果 weights 只有 1 个维度,它将添加到输入数据的 E 维度。2. 如果 weights 有两个维度,它将添加到 E 和 C 维度。为不同类别添加权重是一种典型的做法:集成 3 个分割模型输出,每个输出有 4 个通道(类别),因此输入数据形状可以是:[3, 4, H, W, D]。为不同类别添加不同的 weights,因此 weights 形状可以是:[3, 4]。例如:weights = [[1, 2, 3, 4], [4, 3, 2, 1], [1, 1, 1, 1]]。
ProbNMS#
- class monai.transforms.ProbNMS(spatial_dims=2, sigma=0.0, prob_threshold=0.5, box_size=48)[source]#
通过迭代选择概率最高的坐标,然后移除该坐标及其周围的值,在概率图上执行基于概率的非最大抑制(NMS)。移除范围由参数 box_size 决定。如果多个坐标具有相同的最高概率,则只选择其中一个。
- 参数:
spatial_dims – 输入概率图的空间维度数量。默认为 2。
sigma – 高斯滤波器的标准差。可以是一个单独的值,也可以是 spatial_dims 个值。默认为 0.0。
prob_threshold – 概率阈值,如果最高概率不大于该阈值,函数将停止搜索。该值应不小于 0.0。默认为 0.5。
box_size – 围绕具有最大概率的像素移除的框大小(以像素为单位)。可以是一个整数,定义方形或立方体的大小,也可以是一个包含每个维度不同值的列表。默认为 48。
- 返回值:
选定列表的列表,其中内部列表包含概率和坐标。例如,对于 3D 输入,内部列表的形式为 [probability, x, y, z]。
- 抛出异常:
ValueError – 当
prob_threshold小于 0.0 时。ValueError – 当
box_size是列表或元组,且其长度不等于 spatial_dims 时。ValueError – 当
box_size的值小于 1 时。
SobelGradients#
- class monai.transforms.SobelGradients(kernel_size=3, spatial_axes=None, normalize_kernels=True, normalize_gradients=False, padding_mode='reflect', dtype=torch.float32)[source]#
计算形状为 CxH[xWxDx…] 或 BxH[xWxDx…] 的灰度图像的 Sobel 梯度。
- 参数:
kernel_size – Sobel 核的大小。默认为 3。
spatial_axes – 定义梯度计算方向的轴。它沿提供的每个轴计算梯度。默认计算所有空间轴的梯度。
normalize_kernels – 是否归一化 Sobel 核以提供正确的梯度。默认为 True。
normalize_gradients – 是否将输出梯度归一化到 0 和 1。默认为 False。
padding_mode – 与 Sobel 核卷积时图像的填充模式。默认为 “reflect”。可接受的值有
'zeros'、'reflect'、'replicate'或'circular'。更多信息请参阅torch.nn.Conv1d()。dtype – 核数据类型 (torch.dtype)。默认为 torch.float32。
- __call__(image)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Tensor
VoteEnsemble#
- class monai.transforms.VoteEnsemble(num_classes=None)[source]#
对输入数据执行投票集成。输入数据可以是形状为:[C[, H, W, D]] 的 PyTorch 张量列表或元组,也可以是形状为:[E[, C, H, W, D]] 的单个 PyTorch 张量,其中 E 维度表示来自不同模型的输出数据。通常,输入数据是分割任务或分类任务的模型输出。
注意
此投票变换期望输入数据是离散值。可以是 One-Hot 格式的多通道数据或单通道数据。它将投票选择项目之间最常见的数据。输出数据与输入数据的每个项目的形状相同。
- 参数:
num_classes – 如果输入是单通道数据而不是 One-Hot,我们无法从通道获取类别数量,需要明确指定要投票的类别数量。
Invert#
- class monai.transforms.Invert(transform=None, nearest_interp=True, device=None, post_func=None, to_tensor=True)[source]#
用于自动反转先前应用的变换的实用变换。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- __init__(transform=None, nearest_interp=True, device=None, post_func=None, to_tensor=True)[source]#
- 参数:
transform – 先前应用的变换。
nearest_interp – 反转空间变换时是否使用 nearest 插值模式,默认为 True。如果为 False,则使用与原始变换相同的插值模式。
device – 在 post_func 之前将反转结果移动到目标设备,默认为 None。
post_func – 对反转结果进行后处理,应该是一个可调用函数。
to_tensor – 是否先将反转数据转换为 PyTorch 张量,默认为 True。
正则化#
CutMix#
- class monai.transforms.CutMix(batch_size, alpha=1.0)[source]#
- CutMix 数据增强,描述于
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features, ICCV 2019
派生自
monai.transforms.Mixer的类。有关构造函数参数的详细信息,请参阅相应文档。在此,alpha 不仅决定混合权重,还决定用于混合的随机矩形的大小。请参阅论文了解详细信息。请注意,从版本 1.4.0 开始,行为有所变化。在以前的实现中,每次调用变换都会生成不同的标签。为了确保确定性,新的实现现在在使用相同的操作时,将为相同的输入图像生成相同的标签。
最常见的用例类似于
cm = CutMix(batch_size=8, alpha=0.5) for batch in loader: images, labels = batch augimg, auglabels = cm(images, labels) output = model(augimg) loss = loss_function(output, auglabels) ...
- __call__(data, labels=None, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
CutOut#
- class monai.transforms.CutOut(batch_size, alpha=1.0)[source]#
Cutout,描述于论文:Terrance DeVries, Graham W. Taylor. Improved Regularization of Convolutional Neural Networks with Cutout, arXiv:1708.04552
派生自
monai.transforms.Mixer的类。有关构造函数参数的详细信息,请参阅相应文档。在此,alpha 不仅决定混合权重,还决定被切除的随机矩形的大小。请参阅论文了解详细信息。- __call__(data, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
MixUp#
- class monai.transforms.MixUp(batch_size, alpha=1.0)[source]#
MixUp,描述于:Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz. mixup: Beyond Empirical Risk Minimization, ICLR 2018
派生自
monai.transforms.Mixer的类。有关构造函数参数的详细信息,请参阅相应文档。- __call__(data, labels=None, randomize=True)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
信号#
SignalRandDrop#
SignalRandScale#
SignalRandShift#
- class monai.transforms.SignalRandShift(mode='wrap', filling=0.0, boundaries=(-1.0, 1.0))[source]#
对信号应用随机平移
- __call__(signal)[source]#
- 参数:
signal (
Union[ndarray,Tensor]) – 要平移的输入一维信号- 返回类型:
Union[ndarray,Tensor]
- __init__(mode='wrap', filling=0.0, boundaries=(-1.0, 1.0))[source]#
- 参数:
mode – 定义输入数组如何在其边界之外进行扩展,更多详情请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.shift.html。
filling – 如果模式为 ‘constant’,用于填充输入边缘之外的值。默认为 0.0。更多模式详情请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.shift.html。
boundaries – 定义信号平移的下限和上限的列表,默认值:
[-1.0, 1.0]
SignalRandAddSine#
SignalRandAddSquarePulse#
SignalRandAddGaussianNoise#
SignalRandAddSinePartial#
- class monai.transforms.SignalRandAddSinePartial(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
向输入信号添加随机部分正弦信号
- __call__(signal)[source]#
- 参数:
signal (
Union[ndarray,Tensor]) – 将添加部分正弦信号的输入一维信号已添加 (即将支持)
- 返回类型:
Union[ndarray,Tensor]
- __init__(boundaries=(0.1, 0.3), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
- 参数:
boundaries (
Sequence[float]) – 定义正弦信号幅度的下限和上限的列表,下限和上限值必须为正,默认为:[0.1, 0.3]frequencies (
Sequence[float]) – 定义正弦信号生成频率的下限和上限的列表,默认为:[0.001, 0.02]fraction (
Sequence[float]) – 定义部分信号生成下限和上限的列表 默认为:[0.01, 0.2]
SignalRandAddSquarePulsePartial#
- class monai.transforms.SignalRandAddSquarePulsePartial(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
向信号添加一个随机部分方波脉冲
- __call__(signal)[source]#
- 参数:
signal (
Union[ndarray,Tensor]) – 要添加部分方波脉冲的输入一维信号- 返回类型:
Union[ndarray,Tensor]
- __init__(boundaries=(0.01, 0.2), frequencies=(0.001, 0.02), fraction=(0.01, 0.2))[source]#
- 参数:
boundaries (
Sequence[float]) – 定义方波幅度下限和上限的列表,下限和上限值需要是正数,默认值:[0.01, 0.2]frequencies (
Sequence[float]) – 定义方波脉冲信号生成频率的下限和上限的列表 示例:[0.001, 0.02]fraction (
Sequence[float]) – 定义部分方波脉冲生成下限和上限的列表 默认为:[0.01, 0.2]
SignalFillEmpty#
SignalRemoveFrequency#
- class monai.transforms.SignalRemoveFrequency(frequency=None, quality_factor=None, sampling_freq=None)[source]#
从信号中移除某个频率
- __init__(frequency=None, quality_factor=None, sampling_freq=None)[source]#
- 参数:
frequency – 要从信号中移除的频率
quality_factor – 陷波滤波器的品质因数 请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.signal.iirnotch.html
sampling_freq – 输入信号的采样频率
SignalContinuousWavelet#
- class monai.transforms.SignalContinuousWavelet(type='mexh', length=125.0, frequency=500.0)[source]#
生成信号的连续小波变换
- __init__(type='mexh', length=125.0, frequency=500.0)[source]#
- 参数:
type (
str) – 母小波类型。可用选项包括:{"mexh","morl","cmorB-C", ,"gausP"}请参阅 – https://pywavelets.readthedocs.io/en/stable/ref/cwt.html
length (
float) – 期望长度,默认为125.0frequency (
float) – 信号频率,默认为500.0
Spatial#
SpatialResample#
- class monai.transforms.SpatialResample(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
将输入图像从由
src_affine仿射矩阵定义的方向/间距重采样到由dst_affine仿射矩阵指定的方向/间距。该变换在内部计算从
src_affine到dst_affine的仿射变换矩阵,通过xform = linalg.solve(src_affine, dst_affine),并使用xform调用monai.transforms.Affine。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, dst_affine=None, spatial_size=None, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- 参数:
img – 要重采样的输入图像。当前支持最多三个空间维度的通道优先数组。
dst_affine – 目标仿射矩阵。默认为
None,表示与 img.affine 相同。形状应为 (r+1, r+1),其中 r 是img的空间秩。当 dst_affine 和 spatial_size 为 None 时,将返回输入而不进行重采样,但数据类型将是 float32。spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,变换将自动计算一个包含先前视野的空间大小。如果 spatial_size 是
-1,则变换将使用相应的输入图像大小。mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – 从几何学上讲,我们将输入的像素视为正方形而非点。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 默认为
None,实际使用 self.align_corners 的值。dtype – 重采样计算的数据类型。默认为
self.dtype或np.float64(以获得最佳精度)。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为 float32。lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
空间秩由
img.ndim -1,len(src_affine) - 1, 和3中的最小值确定。当
monai.config.USE_COMPILED和align_corners都设置为True时,将使用 MONAI 的重采样实现。将 dst_affine 和 spatial_size 设置为 None 以关闭重采样步骤。
- __init__(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
- 参数:
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldtype – 重采样计算的数据类型。默认为
float64以获得最佳精度。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
ResampleToMatch#
- class monai.transforms.ResampleToMatch(mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, lazy=False)[source]#
将图像重采样以匹配给定的元数据。仿射矩阵将对齐,并且输出图像的大小也将匹配。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, img_dst, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- 参数:
img – 要重采样以匹配
img_dst的输入图像。当前支持最多三个空间维度的通道优先数组。mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – 从几何学上讲,我们将输入的像素视为正方形而非点。默认为
None,实际使用 self.align_corners 的值。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – 重采样计算的数据类型。默认为
self.dtype或np.float64(以获得最佳精度)。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为 float32。lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当源图像的仿射矩阵不可逆时。
- 返回值:
重采样的输入张量或 MetaTensor。
Spacing#
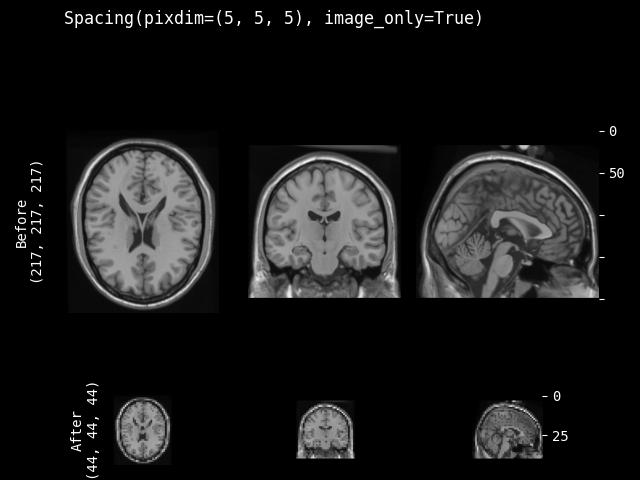
- class monai.transforms.Spacing(pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, lazy=False)[source]#
将输入图像重采样到指定的 pixdim。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data_array, mode=None, padding_mode=None, align_corners=None, dtype=None, scale_extent=None, output_spatial_shape=None, lazy=None)[source]#
- 参数:
data_array – 形状为 (num_channels, H[, W, …])。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"self.mode"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"self.padding_mode"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – 从几何学上讲,我们将输入的像素视为正方形而非点。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 默认为
None,实际使用 self.align_corners 的值。dtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。scale_extent – 缩放是基于间距还是基于体素的完整范围计算。如果在调用此变换时指定了输出空间大小,则忽略此选项。另请参阅:
monai.data.utils.compute_shape_offset()。当此值为 True 时,align_corners 应为 True,因为 compute_shape_offset 已提供角点对齐的移位/缩放。output_spatial_shape – 指定输出 data_array 的形状。这通常用于 Spacingd 的逆变换,有时由于仿射变换引起的量化误差,我们无法计算出确切的形状。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当
data_array没有空间维度时。ValueError – 当
pixdim非正时。
- 返回值:
数据张量或 MetaTensor(重采样到 self.pixdim)。
- __init__(pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, lazy=False)[source]#
- 参数:
pixdim – 输出体素间距。如果提供单个数字,将用于第一维。pixdim 序列中的项映射到输入图像的空间维度,如果 pixdim 序列的长度长于图像空间维度,将忽略较长部分;如果较短,将用最后一个值填充。例如,对于 3D 图像,如果 pixdim 是
[1.0, 2.0],如果 pixdim 的分量是非正值,变换将使用原始 pixdim 的相应分量,该分量根据输入图像的 affine 矩阵计算得出。diagonal –
是否将输入重采样为具有对角仿射矩阵。如果为 True,输入数据将重采样为以下仿射矩阵
np.diag((pixdim_0, pixdim_1, ..., pixdim_n, 1))
这实际上将体积重置为世界坐标系(在 nibabel 中为 RAS+)。原始方向、旋转、剪切均不保留。
如果为 False,此变换将保留原始仿射矩阵中的轴方向、正交旋转和平移分量。此选项不会翻转/交换原始数据的轴。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlalign_corners – 在几何上,我们将输入的像素视为正方形而不是点。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 重采样计算的数据类型。默认为
float64以获得最佳精度。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。scale_extent – 缩放是基于间距还是基于体素的完整范围计算,默认为 False。如果在调用此变换时指定了输出空间大小,则忽略此选项。另请参阅:
monai.data.utils.compute_shape_offset()。当此值为 True 时,align_corners 应为 True,因为 compute_shape_offset 已提供角点对齐的移位/缩放。recompute_affine – 是否根据输出形状重新计算仿射矩阵。解析计算的仿射矩阵不反映输出形状方面的潜在量化误差。将此标志设置为 True 以根据实际 pixdim 重新计算输出仿射矩阵。默认为
False。min_pixdim – 要重采样的最小输入间距。如果提供此值,间距大于此值的输入图像将保留其原始间距(不重采样到 pixdim)。将其设置为 None 以使用 pixdim 的值。默认为 None。
max_pixdim – 要重采样的最大输入间距。如果提供此值,间距小于此值的输入图像将保留其原始间距(不重采样到 pixdim)。将其设置为 None 以使用 pixdim 的值。默认为 None。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Orientation#
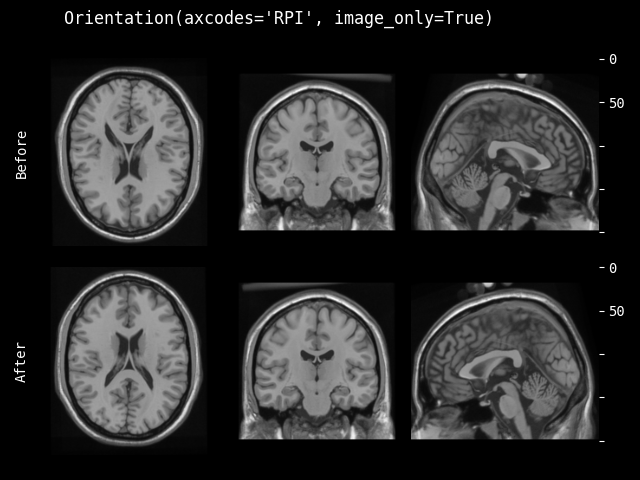
- class monai.transforms.Orientation(axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), lazy=False)[source]#
根据 axcodes 将输入图像的方向更改为指定方向。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data_array, lazy=None)[source]#
如果输入类型为 MetaTensor,则使用 data_array.affine 提取原始仿射矩阵。如果输入类型为 torch.Tensor,则假定原始仿射矩阵为单位矩阵。
- 参数:
data_array – 形状为 (num_channels, H[, W, …])。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当
data_array没有空间维度时。ValueError – 当
axcodes的空间性与data_array不同时。
- 返回值:
- data_array [按 self.axcodes 重定向]. 输出类型将是 MetaTensor
除非 get_track_meta() == False,在这种情况下它将是 torch.Tensor。
- __init__(axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), lazy=False)[source]#
- 参数:
axcodes – 空间 ND 输入方向的 N 个元素序列。例如,axcodes='RAS' 表示 3D 方向:(左,右),(后,前),(下,上)。默认方向标签选项为:第一维的 'L' 和 'R',第二维的 'P' 和 'A',第三维的 'I' 和 'S'。
as_closest_canonical – 如果为 True,则以最接近规范轴格式的方式加载图像。
labels – 可选,None 或 (2,) 序列的序列。(2,) 序列是输出轴的(开始,结束)标签。默认为
(('L', 'R'), ('P', 'A'), ('I', 'S'))。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- 抛出异常:
ValueError – 当
axcodes=None和as_closest_canonical=True时。值不兼容。
另请参阅:nibabel.orientations.ornt2axcodes。
RandRotate#
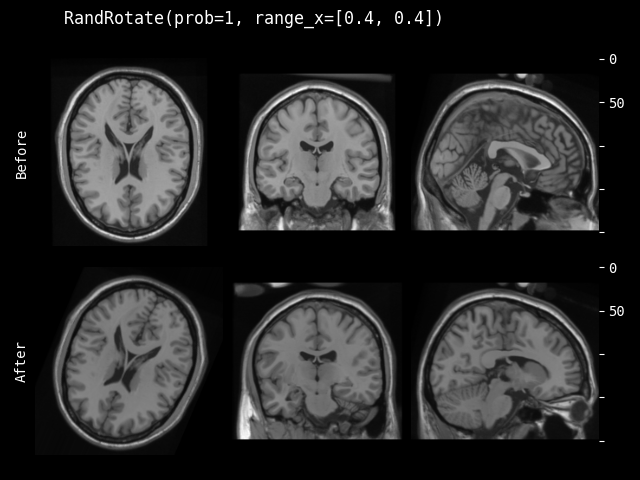
- class monai.transforms.RandRotate(range_x=0.0, range_y=0.0, range_z=0.0, prob=0.1, keep_size=True, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float32'>, lazy=False)[source]#
随机旋转输入数组。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
range_x – 在由第一轴和第二轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_x, range_x) 中均匀采样。
range_y – 在由第一轴和第三轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_y, range_y) 中均匀采样。仅适用于 3D 数据。
range_z – 在由第二轴和第三轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_z, range_z) 中均匀采样。仅适用于 3D 数据。
prob – 旋转的概率。
keep_size – 如果为 False,则调整输出形状以使输入数组完全包含在输出中。如果为 True,则输出形状与输入相同。默认为 True。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, randomize=True, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有以下形状:2D: (nchannels, H, W),或 3D: (nchannels, H, W, D)。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。randomize – 是否先执行 randomize() 函数,默认为 True。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
RandFlip#
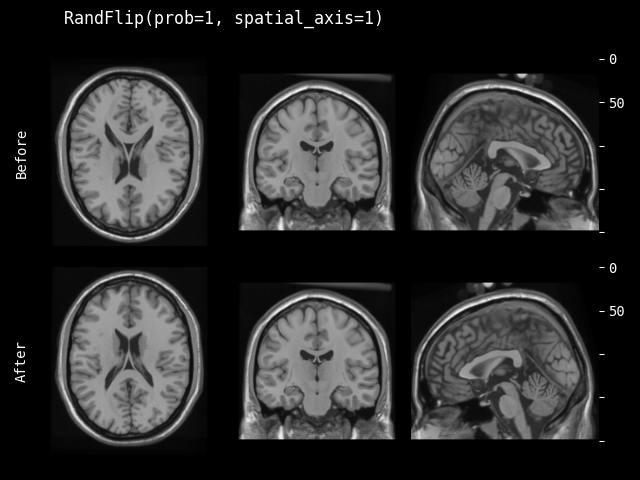
- class monai.transforms.RandFlip(prob=0.1, spatial_axis=None, lazy=False)[source]#
随机沿着轴翻转图像。保留形状。请参阅 numpy.flip 获取更多详情。https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
prob – 翻转的概率。
spatial_axis – 要沿着其翻转的空间轴。默认为 None。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(img, randomize=True, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有形状:(num_channels, H[, W, …, ]),
randomize – 是否先执行 randomize() 函数,默认为 True。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandAxisFlip#
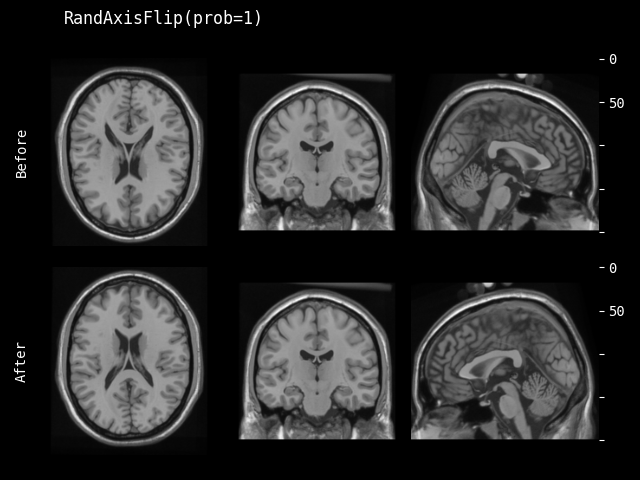
- class monai.transforms.RandAxisFlip(prob=0.1, lazy=False)[source]#
随机选择一个空间轴并沿着它翻转。请参阅 numpy.flip 获取更多详情。https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
prob (
float) – 翻转的概率。lazy (
bool) – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(img, randomize=True, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有形状:(num_channels, H[, W, …, ])
randomize – 是否先执行 randomize() 函数,默认为 True。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandZoom#
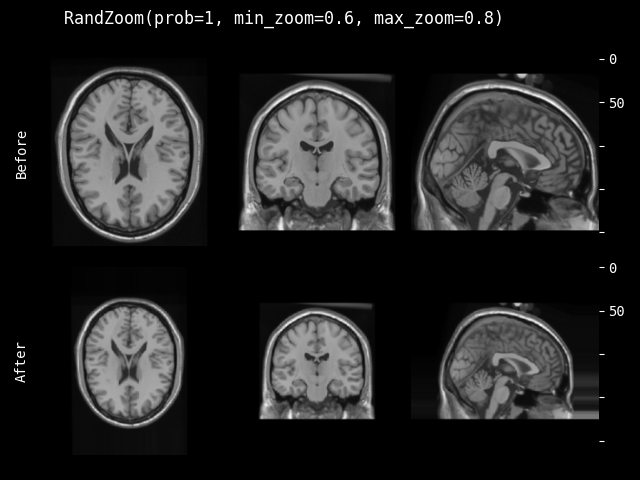
- class monai.transforms.RandZoom(prob=0.1, min_zoom=0.9, max_zoom=1.1, mode=area, padding_mode=edge, align_corners=None, dtype=<class 'torch.float32'>, keep_size=True, lazy=False, **kwargs)[source]#
以给定的概率在给定的缩放范围内随机缩放输入数组。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
prob – 缩放的概率。
min_zoom – 最小缩放因子。可以是浮点数或与图像大小相同的序列。如果为浮点数,则从 [min_zoom, max_zoom] 中选择一个随机因子,然后应用于所有空间维度以保持原始空间形状比例。如果为序列,min_zoom 应包含每个空间轴的一个值。如果为 3D 数据提供了 2 个值,则将第一个值用于 H 和 W 维度以保持相同的缩放比例。
max_zoom – 最大缩放因子。可以是浮点数或与图像大小相同的序列。如果为浮点数,则从 [min_zoom, max_zoom] 中选择一个随机因子,然后应用于所有空间维度以保持原始空间形状比例。如果为序列,max_zoom 应包含每个空间轴的一个值。如果为 3D 数据提供了 2 个值,则将第一个值用于 H 和 W 维度以保持相同的缩放比例。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch 张量的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。缩放后填充数据模式。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为 None。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。keep_size – 是否保持原始大小(如果需要则填充),默认为 True。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, randomize=True, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有以下形状:2D: (nchannels, H, W),或 3D: (nchannels, H, W, D)。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"},插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch 张量的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。缩放后填充数据模式。另请参阅:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmldtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。randomize – 是否先执行 randomize() 函数,默认为 True。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
Affine#
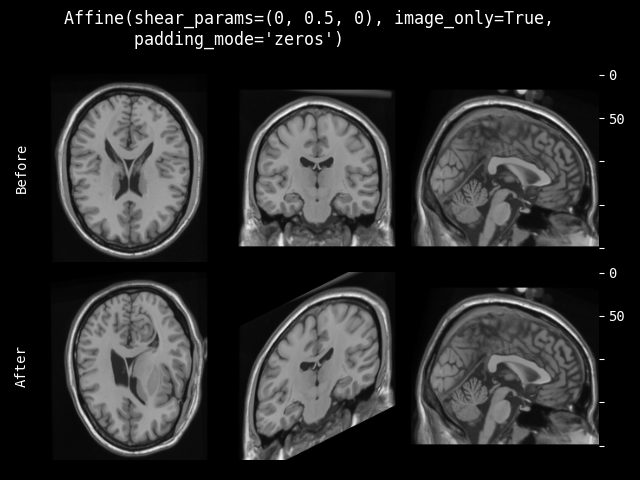
- class monai.transforms.Affine(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, normalized=False, device=None, dtype=<class 'numpy.float32'>, align_corners=False, image_only=False, lazy=False)[source]#
根据仿射参数变换
img。教程可在此处查看:Project-MONAI/tutorials。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, spatial_size=None, mode=None, padding_mode=None, lazy=None)[source]#
- 参数:
img – 形状必须为 (num_channels, H, W[, D]),
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 img 有两个空间维度,spatial_size 应包含 2 个元素 [h, w]。如果 img 有三个空间维度,spatial_size 应包含 3 个元素 [h, w, d]。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmllazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- __init__(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, normalized=False, device=None, dtype=<class 'numpy.float32'>, align_corners=False, image_only=False, lazy=False)[source]#
仿射变换按照旋转、剪切、平移、缩放的顺序应用。
- 参数:
rotate_params – 旋转角度(以弧度为单位),2D 图像为标量,3D 图像为 3 个浮点数的元组。默认为不旋转。
shear_params –
仿射矩阵的剪切因子,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – 2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。平移是以像素/体素为单位,相对于输入图像的中心。默认为不平移。
scale_params – 每个空间维度的缩放因子。2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。默认为 1.0。
affine – 如果应用此参数,则忽略其他参数(rotate_params 等)并使用提供的矩阵。矩阵应为方阵,每边长度等于图像空间维度数 + 1。
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,变换将使用图像大小的相应分量。例如,如果图像的第二个空间维度大小为 64,spatial_size=(32, -1) 将被调整为 (32, 64)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"reflection"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlnormalized – 指示提供的 affine 是否包含一个归一化变换,将坐标从
[-(size-1)/2, (size-1)/2](在create_grid中定义)转换为[0, size - 1]或[-1, 1],以便与底层重采样 API 兼容。如果 normalized=False,将在重采样之前应用额外的坐标归一化。另请参阅:monai.networks.utils.normalize_transform()。device – 张量将分配到的设备。
dtype – 用于重采样计算的数据类型。默认为
float32。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为 float32。align_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
image_only – 如果为 True,则仅返回图像体积,否则返回 (image, affine)。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Resample#
- class monai.transforms.Resample(mode=bilinear, padding_mode=border, norm_coords=True, device=None, align_corners=False, dtype=<class 'numpy.float64'>)[source]#
- __call__(img, grid=None, mode=None, padding_mode=None, dtype=None, align_corners=None)[source]#
- 参数:
img – 形状必须是 (num_channels, H, W[, D])。
grid – 形状必须是 2D 的 (3, H, W) 或 3D 的 (4, H, W, D)。如果
norm_coords为 True,则 grid 值必须在 [-(size-1)/2, (size-1)/2] 范围内。如果USE_COMPILED=True且norm_coords=False,则 grid 值必须在 [0, size-1] 范围内。如果USE_COMPILED=False且norm_coords=False,则 grid 值必须在 [-1, 1] 范围内。mode – {
"bilinear","nearest"} 或 spline 插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 USE_COMPILED 为 True 时,此参数使用"nearest","bilinear","bicubic"来表示 0, 1, 3 阶插值。另请参阅:https://docs.monai.org.cn/en/stable/networks.html#grid-pull (实验性)。当它是一个整数时,将使用 numpy(cpu tensor)/cupy(cuda tensor)后端,该值表示 spline 插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 USE_COMPILED 为 True 时,此参数使用整数来表示填充模式。另请参阅:https://docs.monai.org.cn/en/stable/networks.html#grid-pull (实验性)。当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldtype – 用于重采样计算的数据类型。默认为
self.dtype。为了与其他模块兼容,输出数据类型始终为 float32。align_corners – 默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
另请参阅
monai.config.USE_COMPILED
- __init__(mode=bilinear, padding_mode=border, norm_coords=True, device=None, align_corners=False, dtype=<class 'numpy.float64'>)[source]#
使用 pytorch 根据 img 中的值和 grid 中的位置计算输出图像。支持空间 2D 或 3D(num_channels, H, W[, D])。
- 参数:
mode – {
"bilinear","nearest"} 或 spline 插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 USE_COMPILED 为 True 时,此参数使用"nearest","bilinear","bicubic"来表示 0, 1, 3 阶插值。另请参阅:https://docs.monai.org.cn/en/stable/networks.html#grid-pull (实验性)。当它是一个整数时,将使用 numpy(cpu tensor)/cupy(cuda tensor)后端,该值表示 spline 插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 USE_COMPILED 为 True 时,此参数使用整数来表示填充模式。另请参阅:https://docs.monai.org.cn/en/stable/networks.html#grid-pull (实验性)。当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlnorm_coords – 是否将坐标从 [-(size-1)/2, (size-1)/2] 归一化到 [0, size - 1](用于
monai/csrc实现)或 [-1, 1](用于 torchgrid_sample实现),以与底层重采样 API 兼容。device – 张量将分配到的设备。
align_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 用于重采样计算的数据类型。为获得最佳精度,默认为
float64。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为 float32。
RandAffine#
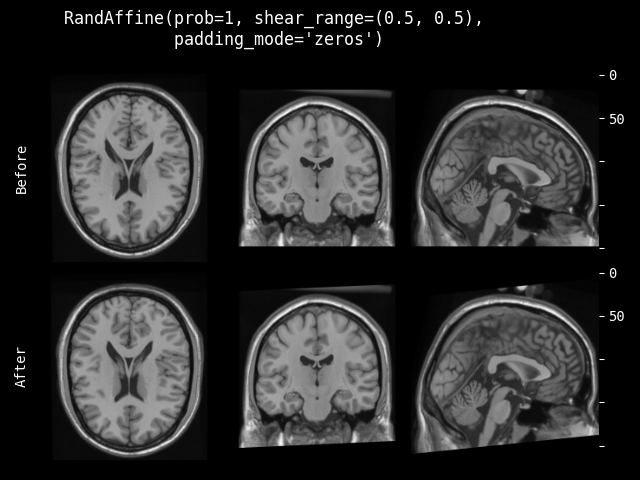
- class monai.transforms.RandAffine(prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, lazy=False)[source]#
随机仿射变换。教程请参见:Project-MONAI/tutorials。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True, grid=None, lazy=None)[source]#
- 参数:
img – 形状必须为 (num_channels, H, W[, D]),
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 img 有两个空间维度,spatial_size 应包含 2 个元素 [h, w]。如果 img 有三个空间维度,spatial_size 应包含 3 个元素 [h, w, d]。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – 是否先执行 randomize() 函数,默认为 True。
grid – 要使用的预计算网格(主要用于加速 RandAffined)。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- __init__(prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, lazy=False)[source]#
- 参数:
prob – 返回随机仿射网格的概率。默认为 0.1,即有 10% 的机会返回随机网格。
rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(2D 为包含 2 个浮点数的元组,3D 为包含 6 个浮点数的元组)的范围,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移像素/体素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,变换将使用图像大小的相应分量。例如,如果图像的第二个空间维度大小为 64,spatial_size=(32, -1) 将被调整为 (32, 64)。
mode – {
"bilinear","nearest"} 或 spline 插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为bilinear。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(cpu tensor)/cupy(cuda tensor)后端,该值表示 spline 插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为reflection。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlcache_grid – 是否缓存恒等采样网格。如果空间大小不由输入图像动态定义,启用此选项可以加速变换。
device – 张量将分配到的设备。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
另请参阅
关于随机仿射参数配置,请参阅
RandAffineGrid。关于仿射变换参数配置,请参阅
Affine。
- get_identity_grid(spatial_size, lazy)[source]#
根据可用性返回缓存的或新的恒等网格。
- 参数:
spatial_size (
Sequence[int]) – 非动态空间大小
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandDeformGrid#
- class monai.transforms.RandDeformGrid(spacing, magnitude_range, device=None)[source]#
生成随机形变网格。
AffineGrid#
- class monai.transforms.AffineGrid(rotate_params=None, shear_params=None, translate_params=None, scale_params=None, device=None, dtype=<class 'numpy.float32'>, align_corners=False, affine=None, lazy=False)[source]#
坐标上的仿射变换。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
rotate_params – 旋转角度(以弧度为单位),2D 图像为标量,3D 图像为 3 个浮点数的元组。默认为不旋转。
shear_params –
仿射矩阵的剪切因子,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – 2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。平移是以像素/体素为单位,相对于输入图像的中心。默认为不平移。
scale_params – 每个空间维度的缩放因子。2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。默认为 1.0。
dtype – 网格计算的数据类型。默认为
float32。如果为None,则使用输入数据的数据类型(如果提供了 grid)。device – 如果生成新网格,tensor 将分配到的设备。
align_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
affine – 如果应用此参数,则忽略其他参数(rotate_params 等)并使用提供的矩阵。矩阵应为方阵,每边长度等于图像空间维度数 + 1。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(spatial_size=None, grid=None, lazy=None)[source]#
网格可以通过 spatial_size 参数初始化,或直接提供 grid。因此,必须提供 spatial_size 或 grid 中的一个。从 spatial_size 初始化时,将使用“torch”后端。
- 参数:
spatial_size – 输出网格大小。
grid – 要变换的网格。2D 形状必须是 (3, H, W),3D 形状必须是 (4, H, W, D)。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当
grid=None且spatial_size=None时。值不兼容。
RandAffineGrid#
- class monai.transforms.RandAffineGrid(rotate_range=None, shear_range=None, translate_range=None, scale_range=None, device=None, dtype=<class 'numpy.float32'>, lazy=False)[source]#
生成随机仿射网格。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(spatial_size=None, grid=None, randomize=True, lazy=None)[source]#
- 参数:
spatial_size – 输出网格大小。
grid – 要变换的网格。2D 形状必须是 (3, H, W),3D 形状必须是 (4, H, W, D)。
randomize – 控制网格参数是否应该随机化的布尔值。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
2D (3xHxW) 或 3D (4xHxWxD) 网格。
- __init__(rotate_range=None, shear_range=None, translate_range=None, scale_range=None, device=None, dtype=<class 'numpy.float32'>, lazy=False)[source]#
- 参数:
rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(2D 为包含 2 个浮点数的元组,3D 为包含 6 个浮点数的元组)的范围,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择体素进行平移的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
device – 用于存储输出网格数据的设备。
dtype – 网格计算的数据类型。默认为
np.float32。如果为None,则使用输入数据的数据类型(如果提供了 grid)。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
GridDistortion#
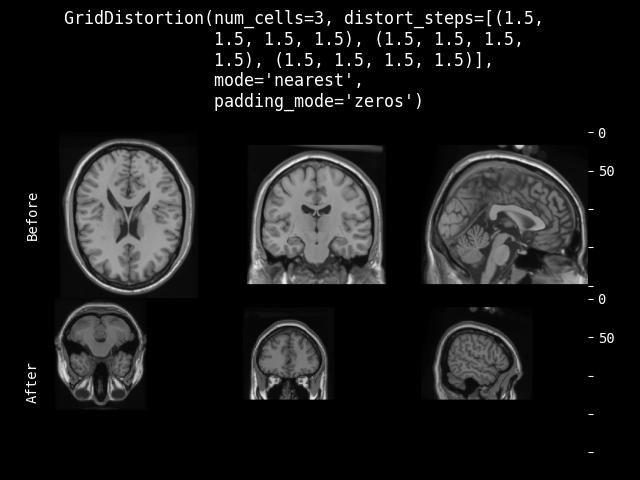
- class monai.transforms.GridDistortion(num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None)[source]#
- __call__(img, distort_steps=None, mode=None, padding_mode=None)[source]#
- 参数:
img – 形状必须是 (num_channels, H, W[, D])。
distort_steps – 此参数是一个元组列表,其中每个元组包含相应维度(按 H, W[, D] 的顺序)的形变步长。每个元组的长度等于 num_cells + 1。元组中的每个值表示相关单元格的形变步长。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html
- __init__(num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None)[source]#
网格形变变换。参考:albumentations-team/albumentations
- 参数:
num_cells – 每个维度的网格单元数。
distort_steps – 此参数是一个元组列表,其中每个元组包含相应维度(按 H, W[, D] 的顺序)的形变步长。每个元组的长度等于 num_cells + 1。元组中的每个值表示相关单元格的形变步长。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – 张量将分配到的设备。
RandGridDistortion#
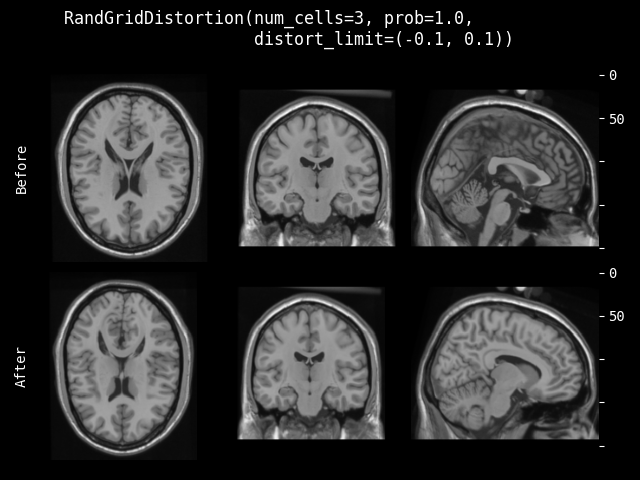
- class monai.transforms.RandGridDistortion(num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None)[source]#
- __call__(img, mode=None, padding_mode=None, randomize=True)[source]#
- 参数:
img – 形状必须是 (num_channels, H, W[, D])。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – 是否使用 randomize() 打乱随机因子,默认为 True。
- __init__(num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None)[source]#
随机网格形变变换。参考:albumentations-team/albumentations
- 参数:
num_cells – 每个维度的网格单元数。
prob – 返回随机网格形变变换的概率。默认为 0.1。
distort_limit – 随机形变的范围。如果是一个数字,则形变限制从 (-distort_limit, distort_limit) 中选择。默认为 (-0.03, 0.03)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – 张量将分配到的设备。
Rand2DElastic#
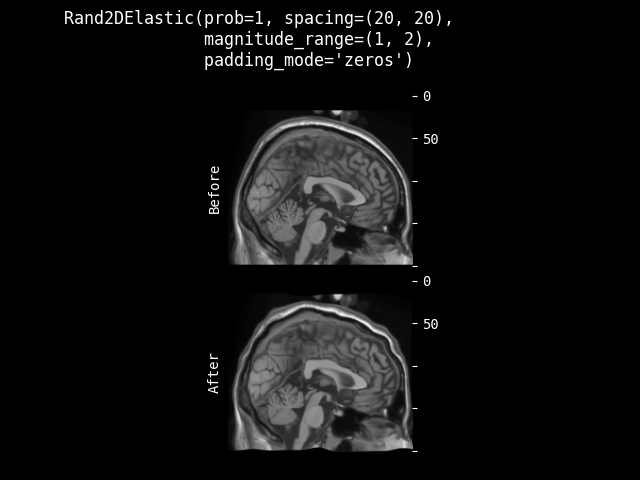
- class monai.transforms.Rand2DElastic(spacing, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
2D 中的随机弹性形变和仿射变换。教程请参见:Project-MONAI/tutorials。
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True)[source]#
- 参数:
img – 形状必须是 (num_channels, H, W),
spatial_size – 指定输出图像空间大小 [h, w]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – 是否先执行 randomize() 函数,默认为 True。
- __init__(spacing, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
- 参数:
spacing – 控制点之间的距离。
magnitude_range – 随机偏移将从
uniform[magnitude[0], magnitude[1])中生成。prob – 返回随机弹性变换的概率。默认为 0.1,即有 10% 的机会返回随机弹性变换,否则返回从输入图像提取的
spatial_size中心区域。rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(2D 为包含 2 个浮点数的元组)的范围,以 2D 仿射为例
[ [1.0, params[0], 0.0], [params[1], 1.0, 0.0], [0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移像素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
spatial_size – 指定输出图像空间大小 [h, w]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"reflection"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – 张量将分配到的设备。
另请参阅
关于随机仿射参数配置,请参阅
RandAffineGrid。关于仿射变换参数配置,请参阅
Affine。
Rand3DElastic#
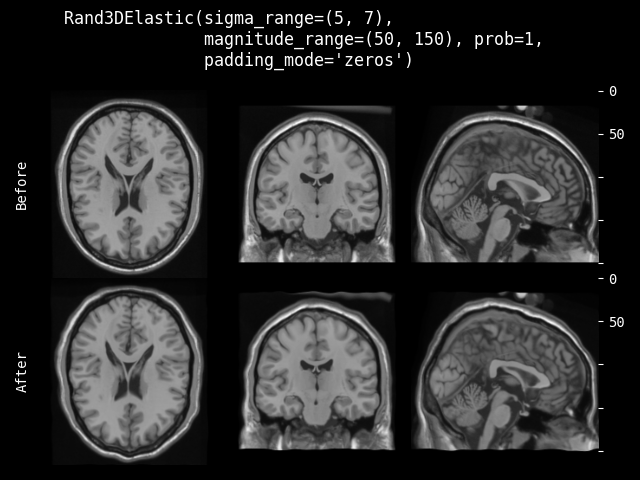
- class monai.transforms.Rand3DElastic(sigma_range, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
3D 中的随机弹性形变和仿射变换。教程请参见:Project-MONAI/tutorials。
- __call__(img, spatial_size=None, mode=None, padding_mode=None, randomize=True)[source]#
- 参数:
img – 形状必须是 (num_channels, H, W, D),
spatial_size – 指定空间 3D 输出图像空间大小 [h, w, d]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第三个空间维度大小为 64,则 spatial_size=(32, 32, -1) 将调整为 (32, 32, 64)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlrandomize – 是否先执行 randomize() 函数,默认为 True。
- __init__(sigma_range, magnitude_range, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None)[source]#
- 参数:
sigma_range – 将使用从
uniform[sigma_range[0], sigma_range[1])中采样的标准差的高斯核来平滑随机偏移网格。magnitude_range – 网格上的随机偏移将从
uniform[magnitude[0], magnitude[1])中生成。prob – 返回随机弹性变换的概率。默认为 0.1,即有 10% 的机会返回随机弹性变换,否则返回从输入图像提取的
spatial_size中心区域。rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(3D 为包含 6 个浮点数的元组)的范围,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移体素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
spatial_size – 指定空间 3D 输出图像空间大小 [h, w, d]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第三个空间维度大小为 64,则 spatial_size=(32, 32, -1) 将调整为 (32, 32, 64)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是一个整数时,将使用 numpy(CPU 张量)/cupy(CUDA 张量)后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"reflection"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是一个整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.htmldevice – 张量将分配到的设备。
另请参阅
关于随机仿射参数配置,请参阅
RandAffineGrid。关于仿射变换参数配置,请参阅
Affine。
Rotate90#
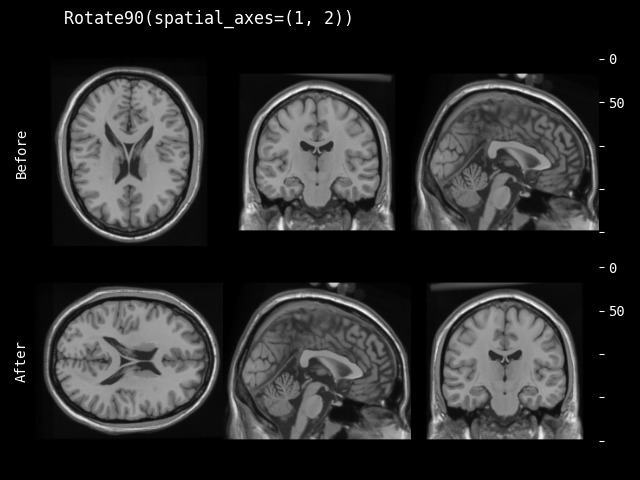
- class monai.transforms.Rotate90(k=1, spatial_axes=(0, 1), lazy=False)[source]#
在由 axes 指定的平面上将数组旋转 90 度。有关更多详细信息,请参见 torch.rot90:https://pytorch.ac.cn/docs/stable/generated/torch.rot90.html#torch-rot90。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有形状:(num_channels, H[, W, …, ]),
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
RandRotate90#
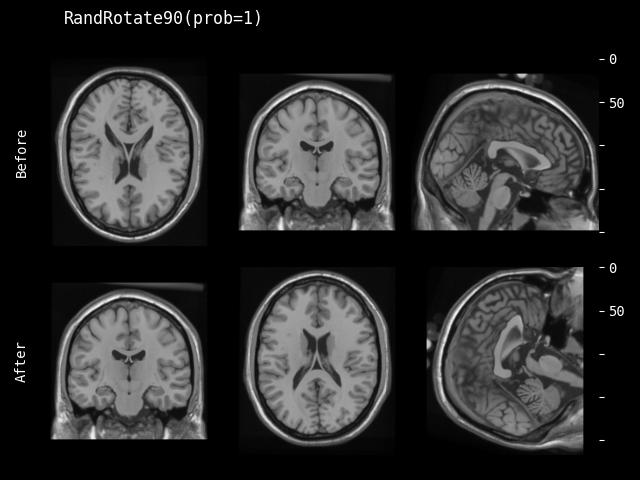
- class monai.transforms.RandRotate90(prob=0.1, max_k=3, spatial_axes=(0, 1), lazy=False)[source]#
以 prob 的概率在由 spatial_axes 指定的平面上将输入数组旋转 90 度。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(img, randomize=True, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有形状:(num_channels, H[, W, …, ]),
randomize – 是否先执行 randomize() 函数,默认为 True。
lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- __init__(prob=0.1, max_k=3, spatial_axes=(0, 1), lazy=False)[source]#
- 参数:
prob (
float) – 旋转的概率。(默认为 0.1,有 10% 的概率返回旋转后的数组)max_k (
int) – 旋转次数将从 np.random.randint(max_k) + 1 中采样(默认为 3)。spatial_axes (
tuple[int,int]) – 两个整数,定义了使用两个空间轴进行旋转的平面。默认值:(0, 1),这是空间维度中的前两个轴。lazy (
bool) – 一个标志,指示此变换是否应延迟执行。默认为 False
翻转#
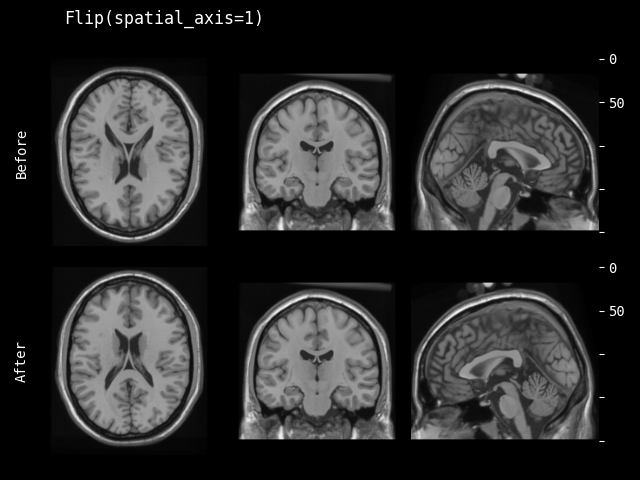
- class monai.transforms.Flip(spatial_axis=None, lazy=False)[source]#
沿给定空间轴反转元素的顺序。保留形状。有关更多详细信息,请参阅 torch.flip 文档: https://pytorch.ac.cn/docs/stable/generated/torch.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_axis – 沿其进行翻转的空间轴。默认为 None。默认的 axis=None 将翻转输入数组的所有轴。如果轴是负数,则从最后一个轴计数到第一个轴。如果轴是整数元组,则在元组中指定的所有轴上执行翻转。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
改变大小#
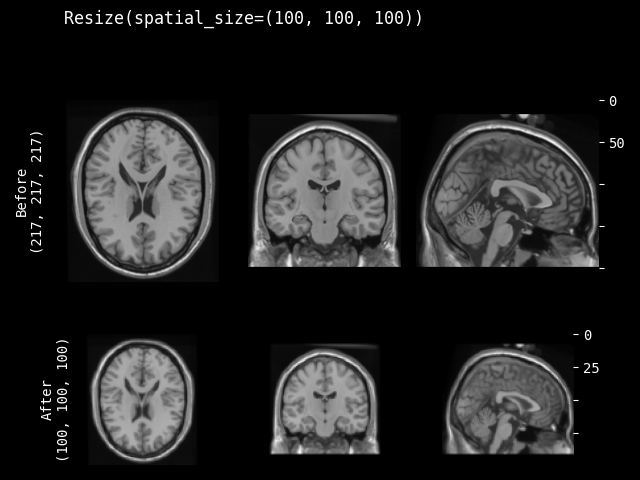
- class monai.transforms.Resize(spatial_size, size_mode='all', mode=area, align_corners=None, anti_aliasing=False, anti_aliasing_sigma=None, dtype=torch.float32, lazy=False)[source]#
将输入图像改变到给定的空间大小(进行缩放,而非裁剪/填充)。使用
torch.nn.functional.interpolate实现。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
spatial_size – 改变大小操作后空间维度的预期形状。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将被调整为 (32, 64)。
size_mode – 应为“all”或“longest”,如果是“all”,将对所有空间维度使用 spatial_size,如果是“longest”,则缩放图像,使最长边等于指定的 spatial_size(在这种情况下必须是整数),同时保持原始图像的纵横比,请参阅: https://albumentations.ai/docs/api_reference/augmentations/geometric/resize/ #albumentations.augmentations.geometric.resize.LongestMaxSize。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为 None。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html
anti_aliasing – 布尔值,指示是否在下采样之前应用高斯滤波器平滑图像。在对图像进行下采样时进行滤波以避免混叠伪影至关重要。另请参阅
skimage.transform.resizeanti_aliasing_sigma – {float, 浮点数元组},可选,用于抗锯齿时使用的高斯滤波器的标准差。默认情况下,此值选择为 (s - 1) / 2,其中 s 是下采样因子,且 s > 1。对于放大情况 (s < 1),在重新缩放之前不执行抗锯齿。
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(img, mode=None, align_corners=None, anti_aliasing=None, anti_aliasing_sigma=None, dtype=None, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有以下形状:(num_channels, H[, W, …, ])。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为self.mode。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlanti_aliasing – 布尔值,可选,指示是否在下采样之前应用高斯滤波器平滑图像。在对图像进行下采样时进行滤波以避免混叠伪影至关重要。另请参阅
skimage.transform.resizeanti_aliasing_sigma – {float, 浮点数元组},可选,用于抗锯齿时使用的高斯滤波器的标准差。默认情况下,此值选择为 (s - 1) / 2,其中 s 是下采样因子,且 s > 1。对于放大情况 (s < 1),在重新缩放之前不执行抗锯齿。
dtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当
self.spatial_size的长度小于img的空间维度时。
旋转#
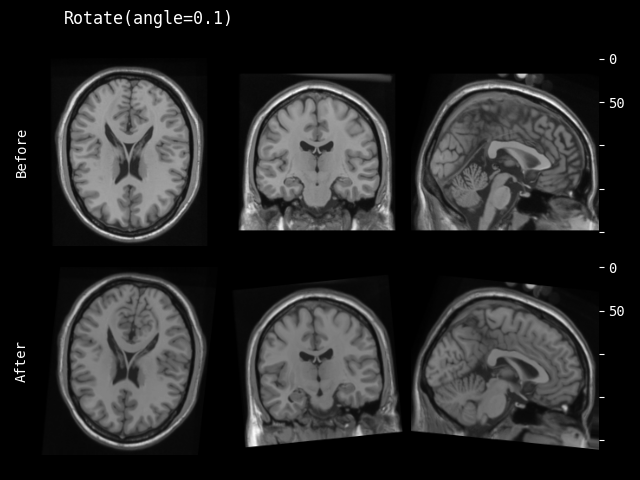
- class monai.transforms.Rotate(angle, keep_size=True, mode=bilinear, padding_mode=border, align_corners=False, dtype=torch.float32, lazy=False)[source]#
使用
monai.networks.layers.AffineTransform按给定角度旋转输入图像。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
angle – 旋转角度(弧度)。对于 2D 应为 float,对于 3D 应为三个 floats。
keep_size – 如果为 True,则输出形状与输入保持相同。如果为 False,则调整输出形状,以便输入数组完全包含在输出中。默认为 True。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有以下形状:[chns, H, W] 或 [chns, H, W, D]。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为self.mode。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlpadding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为self.padding_mode。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html align_corners:默认为self.align_corners。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmlalign_corners – 默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.htmldtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 抛出异常:
ValueError – 当
img的空间维度不是 [2D, 3D] 之一时。
缩放#
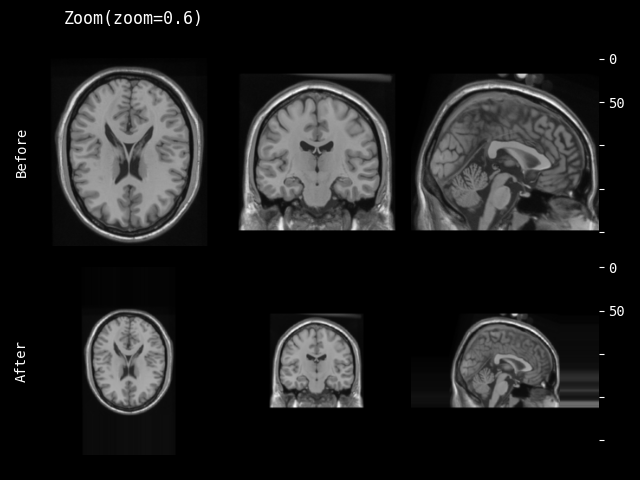
- class monai.transforms.Zoom(zoom, mode=area, padding_mode=edge, align_corners=None, dtype=torch.float32, keep_size=True, lazy=False, **kwargs)[source]#
使用
torch.nn.functional.interpolate缩放 ND 图像。详情请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html。与
monai.transforms.resize不同,此变换将缩放因子作为输入,并提供保持输入空间大小的选项。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
zoom – 沿空间轴的缩放因子。如果是浮点数,则每个空间轴的缩放因子相同。如果是序列,则 zoom 应包含每个空间轴的一个值。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – 可用于 numpy 数组的模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} 可用于 PyTorch Tensor 的模式:{"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为"edge"。缩放后填充数据所用的模式。另请参阅: https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为 None。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。keep_size – 是否应保持原始大小(如果需要,进行填充/切片),默认为 True。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- __call__(img, mode=None, padding_mode=None, align_corners=None, dtype=None, lazy=None)[source]#
- 参数:
img – 通道优先数组,必须具有以下形状:(num_channels, H[, W, …, ])。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为self.mode。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmlpadding_mode – 可用于 numpy 数组的模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} 可用于 PyTorch Tensor 的模式:{"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为"edge"。缩放后填充数据所用的模式。另请参阅: https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅当 mode 为 ‘linear’, ‘bilinear’, ‘bicubic’ 或 ‘trilinear’ 时有效。默认为
self.align_corners。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.htmldtype – 重采样计算的数据类型。默认为
self.dtype。如果为 None,则使用输入数据的数据类型。lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
网格分块#
- class monai.transforms.GridPatch(patch_size, offset=None, num_patches=None, overlap=0.0, sort_fn=None, threshold=None, pad_mode=None, **pad_kwargs)[source]#
以行主序滑动窗口的方式提取扫描整个图像的所有分块,可能存在重叠。它可以对分块进行排序并返回全部或部分分块。
- 参数:
patch_size – 用于生成切片的分块大小,0 或 None 选择整个维度
offset – 数组中起始位置的偏移量,默认为每个维度为 0。
num_patches – 要返回的分块数量(或最大分块数量)。如果请求的分块数量大于可用分块数量,除非设置了 threshold,否则将应用填充以精确提供 num_patches 个分块。当设置了 threshold 时,此值被视为最大分块数量。默认为 None,表示不限制分块数量。
overlap – 每个维度中相邻分块的重叠量(0.0 到 1.0 之间的值)。如果只给出一个浮点数,它将应用于所有维度。默认为 0.0。
sort_fn – 当提供了 num_patches 时,它决定是保留具有最高值的分块 (“max”)、最低值的 (“min”),还是按默认顺序 (None)。默认为 None。
threshold – 一个值,只保留强度总和小于该阈值的分块。默认为不进行过滤。
pad_mode – 根据 patch_size 填充输入图像以包含跨越边界的分块的模式。可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"}(PyTorch){"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为 None,表示不应用填充。另请参阅: https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 需要 pytorch >= 1.10 以获得最佳兼容性。pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回值:
- 提取的分块作为一个单独的张量(分块维度作为第一维度),
包含以下元数据
PatchKeys.LOCATION:分块在图像中的起始位置,
PatchKeys.COUNT:图像中的分块总数,
“spatial_shape”:提取的分块的空间大小,以及
“offset”:图像中分块的偏移量(第一个分块的起始位置)
- 返回类型:
- __call__(array)[source]#
提取分块(以行主序滑动窗口的方式扫描整个图像,可能存在重叠)。
- 参数:
array (
Union[ndarray,Tensor]) – 一个输入图像,可以是 numpy.ndarray 或 torch.Tensor- 返回值:
- 提取的分块作为一个单独的张量(分块维度作为第一维度),
包含已定义的 PatchKeys.LOCATION 和 PatchKeys.COUNT 元数据。
- 返回类型:
随机网格分块#
- class monai.transforms.RandGridPatch(patch_size, min_offset=None, max_offset=None, num_patches=None, overlap=0.0, sort_fn=None, threshold=None, pad_mode=None, **pad_kwargs)[source]#
以行主序滑动窗口的方式提取扫描整个图像的所有分块,可能存在重叠,并对图像的最小角(2D 为 (0,0),3D 为 (0,0,0))应用随机偏移。它可以对分块进行排序并返回全部或部分分块。
- 参数:
patch_size – 用于生成切片的分块大小,0 或 None 选择整个维度
min_offset – 随机选择的最小偏移范围。默认为 0。
max_offset – 随机选择的最大偏移范围。默认为图像大小模分块大小。
num_patches – 要返回的分块数量(或最大分块数量)。如果请求的分块数量大于可用分块数量,除非设置了 threshold,否则将应用填充以精确提供 num_patches 个分块。当设置了 threshold 时,此值被视为最大分块数量。默认为 None,表示不限制分块数量。
overlap – 每个维度中相邻分块的重叠量(0.0 到 1.0 之间的值)。如果只给出一个浮点数,它将应用于所有维度。默认为 0.0。
sort_fn – 当提供了 num_patches 时,它决定是保留具有最高值的分块 (“max”)、最低值的 (“min”)、随机的 (“random”),还是按默认顺序 (None)。默认为 None。
threshold – 一个值,只保留强度总和小于该阈值的分块。默认为不进行过滤。
pad_mode – 根据 patch_size 填充输入图像以包含跨越边界的分块的模式。可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"}(PyTorch){"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为 None,表示不应用填充。另请参阅: https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 需要 pytorch >= 1.10 以获得最佳兼容性。pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回值:
- 提取的分块作为一个单独的张量(分块维度作为第一维度),
包含以下元数据
PatchKeys.LOCATION:分块在图像中的起始位置,
PatchKeys.COUNT:图像中的分块总数,
“spatial_shape”:提取的分块的空间大小,以及
“offset”:图像中分块的偏移量(第一个分块的起始位置)
- 返回类型:
- __call__(array, randomize=True)[source]#
提取分块(以行主序滑动窗口的方式扫描整个图像,可能存在重叠)。
- 参数:
array (
Union[ndarray,Tensor]) – 一个输入图像,可以是 numpy.ndarray 或 torch.Tensor- 返回值:
- 提取的分块作为一个单独的张量(分块维度作为第一维度),
包含已定义的 PatchKeys.LOCATION 和 PatchKeys.COUNT 元数据。
- 返回类型:
网格分割#
- class monai.transforms.GridSplit(grid=(2, 2), size=None)[source]#
根据提供的网格将图像分割成 2D 分块。
- 参数:
grid – 定义用于分割图像的网格形状的元组。默认为 (2, 2)
size – 定义输出分块大小的元组或整数。如果是整数,则该值将应用于每个维度。默认值为 None,此时分块大小将从网格形状推断。
示例
给定一个大小为 (3, 10, 10) 的图像 (torch.Tensor 或 numpy.ndarray) 和一个 (2, 2) 的网格,它将返回一个大小为 (4, 3, 5, 5) 的 Tensor 或数组。在这里,如果提供了 size,则返回的形状将是 (4, 3, size, size)。
注意:此变换目前仅支持具有两个空间维度的图像。
- __call__(image, size=None)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
随机模拟低分辨率#
- class monai.transforms.RandSimulateLowResolution(prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, device=None)[source]#
随机模拟低分辨率,对应于 nnU-Net 的 SimulateLowResolutionTransform (MIC-DKFZ/batchgenerators)。首先,根据从 zoom_range 中均匀采样的 zoom_factor 确定并以较低分辨率对数组/张量进行重采样。然后,以原始分辨率对数组/张量进行重采样。
- __call__(img, randomize=True)[source]#
- 参数:
img (
Tensor) – 形状必须为 (num_channels, H, W[, D]),randomize (
bool) – 是否首先执行 randomize() 函数,默认为 True。
- 返回类型:
Tensor
- __init__(prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, device=None)[source]#
- 参数:
prob – 执行此增强的概率
downsample_mode – 下采样操作的插值模式
upsample_mode – 上采样操作的插值模式
zoom_range – 用于下采样和上采样操作的随机缩放因子的范围,
张量。 (从中采样。它决定了下采样张量的形状)
align_corners – 仅当 downsample_mode 或 upsample_mode 为 'linear'、'bilinear'、'bicubic' 或 'trilinear' 时有效。默认值:False 另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html
device – 张量将分配到的设备。
将包围盒转换为点#
- class monai.transforms.ConvertBoxToPoints(mode=None)[source]#
将轴对齐的包围盒转换为点。它可以根据包围盒模式自动将包围盒转换为点。N 个包围盒的形状为 (N, C)。对于每个包围盒,C 在 2D 中是 [x1, y1, x2, y2],在 3D 中是 [x1, y1, z1, x2, y2, z2]。返回形状在 2D 中是 (N, 4, 2),在 3D 中是 (N, 8, 3)。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
将点转换为包围盒#
- class monai.transforms.ConvertPointsToBoxes[source]#
将点转换为轴对齐的包围盒。点表示包围盒的角点。对于 3D 长方体的 8 个角点,形状为 (N, 8, 3);对于 2D 矩形的 4 个角点,形状为 (N, 4, 2)。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
平滑场#
随机平滑场对比度调整#
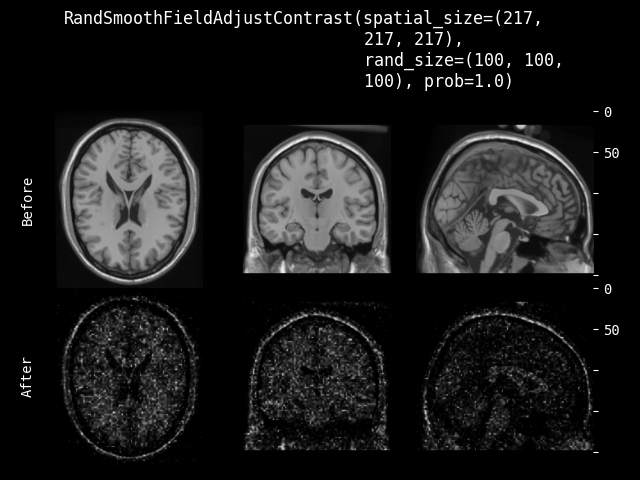
- class monai.transforms.RandSmoothFieldAdjustContrast(spatial_size, rand_size, pad=0, mode=area, align_corners=None, prob=0.1, gamma=(0.5, 4.5), device=None)[source]#
通过为每次调用计算随机平滑场来随机调整输入图像的对比度。
这在内部使用 SmoothField 来定义图像上的调整。如果 pad 大于 0,则该宽度的输入体边缘将基本保持不变。对比度通过将输入值提升到平滑场的幂来改变,因此应考虑到这一点选择 gamma 给定的值范围。例如,gamma 中的最小值 0 将产生白色区域,因此应避免这种情况。调整对比度后,结果值将重新缩放到原始输入的范围。
- 参数:
spatial_size – 输入数组空间维度的大小
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 1 填充的像素/体素数量
mode – 上采样时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
gamma – 指数场的 (min, max) 范围
device – 用于定义场的 Pytorch 设备
- __call__(img, randomize=True)[source]#
将变换应用于 img,如果 randomize 为 True 则随机化平滑场,否则重用之前的值。
- 返回类型:
Union[ndarray,Tensor]
随机平滑场强度调整#
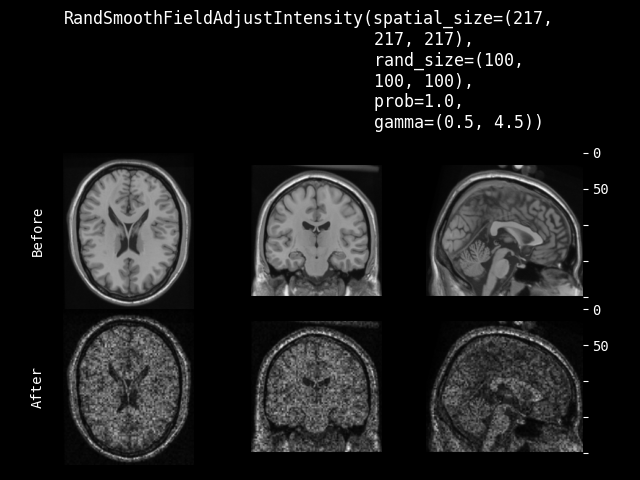
- class monai.transforms.RandSmoothFieldAdjustIntensity(spatial_size, rand_size, pad=0, mode=area, align_corners=None, prob=0.1, gamma=(0.1, 1.0), device=None)[source]#
通过为每次调用计算随机平滑场来随机调整输入图像的强度。
这在内部使用 SmoothField 来定义图像上的调整。如果 pad 大于 0,则该宽度的输入体边缘将基本保持不变。强度通过将输入乘以平滑场来改变,因此应考虑到这一点选择 gamma 的值。默认值 (0.1, 1.0) 是合理的,因为值既不会被场归零,也不会乘以超过原始值范围。
- 参数:
spatial_size – 输入数组的大小
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 1 填充的像素/体素数量
mode – 上采样时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
gamma – 强度乘数范围 (min, max)
device – 用于定义场的 Pytorch 设备
- __call__(img, randomize=True)[source]#
将变换应用于 img,如果 randomize 为 True 则随机化平滑场,否则重用之前的值。
- 返回类型:
Union[ndarray,Tensor]
随机平滑形变#

- class monai.transforms.RandSmoothDeform(spatial_size, rand_size, pad=0, field_mode=area, align_corners=None, prob=0.1, def_range=1.0, grid_dtype=torch.float32, grid_mode=nearest, grid_padding_mode=border, grid_align_corners=False, device=None)[source]#
使用随机平滑场和 Pytorch 的 grid_sample 对图像进行形变。
形变量由图像大小的 def_range 分数给出。无论实际图像体素维度如何,输入图像每个维度的大小始终定义为 2,即每个维度的坐标范围从 -1 到 1。值为 0.1 表示像素/体素最多可以移动图像大小的 5%。
- 参数:
spatial_size – 用于插值形变网格的输入数组大小
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 0 填充的像素/体素数量
field_mode – 上采样形变场时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
def_range – 形变范围在图像大小分数中的值,可以是单个 min/max 值或 min/max 对
grid_dtype – 根据场计算出的形变网格的类型
grid_mode – 使用形变网格对输入进行采样时使用的插值模式
grid_padding_mode – 使用形变网格对输入进行采样时使用的填充模式
grid_align_corners – 如果为 True,则在对形变网格采样时对齐角点
device – 用于定义场的 Pytorch 设备
- __call__(img, randomize=True, device=None)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
MRI 变换#
k空间欠采样#
- class monai.apps.reconstruction.transforms.array.KspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
一个用于欠采样掩模设置的基本类。它为欠采样掩模生成器提供了通用功能。例如,RandomKspacemask 和 EquispacedMaskFunc(在此模块之后定义的两个掩模变换对象)都继承了 KspaceMask,以便正确设置诸如加速因子等属性。
- abstract __call__(kspace)[source]#
这是为了定义新的掩模生成器而提供的额外实例。要创建其他掩模变换,只需定义一个新类并重写 __call__。请参阅示例:
monai.apps.reconstruction.transforms.array.RandomKspacemask。- 参数:
kspace (
Union[ndarray,Tensor]) – 输入的 k 空间数据。对于复杂的 2D 输入,形状为 (…,num_coils,H,W,2);对于真实的 3D 数据,形状为 (…,num_coils,H,W,D)。- 返回类型:
Sequence[Tensor]
- __init__(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
- 参数:
center_fractions (
Sequence[float]) – 要保留的低频列的分数。如果提供了多个值,则每次均匀选择其中一个。accelerations (
Sequence[float]) – 欠采样量。这应与 center_fractions 具有相同的长度。如果提供了多个值,则每次均匀选择其中一个。spatial_dims (
int) – 空间维度数量(例如,2D 数据为 2;对于 pseudo-3D 数据集(如 fastMRI 数据集)也为 2)。选择最后一个空间维度进行采样。对于 fastMRI 数据集,k 空间的形状为 (…,num_slices,num_coils,H,W),沿 W 进行采样。对于形状为 (…,num_coils,H,W,D) 的一般 3D 数据,沿 D 进行采样。is_complex (
bool) – 如果为 True,则最后一个维度将保留用于实部/虚部。
- class monai.apps.reconstruction.transforms.array.RandomKspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
此 k-space 掩膜变换根据随机采样模式对 k-space 进行欠采样。具体而言,它从输入 k-space 数据中均匀选择一部分列。如果 k-space 数据有 N 列,掩膜会选取
1. N_low_freqs = (N * center_fraction) 位于中心处对应于低频的列
2. 其余列以等于以下概率的方式均匀随机选择: prob = (N / acceleration - N_low_freqs) / (N - N_low_freqs)。这确保了所选列的期望数量等于 (N / acceleration)
可以使用多个 center_fractions 和 accelerations,在这种情况下,每次调用变换时会均匀随机选择一个可能的 (center_fraction, acceleration)。
示例
如果 accelerations = [4, 8] 并且 center_fractions = [0.08, 0.04],则有 50% 的概率选择带有 8% 中心部分的 4 倍加速,以及 50% 的概率选择带有 4% 中心部分的 8 倍加速。
- 修改和采用自
- __call__(kspace)[source]#
- 参数:
kspace (
Union[ndarray,Tensor]) – 输入的 k-space 数据。对于复数 2D 输入,形状为 (…,num_coils,H,W,2);对于实数 3D 数据,形状为 (…,num_coils,H,W,D)。采样沿最后一个空间维度进行。对于 fastMRI 数据集,k-space 的形式为 (…,num_slices,num_coils,H,W),采样沿 W 进行。对于形状为 (…,num_coils,H,W,D) 的通用 3D 数据,采样沿 D 进行。- 返回类型:
Sequence[Tensor]- 返回值:
- 包含以下内容的元组
欠采样的 kspace
欠采样的 kspace 的逆傅里叶变换的绝对值
- class monai.apps.reconstruction.transforms.array.EquispacedKspaceMask(center_fractions, accelerations, spatial_dims=2, is_complex=True)[source]#
此 k-space 掩膜变换根据等距采样模式对 k-space 进行欠采样。具体而言,它从输入 k-space 数据中选择等距的列子集。如果 k-space 数据有 N 列,掩膜会选取
1. N_low_freqs = (N * center_fraction) 位于中心处对应于低频的列
2. 其余列以等距方式选择,其比例达到期望的加速率,同时考虑到低频的数量。这确保了所选列的期望数量等于 (N / acceleration)
可以使用多个 center_fractions 和 accelerations,在这种情况下,每次调用 EquispacedMaskFunc 对象时会均匀随机选择一个可能的 (center_fraction, acceleration)。
示例
如果 accelerations = [4, 8] 并且 center_fractions = [0.08, 0.04],则有 50% 的概率选择带有 8% 中心部分的 4 倍加速,以及 50% 的概率选择带有 4% 中心部分的 8 倍加速。
- 修改和采用自
- __call__(kspace)[source]#
- 参数:
kspace (
Union[ndarray,Tensor]) – 输入的 k-space 数据。对于复数 2D 输入,形状为 (…,num_coils,H,W,2);对于实数 3D 数据,形状为 (…,num_coils,H,W,D)。采样沿最后一个空间维度进行。对于 fastMRI 多线圈数据集,k-space 的形式为 (…,num_slices,num_coils,H,W),采样沿 W 进行。对于形状为 (…,num_coils,H,W,D) 的通用 3D 数据,采样沿 D 进行。- 返回类型:
Sequence[Tensor]- 返回值:
- 包含以下内容的元组
欠采样的 kspace
欠采样的 kspace 的逆傅里叶变换的绝对值
Lazy#
ApplyPending#
实用工具#
Identity#
AsChannelLast#
- class monai.transforms.AsChannelLast(channel_dim=0)[source]#
将图像的通道维度更改为最后一个维度。
一些第三方变换假定输入图像是通道在后的格式,形状为 (spatial_dim_1[, spatial_dim_2, …], num_channels)。
此变换可用于将例如形状为 (num_channels, spatial_dim_1[, spatial_dim_2, …]) 的通道在前图像数组转换为通道在后的格式,以便 MONAI 变换可以与其他第三方变换一起构建链。
- 参数:
channel_dim (
int) – 输入图像的哪个维度是通道,默认为第一个维度。
EnsureChannelFirst#
- class monai.transforms.EnsureChannelFirst(strict_check=True, channel_dim=None)[source]#
调整或添加输入数据的通道维度,以确保 channel_first 形状。
这会从提供的 meta_data 字典或 MetaTensor 输入中提取 original_channel_dim 信息。此值应说明哪个维度是通道维度,以便可以将其移到前面,或者包含“no_channel”以说明没有维度是通道维度,因此应添加一个大小为 1 的第一个维度。
- 参数:
strict_check – 当元信息不足时是否引发错误。
channel_dim – 此参数可用于指定输入数组的原始通道维度(整数)。它会覆盖提供的 MetaTensor 输入中的 original_channel_dim。如果输入数组没有通道维度,此值应为
'no_channel'。如果将其设置为 None,此类将依赖 img 或 meta_dict 提供通道维度。
RepeatChannel#
SplitDim#
- class monai.transforms.SplitDim(dim=-1, keepdim=True, update_meta=True)[source]#
给定沿某个维度大小为 X 的图像,返回一个长度为 X 的包含图像的列表。例如,对于将 3D 图像转换为 2D 图像堆栈、将多通道输入分割为单通道非常有用。
注意:使用了 torch.split/np.split,因此输出是输入的视图(浅拷贝)。
- 参数:
dim (
int) – 要分割的维度keepdim (
bool) – 如果 True,输出在分割维度上将具有单一维度。如果 False,此维度将被挤压。update_meta – 是否更新每个分割结果中的 MetaObj。
CastToType#
- class monai.transforms.CastToType(dtype=<class 'numpy.float32'>)[source]#
将 Numpy 数据转换为指定的 numpy 数据类型,或将 PyTorch Tensor 转换为指定的 PyTorch 数据类型。
示例
>>> import numpy as np >>> import torch >>> transform = CastToType(dtype=np.float32)
>>> # Example with a numpy array >>> img_np = np.array([0, 127, 255], dtype=np.uint8) >>> img_np_casted = transform(img_np) >>> img_np_casted array([ 0. , 127. , 255. ], dtype=float32)
>>> # Example with a PyTorch tensor >>> img_tensor = torch.tensor([0, 127, 255], dtype=torch.uint8) >>> img_tensor_casted = transform(img_tensor) >>> img_tensor_casted tensor([ 0., 127., 255.]) # dtype is float32
ToTensor#
- class monai.transforms.ToTensor(dtype=None, device=None, wrap_sequence=True, track_meta=None)[source]#
将输入图像转换为 tensor,不应用任何其他变换。输入数据可以是 PyTorch Tensor、numpy 数组、列表、字典、int、float、bool、str 等。Tensor、Numpy 数组、float、int、bool 将被转换为 Tensor,字符串和对象保持原样。对于字典、列表或元组,如果适用且 wrap_sequence=False,将每个项转换为 Tensor。
- 参数:
dtype – 转换为 Tensor 时目标数据类型。
device – 存放转换后的 Tensor 数据的目标设备。
wrap_sequence – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [tensor(1), tensor(2)];如果 True,则 [1, 2] -> tensor([1, 2])。
track_meta – 是否转换为 MetaTensor 或普通 tensor,默认为 None,使用
get_track_meta的返回值。
ToNumpy#
- class monai.transforms.ToNumpy(dtype=None, wrap_sequence=True)[source]#
将输入数据转换为 numpy 数组,支持数字列表或元组以及 PyTorch Tensor。
- 参数:
dtype (
Union[dtype,type,str,None]) – 转换为 numpy 数组时的目标数据类型。wrap_sequence (
bool) – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [array(1), array(2)];如果 True,则 [1, 2] -> array([1, 2])。
ToCupy#
- class monai.transforms.ToCupy(dtype=None, wrap_sequence=True)[source]#
将输入数据转换为 CuPy 数组,支持数字列表或元组、NumPy 和 PyTorch Tensor。
- 参数:
dtype – 数据类型指定符。默认从输入推断。如果不是 None,则必须是 numpy.dtype 的参数,更多详情请参见:https://docs.cupy.com.cn/en/stable/reference/generated/cupy.array.html。
wrap_sequence – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [array(1), array(2)];如果 True,则 [1, 2] -> array([1, 2])。
Transpose#
SqueezeDim#
DataStats#
- class monai.transforms.DataStats(prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, meta_info=False, additional_info=None, name='DataStats')[source]#
用于显示数据统计信息以便调试或分析的实用工具变换。它可以插入到变换链的任何位置,并检查之前变换的结果。它支持将 numpy.ndarray 和 torch.tensor 作为输入数据,因此可用于预处理和后处理。
它从 logging.getLogger(name) 获取 logger,我们可以先在外部设置一个同名的 logger。如果 logging.RootLogger 的日志级别高于 INFO,将添加一个单独的 StreamHandler 日志处理器,级别为 INFO,并记录到 stdout。
- __call__(img, prefix=None, data_type=None, data_shape=None, value_range=None, data_value=None, meta_info=None, additional_info=None)[source]#
将变换应用于 img,可选地接受与类构造函数类似的参数。
- __init__(prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, meta_info=False, additional_info=None, name='DataStats')[source]#
- 参数:
prefix – 将以格式:“{prefix} 统计信息”打印。
data_type – 是否显示输入数据的类型。
data_shape – 是否显示输入数据的形状。
value_range – 是否显示输入数据的值范围。
data_value – 是否显示输入数据的原始值。一个典型示例是打印 Nifti 图像的一些属性:affine、pixdim 等。
meta_info – 是否显示 MetaTensor 的数据。
additional_info – 用户可以定义可调用函数以从输入数据中提取额外信息。
name – 要使用的 logging.logger 的标识符,默认为“DataStats”。
- 抛出异常:
TypeError – 当
additional_info不是Optional[Callable]类型时。
SimulateDelay#
- class monai.transforms.SimulateDelay(delay_time=0.0)[source]#
这是一种用于测试目的的直通变换。它允许添加有助于测试目的的虚假行为,以模拟大型数据集的行为,而无需在大型数据集上进行测试。
例如,通过添加显式计时延迟来模拟测试中的慢速 NFS 数据传输或慢速网络传输。对小型测试数据进行测试可能导致对实际问题的理解不完整,并可能导致次优的设计选择。
Lambda#
- class monai.transforms.Lambda(func=None, inv_func=<function no_collation>, track_meta=True)[source]#
应用用户定义的 lambda 作为变换。
例如
image = np.ones((10, 2, 2)) lambd = Lambda(func=lambda x: x[:4, :, :]) print(lambd(image).shape) (4, 2, 2)
- 参数:
func – 要应用的 Lambda/函数。
inv_func – 逆操作的 Lambda/函数,默认为 lambda x: x。
track_meta – 如果 False,则将返回标准数据对象(例如,torch.Tensor` 和 np.ndarray),而不是 MONAI 的增强对象。默认情况下,这是 True。
- 抛出异常:
TypeError – 当
func不是Optional[Callable]类型时。
RandLambda#
- class monai.transforms.RandLambda(func=None, prob=1.0, inv_func=<function no_collation>, track_meta=True)[source]#
monai.transforms.Lambda的可随机版本,输入 func 可能包含随机逻辑,或根据 prob 随机执行函数。- 参数:
func – 要应用的 Lambda/函数。
prob – 执行随机函数的概率,默认为 1.0,即以 100% 的概率执行。
inv_func – 逆操作的 Lambda/函数,默认为 lambda x: x。
track_meta – 如果 False,则将返回标准数据对象(例如,torch.Tensor` 和 np.ndarray),而不是 MONAI 的增强对象。默认情况下,这是 True。
更多详情,请查阅
monai.transforms.Lambda。
RemoveRepeatedChannel#
LabelToMask#
- class monai.transforms.LabelToMask(select_labels, merge_channels=False)[source]#
将标签转换为掩膜用于其他任务。一个典型用法是将分割标签转换为掩膜数据,用于预处理图像,然后将图像输入分类网络。它支持单通道标签或 One-Hot 标签,可通过指定 select_labels 进行选择。例如,用户可以选择 label value = [2, 3] 来构建掩膜数据,或者选择标签的第二和第三个通道来构建掩膜数据。输出的掩膜数据可以是多通道的二值数据,也可以是合并所有通道的单通道二值数据。
- 参数:
select_labels – 用于生成掩膜的标签。对于 1 通道标签,select_labels 是期望的标签值,例如:[1, 2, 3]。对于 One-Hot 格式标签,select_labels 是期望的通道索引。
merge_channels – 是否使用 np.any() 在通道维度上合并结果。如果是,将返回一个带有二值数据的单通道掩膜。
FgBgToIndices#
- class monai.transforms.FgBgToIndices(image_threshold=0.0, output_shape=None)[source]#
计算输入标签数据的前景和背景,返回索引。如果没有指定 output_shape,输出数据将是展平后的 1 维索引。此变换有助于预计算前景和背景区域,以便进行其他变换。一个典型用法是随机选择前景和背景进行裁剪。主要逻辑基于
monai.transforms.utils.map_binary_to_indices。- 参数:
image_threshold – 如果在运行时启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅在此区域中选择背景。output_shape – 输出索引的期望形状。如果不是 None,将索引展开到指定的形状。
ClassesToIndices#
- class monai.transforms.ClassesToIndices(num_classes=None, image_threshold=0.0, output_shape=None, max_samples_per_class=None)[source]#
- __call__(label, image=None, output_shape=None)[source]#
- 参数:
label – 用于计算每个类别的索引的输入数据。
image – 如果 image 不是 None,则使用
image > image_threshold定义有效区域,并仅选择有效区域内的索引。output_shape – 输出索引的期望形状。如果为 None,则改为使用 self.output_shape。
- __init__(num_classes=None, image_threshold=0.0, output_shape=None, max_samples_per_class=None)[source]#
计算输入标签数据的每个类别的索引,返回一个索引列表。如果没有指定 output_shape,输出数据将是展平后的 1 维索引。此变换有助于预计算类别区域的索引,以便进行其他变换。一个典型用法是随机选择类别的索引进行裁剪。主要逻辑基于
monai.transforms.utils.map_classes_to_indices。- 参数:
num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
image_threshold – 如果在运行时启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅选择此区域内的类别索引。output_shape – 输出索引的期望形状。如果不是 None,将索引展开到指定的形状。
max_samples_per_class – 每个类别中要采样的索引的最大长度,以减少内存消耗。默认为 None,不进行子采样。
ConvertToMultiChannelBasedOnBratsClasses#
- class monai.transforms.ConvertToMultiChannelBasedOnBratsClasses[source]#
根据 brats18 类别将标签转换为多通道:标签 1 是坏死和非增强肿瘤核心 标签 2 是瘤周水肿 标签 4 是 GD 增强肿瘤 可能的类别有 TC(肿瘤核心)、WT(完整肿瘤)和 ET(增强肿瘤)。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Union[ndarray,Tensor]
AddExtremePointsChannel#
- class monai.transforms.AddExtremePointsChannel(background=0, pert=0.0)[source]#
将标签的极值点作为新通道添加到图像中。此变换从标签生成极值点并应用高斯滤波器。点图像中的像素值被重新缩放到范围 [rescale_min, rescale_max],并作为新通道添加到输入图像中。该算法在 Roth 等人的论文《走向极端:弱监督医学图像分割》中有所描述:https://arxiv.org/abs/2009.11988。
此变换仅支持单通道标签 (1, spatial_dim1, [spatial_dim2, …])。计算极值点时会忽略背景
index。- 参数:
background (
int) – 背景标签的类别索引,默认为 0。pert (
float) – 添加到点上的随机扰动量,默认为 0.0。
- 抛出异常:
ValueError – 当未提供标签图像时。
ValueError – 当标签图像不是单通道时。
- __call__(img, label=None, sigma=3.0, rescale_min=-1.0, rescale_max=1.0)[source]#
- 参数:
img – 我们想要添加新通道的图像。
label – 用于获取极值点的标签图像。形状必须是 (1, spatial_dim1, [, spatial_dim2, …])。不支持 one-hot 标签。
sigma – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
rescale_min – 输出数据的最小值。
rescale_max – 输出数据的最大值。
TorchVision#
MapLabelValue#
- class monai.transforms.MapLabelValue(orig_labels, target_labels, dtype=<class 'numpy.float32'>)[source]#
一个工具,用于将标签值映射到另一组值。例如,将 [3, 2, 1] 映射到 [0, 1, 2],将 [1, 2, 3] 映射到 [0.5, 1.5, 2.5],将 [“label3”, “label2”, “label1”] 映射到 [0, 1, 2],将 [3.5, 2.5, 1.5] 映射到 [“label0”, “label1”, “label2”] 等。标签数据必须是 numpy 数组或类似数组的数据,输出数据将是 numpy 数组。
EnsureType#
- class monai.transforms.EnsureType(data_type='tensor', dtype=None, device=None, wrap_sequence=True, track_meta=None)[source]#
确保输入数据是 PyTorch Tensor 或 numpy 数组,支持:numpy array、PyTorch Tensor、float、int、bool、string 和 object(保持原始类型)。如果传入字典、列表或元组,并且 wrap_sequence=False,则仍返回字典、列表或元组,并将递归地将每个元素转换为期望的数据类型。
- 参数:
data_type – 目标数据类型,应为 "tensor" 或 "numpy"。
dtype – 目标数据内容类型,例如:np.float32, torch.float 等。
device – 对于 Tensor 数据类型,指定目标设备。
wrap_sequence – 如果为 False,则列表会递归调用此函数,默认为 True。
track_meta – 如果为 True 则转换为
MetaTensor,否则转换为 PyTorchTensor;如果为None,则根据 py:func:monai.data.meta_obj.get_track_meta 的返回值行为。
- wrap_sequence=True 示例
>>> import numpy as np >>> import torch >>> transform = EnsureType(data_type="tensor", wrap_sequence=True) >>> # Converting a list to a tensor >>> data_list = [1, 2., 3] >>> tensor_data = transform(data_list) >>> tensor_data tensor([1., 2., 3.]) # All elements have dtype float32
- wrap_sequence=False 示例
>>> transform = EnsureType(data_type="tensor", wrap_sequence=False) >>> # Converting each element in a list to individual tensors >>> data_list = [1, 2, 3] >>> tensors_list = transform(data_list) >>> tensors_list [tensor(1), tensor(2.), tensor(3)] # Only second element is float32 rest are int64
- __call__(data, dtype=None)[source]#
- 参数:
data – 输入数据可以是 PyTorch Tensor、numpy 数组、list、dictionary、int、float、bool、str 等。会将 Tensor、Numpy 数组、float、int、bool 确保为 Tensors 或 numpy 数组,strings 和 objects 保持原始类型。对于 dictionary、list 或 tuple,如果适用且 wrap_sequence=False,则确保每个元素为期望类型。
dtype – 目标数据内容类型,例如:np.float32, torch.float 等。
IntensityStats#
- class monai.transforms.IntensityStats(ops, key_prefix, channel_wise=False)[source]#
计算输入图像强度值的统计信息,并存储到元数据字典中。例如:如果 ops=[lambda x: np.mean(x), “max”] 且 key_prefix=”orig”,可能会生成如下统计信息:{“orig_custom_0”: 1.5, “orig_max”: 3.0}。
- 参数:
ops – 期望用于计算强度统计的操作。如果是字符串,则映射到预定义的操作,支持:["mean", "median", "max", "min", "std"],分别映射到 np.nanmean、np.nanmedian、np.nanmax、np.nanmin、np.nanstd。如果是可调用的函数,则在输入图像上执行该函数。
key_prefix – 用于与 ops 名称组合生成键,以将结果存储到元数据字典中。如果某些 ops 是可调用函数,则将使用 "{key_prefix}_custom_{index}" 作为键,其中索引从 0 开始计数。
channel_wise – 是否分别计算输入图像每个通道的统计信息。如果为 True,则对每个操作返回一个值列表,默认为 False。
ToDevice#
- class monai.transforms.ToDevice(device, **kwargs)[source]#
将 PyTorch Tensor 移动到指定的设备。这有助于将数据缓存到 GPU 并直接在 GPU 上执行后续逻辑。
注意
如果在 DataLoader 的多进程 worker 中将数据移动到 GPU 设备,可能会出现以下 CUDA 错误:"RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the ‘spawn’ start method." 因此通常建议在 DataLoader 或 ThreadDataLoader 中设置 num_workers=0。
- __call__(img)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- __init__(device, **kwargs)[source]#
- 参数:
device – 目标设备,用于移动 Tensor,例如:"cuda:1"。
kwargs – PyTorch Tensor.to() API 的其他参数,更多详情请参见:https://pytorch.ac.cn/docs/stable/generated/torch.Tensor.to.html。
CuCIM#
- class monai.transforms.CuCIM(name, *args, **kwargs)[source]#
封装一个非随机的 cuCIM 变换,根据变换名称和参数定义。对于随机变换,请使用
monai.transforms.RandCuCIM。- 参数:
name (
str) – CuCIM 包中的变换名称。args – CuCIM 变换的参数。
kwargs – CuCIM 变换的参数。
注意
CuCIM 变换仅适用于 CuPy 数组,因此此变换期望输入数据为 cupy.ndarray。用户可以调用 ToCuPy 变换将 numpy 数组或 torch tensor 转换为 cupy 数组。
RandCuCIM#
- class monai.transforms.RandCuCIM(name, *args, **kwargs)[source]#
封装一个随机的 cuCIM 变换,根据变换名称和参数定义。对于确定性的非随机变换,请使用
monai.transforms.CuCIM。- 参数:
name (
str) – CuCIM 包中的变换名称。args – CuCIM 变换的参数。
kwargs – CuCIM 变换的参数。
注意
CuCIM 变换仅适用于 CuPy 数组,因此此变换期望输入数据为 cupy.ndarray。用户可以调用 ToCuPy 变换将 numpy 数组或 torch tensor 转换为 cupy 数组。
如果底层 cuCIM 变换的随机因子并非来自 self.R,则结果可能不是确定性的。另请参阅:
monai.transforms.Randomizable。
AddCoordinateChannels#
- class monai.transforms.AddCoordinateChannels(spatial_dims)[source]#
在输入数据中附加编码坐标的额外通道。例如,在使用基于 patch 的采样进行训练时,这很有用,可以将 patch 的位置输入到网络中。
这可以看作是仅输入的 CoordConv 版本。
Liu, R. 等人。卷积神经网络的一个有趣的失败案例及 CoordConv 解决方案,NeurIPS 2018。
- 参数:
spatial_dims (
Sequence[int]) – 需要在通道中编码其坐标并附加到输入图像的空间维度。例如,(0, 1, 2) 表示 H, W, D 维度,并向输入图像附加三个通道,编码输入数据的三个空间维度的坐标。
ImageFilter#
- class monai.transforms.ImageFilter(filter, filter_size=None, **kwargs)[source]#
对输入图像应用卷积滤波器。
- 参数:
filter – 指定滤波器的字符串,作为
torch.Tenor或np.ndarray的自定义滤波器,或者一个nn.Module。字符串可用选项包括:mean、laplace、elliptical、sobel、sharpen、median、gauss。每个滤波器的简要说明见下文。filter_size – 一个整数值,指定二次或三次滤波器的大小。计算复杂度与 2 (2D 滤波器) 或 3 (3D 滤波器) 的幂次方成比例,选择滤波器大小时应考虑这一点。
kwargs – 传递给滤波器函数的额外参数,
sobel和gauss需要这些参数。详情见下文。
- 抛出异常:
ValueError – 当
filter_size不是奇整数时。ValueError – 当
filter是数组且ndim不在 [1,2,3] 中时。ValueError – 当
filter是数组且任一维度形状为偶数时。NotImplementedError – 当
filter是字符串且不在self.supported_filters中时。KeyError – 当必需的
kwargs未传递给需要额外参数的滤波器时。
均值滤波 (Mean Filtering):
filter='mean'均值滤波可以平滑边缘并消除分割图像中的锯齿伪影。另请参阅 py:func:monai.networks.layers.simplelayers.MeanFilter 2D 滤波器示例 (5 x 5)
[[1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 1]]
如果使用此滤波器平滑标签,请确保它们采用 one-hot 格式。
轮廓检测 (Outline Detection):
filter='laplace'用于图像轮廓检测的拉普拉斯滤波。可用于将标签转换为轮廓。另请参阅 py:func:monai.networks.layers.simplelayers.LaplaceFilter
2D 滤波器示例 (5x5)
[[-1., -1., -1., -1., -1.], [-1., -1., -1., -1., -1.], [-1., -1., 24., -1., -1.], [-1., -1., -1., -1., -1.], [-1., -1., -1., -1., -1.]]
膨胀 (Dilation):
filter='elliptical'椭圆滤波器可用于膨胀标签或标签轮廓。2D 滤波器示例 (5x5)
[[0., 0., 1., 0., 0.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [0., 0., 1., 0., 0.]]
边缘检测 (Edge Detection):
filter='sobel'此滤波器允许在初始化期间通过
kwargs传递额外参数。另请参阅 py:func:monai.transforms.post.SobelGradientskwargs
spatial_axes: 定义要计算梯度方向的轴。它沿着提供的每个轴计算梯度。默认情况下,计算所有空间轴的梯度。normalize_kernels: 是否归一化 Sobel 核以提供适当的梯度。默认为 True。normalize_gradients: 是否将输出梯度归一化到 0 和 1 之间。默认为 False。padding_mode: 与 Sobel 核卷积时图像的填充模式。默认为"reflect"。可接受的值包括'zeros','reflect','replicate'或'circular'。更多信息请参见torch.nn.Conv1d()。dtype: 核的数据类型 (torch.dtype)。默认为torch.float32。
锐化 (Sharpening):
filter='sharpen'使用 2D 或 3D 滤波器锐化图像。2D 滤波器示例 (5x5)
[[ 0., 0., -1., 0., 0.], [-1., -1., -1., -1., -1.], [-1., -1., 17., -1., -1.], [-1., -1., -1., -1., -1.], [ 0., 0., -1., 0., 0.]]
高斯平滑 (Gaussian Smooth):
filter='gauss'使用 2D 或 3D 高斯滤波器模糊/平滑图像。此滤波器需要在初始化期间通过
kwargs传递额外参数。另请参阅 py:func:monai.networks.layers.simplelayers.GaussianFilterkwargs
sigma: 标准差。可以是一个单值,也可以是 spatial_dims 个值。truncated: 传播多少个标准差。approx: 离散高斯核类型,可用选项包括 "erf", "sampled", 和 "scalespace"。
中值滤波 (Median Filter):
filter='median'使用 2D 或 3D 中值滤波器模糊图像以去除噪声。在图像预处理中很有用,可以改善后续处理结果。另请参阅 py:func:monai.networks.layers.simplelayers.MedianFilter
Savitzky Golay 滤波:
filter = 'savitzky_golay'沿特定轴使用 Savitzky-Golay 核卷积 Tensor。此滤波器需要在初始化期间通过
kwargs传递额外参数。另请参阅 py:func:monai.networks.layers.simplelayers.SavitzkyGolayFilterkwargs
order: 拟合到每个窗口的多项式阶数,必须小于window_length。axis: (可选): 应用滤波器核的轴。默认 2 (第一个空间维度)。mode: (字符串, 可选): 传递给卷积类的填充模式。'zeros','reflect','replicate'或'circular'。默认:'zeros'。更多信息请参见 torch.nn.Conv1d()。
RandImageFilter#
- class monai.transforms.RandImageFilter(filter, filter_size=None, prob=0.1, **kwargs)[source]#
随机地对输入数据应用卷积滤波器。
- 参数:
filter – 指定滤波器的字符串或作为 torch.Tenor 或 np.ndarray 的自定义滤波器。可用选项包括:mean, laplace, elliptical, gaussian`。每个滤波器的简要说明见下文。
filter_size – 一个整数值,指定二次或三次滤波器的大小。计算复杂度与 2 (2D 滤波器) 或 3 (3D 滤波器) 的幂次方成比例,选择滤波器大小时应考虑这一点。
prob – 变换应用于数据的概率。
ApplyTransformToPoints#
- class monai.transforms.ApplyTransformToPoints(dtype=None, affine=None, invert_affine=True, affine_lps_to_ras=False)[source]#
在图像坐标系和世界坐标系之间变换点。输入坐标假定形状为 (C, N, 2 or 3),其中 C 表示通道数,N 表示点的数量。它将返回一个与输入形状相同的张量。
- 参数:
dtype – 输出所需的 数据类型。
affine – 应用于点的 3x3 或 4x4 仿射变换矩阵。此矩阵通常源自图像。对于 2D 点,可以提供一个 3x3 矩阵,避免添加不必要的 Z 维度。尽管 3D 变换需要 4x4 矩阵,但值得注意的是,当将 4x4 矩阵应用于 2D 点时,会相应处理额外维度。该矩阵总是转换为 float64 进行计算,当应用于大量点时,这可能计算开销较大。如果为 None,将尝试使用输入数据中的仿射矩阵。
invert_affine – 是否反转应用于点的仿射变换矩阵。默认为
True。通常,仿射矩阵源自图像并表示其在世界空间中的位置,而点位于世界坐标系中。值为True表示将这些世界空间坐标变换到图像的坐标空间,False表示此操作的逆变换。affine_lps_to_ras – 默认为
False。如果您的点数据采用 RAS 坐标系或您正在使用带有 affine_lps_to_ras=True 的 ITKReader,则设置为 True。这确保了在 LPS (left-posterior-superior) 和 RAS (right-anterior-superior) 坐标系之间正确应用仿射变换。此参数确保点和仿射矩阵位于同一坐标系中。
- 用例
在世界空间和图像空间之间以及反向转换点。
自动处理图像空间和世界空间之间的逆变换。
如果点已经存在仿射变换,则类会计算并应用所需的增量仿射变换。
字典变换#
裁剪和填充 (Dict)#
Padd#
- class monai.transforms.Padd(keys, padder, mode=constant, allow_missing_keys=False, lazy=False)[source]#
monai.transforms.Pad的基于字典的包装。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, padder, mode=constant, allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformpadder (
Pad) – 用于输入图像的填充变换。mode (
Union[Sequence[str],str]) – numpy 数组的可用模式:{"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 指示此变换是否应延迟执行的标志。默认为 False。
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,MetaTensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
SpatialPadd#
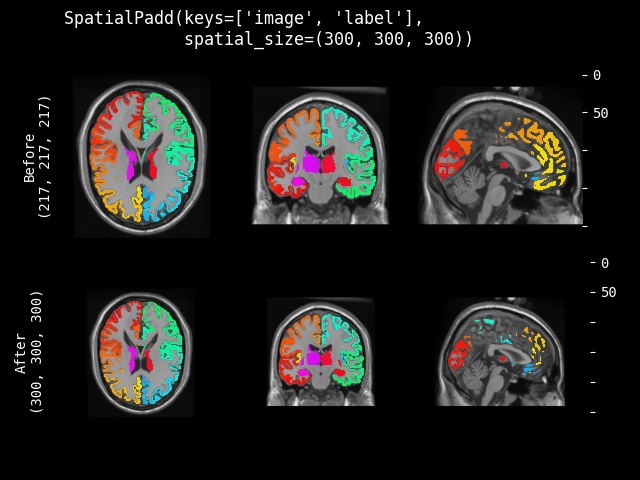
- class monai.transforms.SpatialPadd(*args, **kwargs)[source]#
monai.transforms.SpatialPad的基于字典的包装。对数据进行填充,可以是所有边的对称填充,或者每个维度都只在一侧进行填充。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(keys, spatial_size, method=symmetric, mode=constant, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformspatial_size – 填充后输出数据的空间大小,如果输入数据某个维度的大小大于填充大小,则不会对该维度进行填充。如果其分量为非正值,则使用输入图像的相应大小。例如:如果输入数据的空间大小为 [30, 30, 30],且 spatial_size=[32, 25, -1],则输出数据的空间大小将为 [32, 30, 30]。
method – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
BorderPadd#
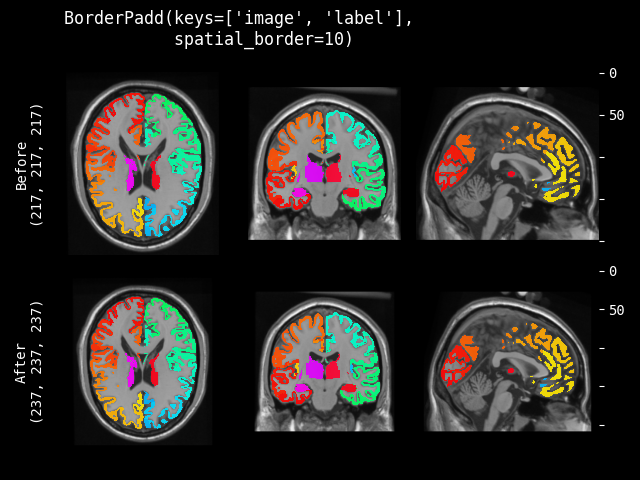
- class monai.transforms.BorderPadd(*args, **kwargs)[source]#
通过在每个维度上添加指定的边界来填充输入数据。
monai.transforms.BorderPad的基于字典的包装。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(keys, spatial_border, mode=constant, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformspatial_border –
为每个空间边界指定的大小。可以是 3 种形状。
单个整数,所有边界都填充相同的尺寸。
长度等于图像形状的长度,每个空间维度单独填充。例如,图像形状(CHW)是 [1, 4, 4],spatial_border 是 [2, 1],H 维度的每个边界填充 2,W 维度的每个边界填充 1,结果形状是 [1, 8, 6]。
长度等于图像形状长度的 2 倍,每个维度的每个边界单独填充。例如,图像形状(CHW)是 [1, 4, 4],spatial_border 是 [1, 2, 3, 4],H 维度的顶部填充 1,H 维度的底部填充 2,W 维度的左侧填充 3,W 维度的右侧填充 4。结果形状是 [1, 7, 11]。
mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
DivisiblePadd#
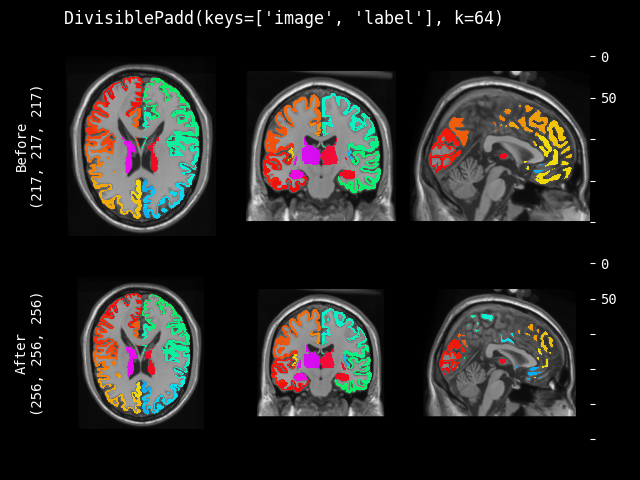
- class monai.transforms.DivisiblePadd(*args, **kwargs)[source]#
填充输入数据,使空间大小可被 k 整除。
monai.transforms.DivisiblePad的基于字典的包装。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(keys, k, mode=constant, method=symmetric, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformk – 每个空间维度的目标 k。如果 k 为负或 0,则保留原始大小。如果 k 是整数,则相同的 k 将应用于所有输入空间维度。
mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。method – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
Cropd#
- class monai.transforms.Cropd(keys, cropper, allow_missing_keys=False, lazy=False)[source]#
抽象类
monai.transforms.Crop的基于字典的包装。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformcropper (
Crop) – 用于输入图像的裁剪变换。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 指示此变换是否应延迟执行的标志。默认为 False。
- __call__(data, lazy=None)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,MetaTensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandCropd#
- class monai.transforms.RandCropd(keys, cropper, allow_missing_keys=False, lazy=False)[source]#
随机裁剪变换的基类。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformcropper (
Crop) – 用于输入图像的随机裁剪变换。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 指示此变换是否应延迟执行的标志。默认为 False。
- __call__(data, lazy=None)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
SpatialCropd#
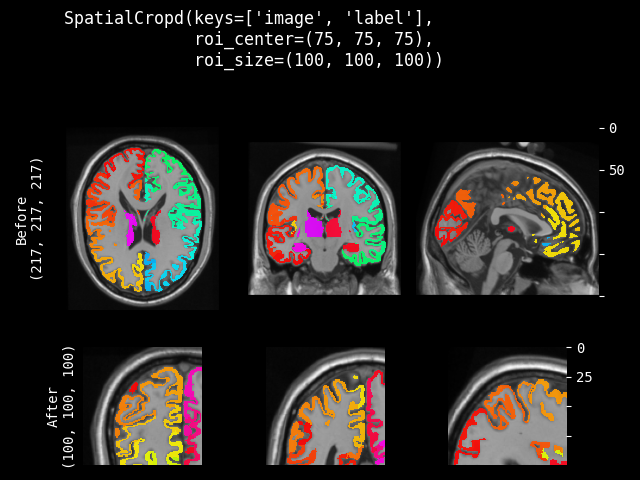
- class monai.transforms.SpatialCropd(*args, **kwargs)[source]#
monai.transforms.SpatialCrop的基于字典的包装。通用的裁剪器,用于生成感兴趣区域 (ROI) 的子卷。如果期望的 ROI 大小的某个维度大于输入图像大小,则不会对该维度进行裁剪。因此,裁剪结果可能小于期望的 ROI,并且多张图像的裁剪结果形状可能不完全相同。它支持裁剪 ND 空间数据 (通道优先)。- 裁剪区域可以通过多种方式进行参数化
每个空间维度的切片列表(允许使用负索引和 None)
空间中心和大小
ROI 的起始和结束坐标
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __init__(keys, roi_center=None, roi_size=None, roi_start=None, roi_end=None, roi_slices=None, allow_missing_keys=False, lazy=False, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformroi_center – 裁剪 ROI 中心的体素坐标。
roi_size – 裁剪 ROI 的大小,如果 ROI 大小的某个维度大于图像大小,则该维度不进行裁剪。
roi_start – 裁剪 ROI 起始的体素坐标。
roi_end – 裁剪 ROI 结束的体素坐标,如果某个坐标超出图像范围,则使用图像的结束坐标。
roi_slices – 每个空间维度的切片列表。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
CenterSpatialCropd#
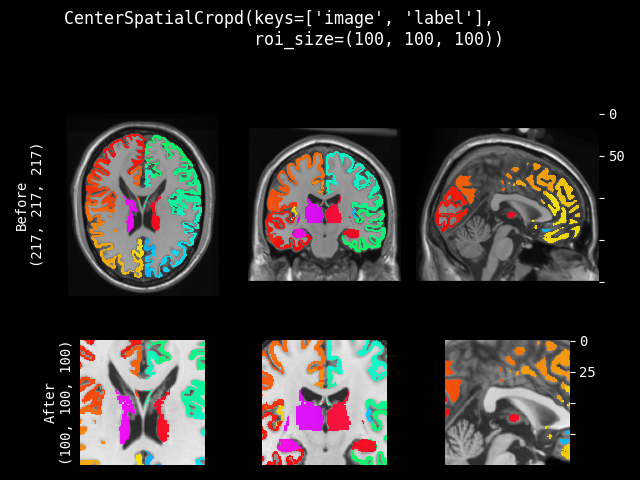
- class monai.transforms.CenterSpatialCropd(*args, **kwargs)[source]#
基于字典的
monai.transforms.CenterSpatialCrop包装器。如果预期的 ROI 大小维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不会具有完全相同的形状。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
roi_size – 裁剪区域的大小,例如 [224,224,128]。如果 ROI 大小的维度大于图像大小,则不会裁剪图像的该维度。如果其分量具有非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
RandSpatialCropd#
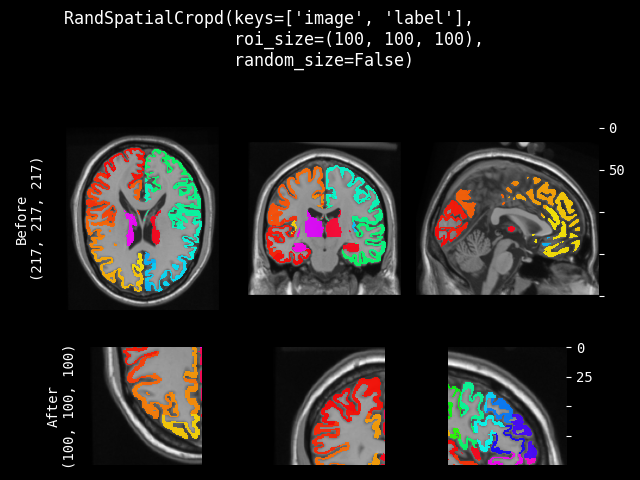
- class monai.transforms.RandSpatialCropd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandSpatialCrop版本。使用随机大小或特定大小的 ROI 裁剪图像。它可以以随机位置或图像中心作为裁剪中心。并且允许设置最小和最大大小以限制随机生成的 ROI。假设 keys 指定的所有预期字段具有相同的形状。注意:即使 random_size=False,如果预期的 ROI 大小的某个维度大于输入图像大小,也不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
roi_size – 如果 random_size 为 True,则指定最小裁剪区域。如果 random_size 为 False,则指定要裁剪的预期 ROI 大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
max_roi_size – 如果 random_size 为 True 且 roi_size 指定了最小裁剪区域大小,则 max_roi_size 可以指定最大裁剪区域大小。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用输入图像的相应大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 使用随机大小或 roi_scale * image spatial size 的特定大小的 ROI 裁剪。如果为 True,则实际大小从 randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1) 中采样。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
RandSpatialCropSamplesd#
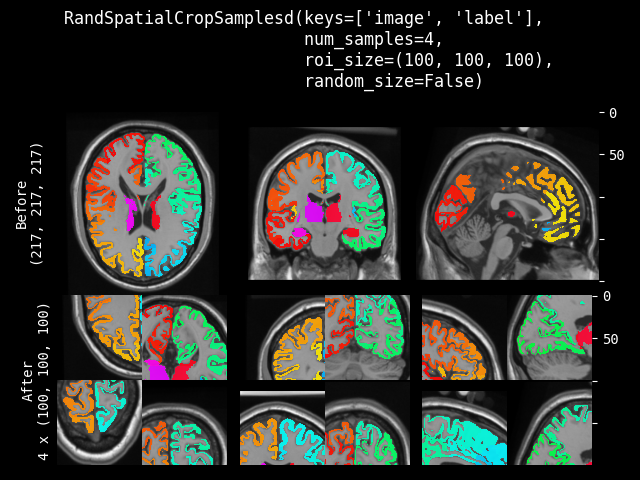
- class monai.transforms.RandSpatialCropSamplesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandSpatialCropSamples版本。使用随机大小或特定大小的 ROI 裁剪图像以生成 N 个样本的列表。它可以以随机位置或图像中心作为裁剪中心。并且允许设置最小大小以限制随机生成的 ROI。假设 keys 指定的所有预期字段具有相同的形状,并将 patch_index 添加到相应的元数据中。它将返回所有裁剪图像的字典列表。注意:即使 random_size=False,如果预期的 ROI 大小的某个维度大于输入图像大小,也不会裁剪该维度。因此,裁剪结果可能小于预期的 ROI,并且多个图像的裁剪结果可能不具有完全相同的形状。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
roi_size – 如果 random_size 为 True,则指定最小裁剪区域。如果 random_size 为 False,则指定要裁剪的预期 ROI 大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用输入图像的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 roi_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
num_samples – 在返回列表中获取的样本(裁剪区域)数量。
max_roi_size – 如果 random_size 为 True 且 roi_size 指定了最小裁剪区域大小,则 max_roi_size 可以指定最大裁剪区域大小。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用输入图像的相应大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 以随机大小或特定大小的 ROI 进行裁剪。实际大小将从 randint(roi_size, img_size) 中采样。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- 抛出异常:
ValueError – 当
num_samples为非正数时。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
CropForegroundd#
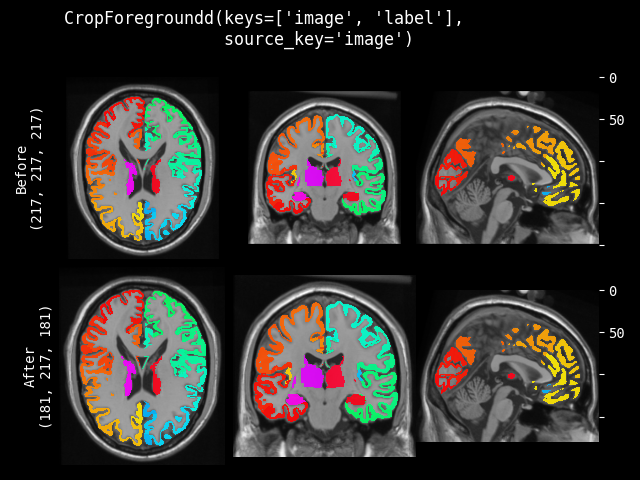
- class monai.transforms.CropForegroundd(keys, source_key, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, k_divisible=1, mode=constant, start_coord_key='foreground_start_coord', end_coord_key='foreground_end_coord', allow_missing_keys=False, lazy=False, **pad_kwargs)[source]#
基于字典的
monai.transforms.CropForeground版本。仅裁剪预期图像的前景对象。如果有效部分在整个医学图像中较小,则典型用法是帮助训练和评估。有效部分可以通过数据中使用 source_key 的任何字段确定,例如:- 选择图像字段中 > 0 的值作为前景,并裁剪 keys 指定的所有字段。- 选择标签字段中 label = 3 的值作为前景,以裁剪 keys 指定的所有字段。- 选择 One-Hot 标签字段第三通道中 label > 0 的值作为前景,以裁剪 keys 指定的所有字段。用户可以定义任意函数来从整个源图像或指定通道中选择预期的前景。并且它还可以为前景对象的边界框的每个维度添加边距。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, source_key, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True, k_divisible=1, mode=constant, start_coord_key='foreground_start_coord', end_coord_key='foreground_end_coord', allow_missing_keys=False, lazy=False, **pad_kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformsource_key – 用于生成前景边界框的数据源,可以是图像或标签等。
select_fn – 用于选择预期前景的函数,默认选择大于 0 的值。
channel_indices – 如果已定义,则仅在图像的指定通道上选择前景。如果为 None,则在整个图像上选择前景。
margin – 向边界框的空间维度添加 margin 值,如果只提供一个值,则将其用于所有维度。
allow_smaller – 计算带 margin 的框大小时,是否允许图像边缘小于最终框边缘。如果为 False,则填充输出框的一部分可能超出原始图像;如果为 True,则将使用图像边缘作为框边缘。默认为 True。
k_divisible – 使每个空间维度可被 k 整除,默认值为 1。如果 k_divisible 是一个整数,则相同的 k 将应用于所有输入空间维度。
mode – 可用于 numpy array 的模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} 可用于 PyTorch Tensor 的模式:{"constant","reflect","replicate","circular"}。可以是列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。start_coord_key – 用于记录前景空间边界框起始坐标的键。
end_coord_key – 用于记录前景空间边界框结束坐标的键。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
RandWeightedCropd#
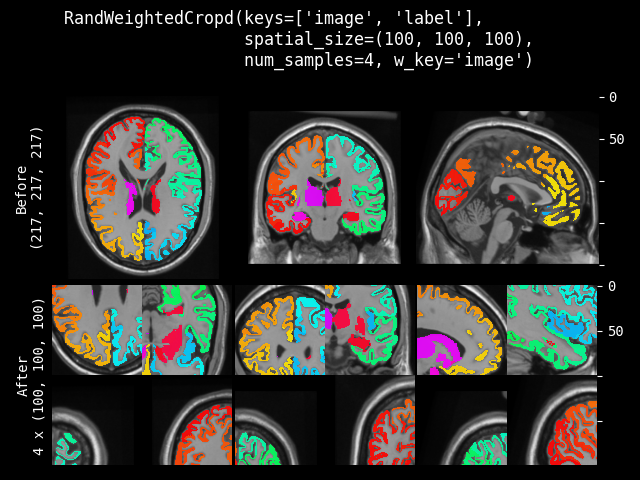
- class monai.transforms.RandWeightedCropd(*args, **kwargs)[source]#
根据提供的 weight_map 采样 num_samples 个图像块。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformw_key – 权重图的键。相应的值将用作采样权重,它应该是一个单通道数组,例如 (1, spatial_dim_0, spatial_dim_1, …)
spatial_size – 图像块的空间大小,例如 [224, 224, 128]。如果其分量包含非正值,则将使用 img 的相应大小。
num_samples – 在返回列表中获取的样本(图像块)数量。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandCropByPosNegLabeld#
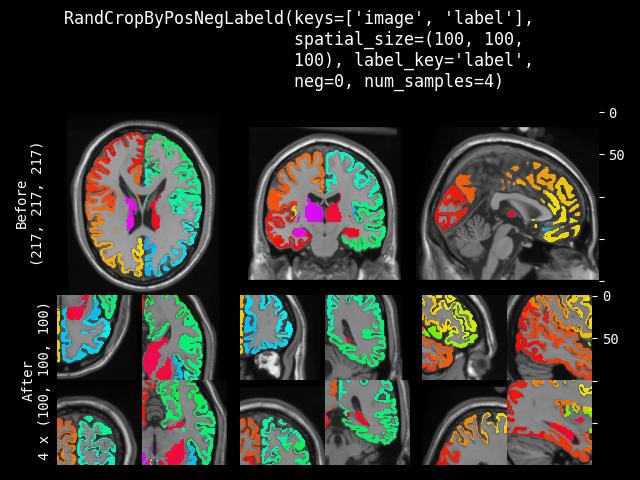
- class monai.transforms.RandCropByPosNegLabeld(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandCropByPosNegLabel版本。根据正负标签比例,以前景或背景体素为中心裁剪随机固定大小的区域。假设 keys 指定的所有预期字段具有相同的形状,并将 patch_index 添加到相应的元数据中。并将返回所有裁剪图像的字典列表。如果预期的空间大小维度大于输入图像大小,则不会裁剪该维度。因此裁剪结果可能小于预期大小,并且多个图像的裁剪结果可能不具有完全相同的形状。并且如果裁剪 ROI 部分超出图像范围,将自动调整裁剪中心以确保有效的裁剪 ROI。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformlabel_key – 标签图像的键名称,用于查找前景/背景。
spatial_size – 裁剪区域的空间大小,例如 [224, 224, 128]。如果 ROI 大小的一个维度大于图像大小,则不会裁剪图像的该维度。如果其分量具有非正值,则使用 data[label_key] 的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],spatial_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
pos – 与 neg 一起用于计算比率
pos / (pos + neg),该比率表示将前景体素选为中心的概率,而不是背景体素。neg – 与 pos 一起用于计算比率
pos / (pos + neg),该比率表示将前景体素选为中心的概率,而不是背景体素。num_samples – 在每个列表中获取的样本(裁剪区域)数量。
image_key – 如果 image_key 不为 None,则使用
label == 0 & image > image_threshold选择负样本(背景)中心。因此裁剪中心仅存在于有效的图像区域。image_threshold – 如果启用 image_key,则使用
image > image_threshold来确定有效图像内容区域。fg_indices_key – 如果提供了 label 的预计算前景索引,将忽略上述 image_key 和 image_threshold,并根据这些索引随机选择裁剪中心,需要同时提供 fg_indices_key 和 bg_indices_key,期望是展平后的空间索引一维数组。典型用法是先调用 FgBgToIndicesd 转换并缓存结果。
bg_indices_key – 如果提供了 label 的预计算背景索引,将忽略上述 image_key 和 image_threshold,并根据这些索引随机选择裁剪中心,需要同时提供 fg_indices_key 和 bg_indices_key,期望是展平后的空间索引一维数组。典型用法是先调用 FgBgToIndicesd 转换并缓存结果。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- 抛出异常:
ValueError – 当
pos或neg为负数时。ValueError – 当
pos=0且neg=0时。值不兼容。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- randomize(label=None, fg_indices=None, bg_indices=None, image=None)[source]#
在此方法中,应使用
self.R而非 np.random 来引入随机因素。所有
self.R调用都发生在此处,以便我们能更好地识别同步随机状态的错误。此方法可以根据输入数据的属性生成随机因素。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
RandCropByLabelClassesd#
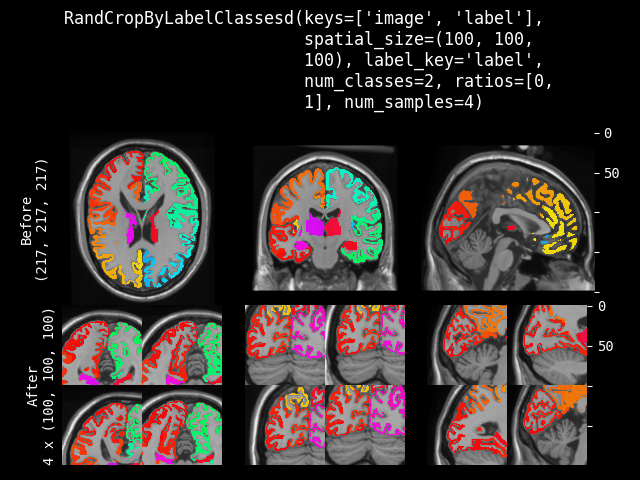
- class monai.transforms.RandCropByLabelClassesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandCropByLabelClasses版本。根据每个类别的指定比例,以某个类别为中心裁剪随机固定大小的区域。标签数据可以是 One-Hot 格式数组或 Argmax 数据。并将返回所有裁剪图像的数组列表。例如,从 (5 x 5) 数组中裁剪两个 (3 x 3) 数组,ratios=[1, 2, 3, 1]cropper = RandCropByLabelClassesd( keys=["image", "label"], label_key="label", spatial_size=[3, 3], ratios=[1, 2, 3, 1], num_classes=4, num_samples=2, ) data = { "image": np.array([ [[0.0, 0.3, 0.4, 0.2, 0.0], [0.0, 0.1, 0.2, 0.1, 0.4], [0.0, 0.3, 0.5, 0.2, 0.0], [0.1, 0.2, 0.1, 0.1, 0.0], [0.0, 0.1, 0.2, 0.1, 0.0]] ]), "label": np.array([ [[0, 0, 0, 0, 0], [0, 1, 2, 1, 0], [0, 1, 3, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]] ]), } result = cropper(data) The 2 randomly cropped samples of `label` can be: [[0, 1, 2], [[0, 0, 0], [0, 1, 3], [1, 2, 1], [0, 0, 0]] [1, 3, 0]]如果预期的空间大小的某个维度大于输入图像大小,则不会裁剪该维度。因此,裁剪结果可能小于预期大小,并且多个图像的裁剪结果可能不具有完全相同的形状。如果裁剪 ROI 部分超出图像范围,将自动调整裁剪中心以确保有效的裁剪 ROI。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformlabel_key – 标签图像的键名称,用于查找每个类别的索引。
spatial_size – 裁剪区域的空间大小,例如 [224, 224, 128]。如果 ROI 大小的某个维度大于图像大小,则不会裁剪图像的该维度。如果其分量包含非正值,则将使用 label 的相应大小。例如:如果输入数据的空间大小为 [40, 40, 40],且 spatial_size=[32, 64, -1],则输出数据的空间大小将为 [32, 40, 40]。
ratios – 指定标签中每个类别用于生成裁剪中心的比率,包括背景类别。如果为 None,则每个类别将具有相同的比率来生成裁剪中心。
num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
num_samples – 在每个列表中获取的样本(裁剪区域)数量。
image_key – 如果 image_key 不为 None,则仅返回位于图像有效区域(
image > image_threshold)内的每个类别的索引。image_threshold – 如果启用 image_key,则使用
image > image_threshold来确定有效图像内容区域,并仅在该区域选择类别索引。indices_key – 如果提供了每个类别的预计算索引,将忽略上述 image 和 image_threshold,并根据这些索引随机选择裁剪中心,期望是展平后的空间索引一维数组。典型用法是先调用 ClassesToIndices 转换并缓存结果,以获得更好的性能。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
allow_missing_keys – 如果键丢失,则不引发异常。
warn – 如果为 True,则如果标签中不存在某个类别,则打印警告。
max_samples_per_class – 每个类别中索引的最大长度,以减少内存消耗。默认为 None,不进行二次采样。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
- randomize(label, indices=None, image=None)[source]#
在此方法中,应使用
self.R而非 np.random 来引入随机因素。所有
self.R调用都发生在此处,以便我们能更好地识别同步随机状态的错误。此方法可以根据输入数据的属性生成随机因素。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- property requires_current_data#
获取转换是否需要在执行前输入数据是最新的。此类转换仍可通过向输出张量添加待定操作来延迟执行。:returns: 如果转换需要其输入是最新的,则为 True,否则为 False
ResizeWithPadOrCropd#
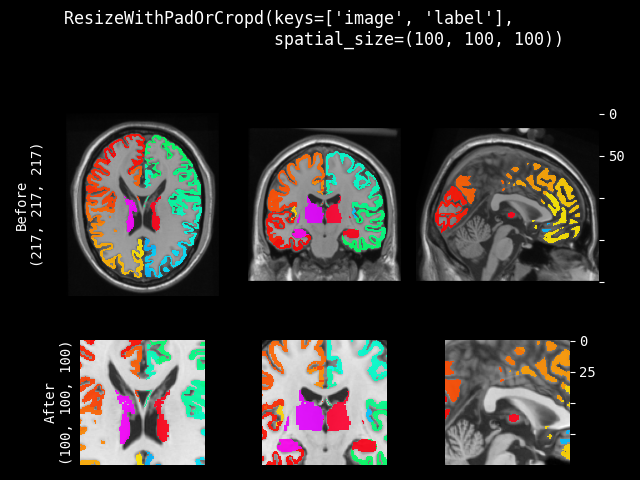
- class monai.transforms.ResizeWithPadOrCropd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ResizeWithPadOrCrop包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
spatial_size – 填充或裁剪后输出数据的空间大小。如果包含非正值,则将使用输入图像的相应大小(不进行填充)。
mode – numpy 数组的可用模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} PyTorch Tensor 的可用模式:{"constant","reflect","replicate","circular"}。列出的字符串值之一或用户提供的函数。默认为"constant"。另请参见:https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
method – {
"symmetric","end"} 在每侧对称填充图像,或仅在末端进行填充。默认为"symmetric"。lazy – 指示此变换是否应延迟执行的标志。默认为 False。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
BoundingRectd#
- class monai.transforms.BoundingRectd(keys, bbox_key_postfix='bbox', select_fn=<function is_positive>, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.BoundingRect包装器。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要转换的相应项的键。另请参见: monai.transforms.MapTransformbbox_key_postfix (
str) – 输出的边界框坐标将写入 {key}_{bbox_key_postfix} 的值中。select_fn (
Callable) – 用于选择预期前景的函数,默认选择大于 0 的值。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
另请参阅:
monai.transforms.utils.generate_spatial_bounding_box.- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
RandScaleCropd#
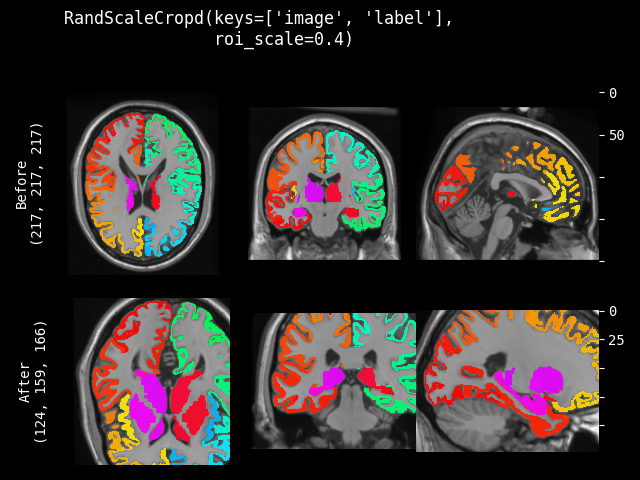
- class monai.transforms.RandScaleCropd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandScaleCrop版本。使用随机大小或 roi_scale * image spatial size 的特定大小的 ROI 裁剪图像。它可以以随机位置或图像中心作为裁剪中心。并且允许设置图像大小的最小和最大比例以限制随机生成的 ROI。假设 keys 指定的所有预期字段具有相同的形状。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
roi_scale – 如果 random_size 为 True,则指定最小裁剪大小:roi_scale * image spatial size。如果 random_size 为 False,则指定预期的图像大小缩放比例进行裁剪,例如 [0.3, 0.4, 0.5]。如果其分量包含非正值,则将使用 1.0 代替,表示输入图像大小。
max_roi_scale – 如果 random_size 为 True 且 roi_scale 指定了最小裁剪区域大小,则 max_roi_scale 可以指定最大裁剪区域大小:max_roi_scale * image spatial size。如果为 None,则默认为输入图像大小。如果其分量包含非正值,则将使用 1.0 代替,表示输入图像大小。
random_center – 在随机位置作为中心进行裁剪,或在图像中心进行裁剪。
random_size – 使用随机大小或 roi_scale * image spatial size 的特定大小的 ROI 裁剪。如果为 True,则实际大小从 randint(roi_scale * image spatial size, max_roi_scale * image spatial size + 1) 中采样。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
CenterScaleCropd#
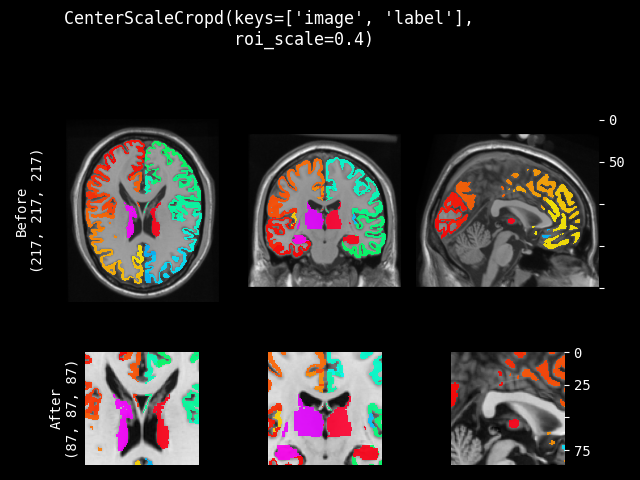
- class monai.transforms.CenterScaleCropd(*args, **kwargs)[source]#
基于字典的
monai.transforms.CenterScaleCrop包装器。注意:由于使用相同的缩放 ROI 进行裁剪,keys 指定的所有输入数据应具有相同的空间形状。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
roi_scale – 指定要裁剪的图像大小的预期缩放比例,例如 [0.3, 0.4, 0.5] 或一个应用于所有维度的数字。如果其分量包含非正值,则将使用 1.0 代替,表示输入图像大小。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
Intensity (Dict)#
RandGaussianNoised#
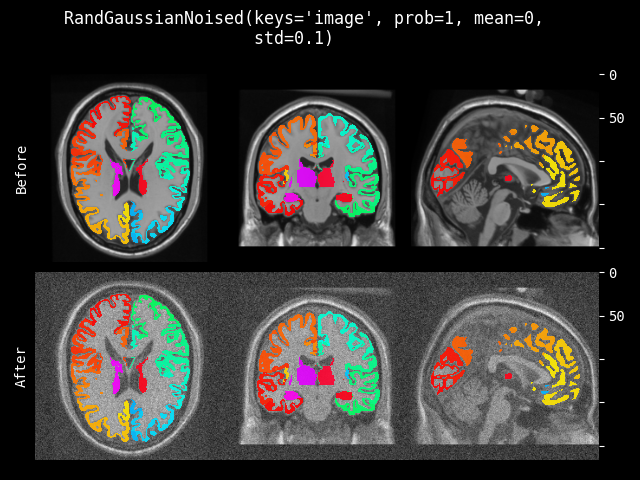
- class monai.transforms.RandGaussianNoised(keys, prob=0.1, mean=0.0, std=0.1, dtype=<class 'numpy.float32'>, allow_missing_keys=False, sample_std=True)[source]#
基于字典的
monai.transforms.RandGaussianNoise版本。给图像添加高斯噪声。此转换假设所有预期字段具有相同的形状,如果您想为每个字段添加不同的噪声,请单独使用此转换。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformprob (
float) – 添加高斯噪声的概率。mean (
float) – 分布的均值或“中心”。std (
float) – 分布的标准差(离散度)。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。allow_missing_keys (
bool) – 如果键缺失,不引发异常。sample_std (
bool) – 如果为 True,则从 0 到 std 均匀采样高斯分布的离散度。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
ShiftIntensityd#
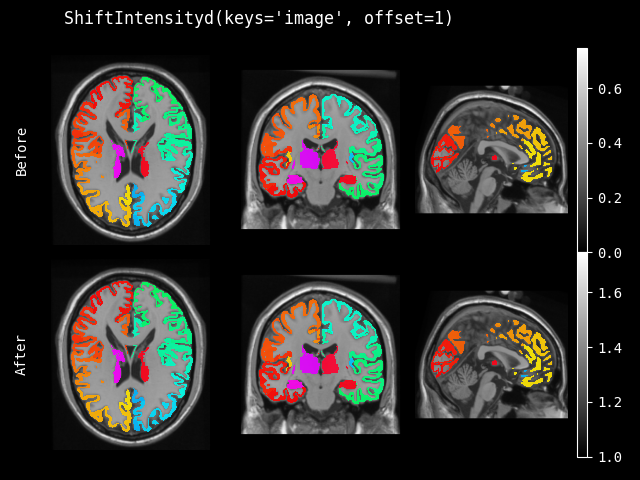
- class monai.transforms.ShiftIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ShiftIntensity包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, offset, safe=False, factor_key=None, meta_keys=None, meta_key_postfix='meta_dict', allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformoffset – 偏移值,用于移动图像强度。
safe – 如果为 True,则在强度溢出时进行安全的数据类型转换。默认为 False。例如,[256, -12] -> [array(0), array(244)]。如果为 True,则 [256, -12] -> [array(255), array(0)]。
factor_key – 如果不为 None,则将其用作从 key 相应元数据字典中提取运行时值并乘以 offset 来移动强度。通常,IntensityStatsd 转换可以预先计算强度值的统计信息并存储在元数据中。它也可以是字符串序列,映射到 keys。
meta_keys – 显式指定相应元数据字典的键。当 factor_key 不为 None 时用于提取因子值。例如,对于键为 image 的数据,元数据默认存储在 image_meta_dict 中。元数据是一个字典对象,包含:filename、original_shape 等。它可以是一个字符串序列,映射到 keys。如果为 None,则尝试通过 key_{meta_key_postfix} 构建 meta_keys。
meta_key_postfix – 如果 meta_keys 为 None,则根据键数据使用 key_{postfix} 获取元数据,默认为 meta_dict,元数据是一个字典对象。当 factor_key 不为 None 时用于提取因子值。
allow_missing_keys – 如果键丢失,则不引发异常。
RandShiftIntensityd#
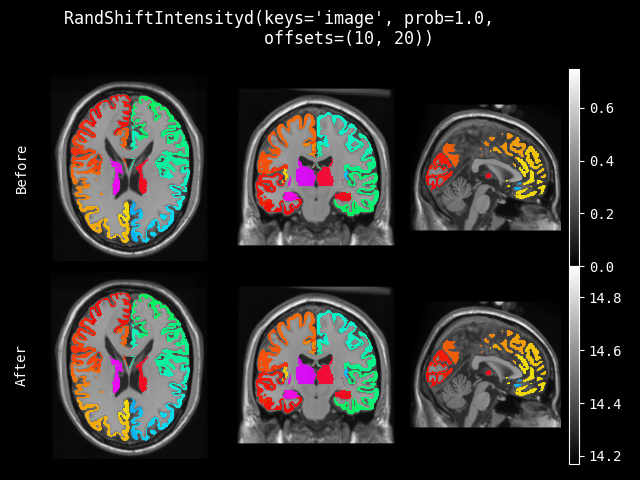
- class monai.transforms.RandShiftIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandShiftIntensity版本。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, offsets, safe=False, factor_key=None, meta_keys=None, meta_key_postfix='meta_dict', prob=0.1, channel_wise=False, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformoffsets – 用于随机调整的偏移量范围。如果是一个数字,则偏移量值从 (-offsets, offsets) 中选取。
safe – 如果为 True,则在强度溢出时进行安全的数据类型转换。默认为 False。例如,[256, -12] -> [array(0), array(244)]。如果为 True,则 [256, -12] -> [array(255), array(0)]。
factor_key – 如果不为 None,则将其用作从 key 相应元数据字典中提取运行时值并乘以随机 offset 来移动强度。通常,IntensityStatsd 转换可以预先计算强度值的统计信息并存储在元数据中。它也可以是字符串序列,映射到 keys。
meta_keys – 显式指定相应元数据字典的键。当 factor_key 不为 None 时用于提取因子值。例如,对于键为 image 的数据,元数据默认存储在 image_meta_dict 中。元数据是一个字典对象,包含:filename、original_shape 等。它可以是一个字符串序列,映射到 keys。如果为 None,则尝试通过 key_{meta_key_postfix} 构建 meta_keys。
meta_key_postfix – 如果 meta_keys 为 None,则根据键数据使用 key_{postfix} 获取元数据,默认为 meta_dict,元数据是一个字典对象。当 factor_key 不为 None 时用于提取因子值。
prob – 移动的概率。(默认 0.1,有 10% 的概率返回一个强度移动的数组)
channel_wise – 如果为 True,则对每个通道分别调整强度。对于每个通道,将选择一个随机偏移量。如果为 True,请确保第一个维度表示图像的通道。
allow_missing_keys – 如果键丢失,则不引发异常。
StdShiftIntensityd#
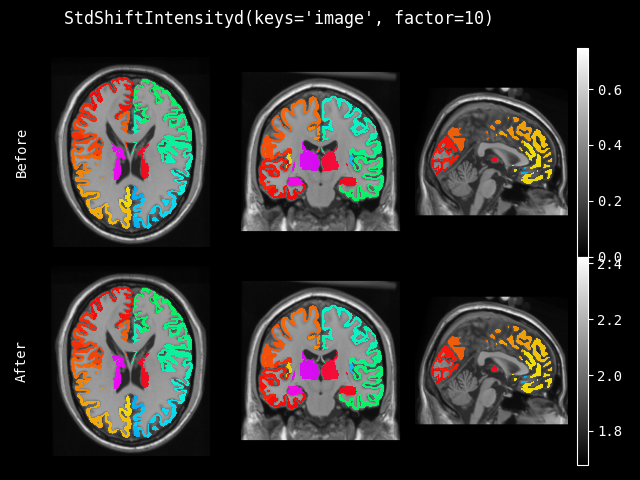
- class monai.transforms.StdShiftIntensityd(keys, factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.StdShiftIntensity包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, factor, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformfactor (
float) – 按v = v + factor * std(v)调整的因子。nonzero (
bool) – 是否只计算非零值。channel_wise (
bool) – 如果为 True,则对每个通道分别计算。如果为 True,请确保第一个维度表示图像的通道。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
RandStdShiftIntensityd#
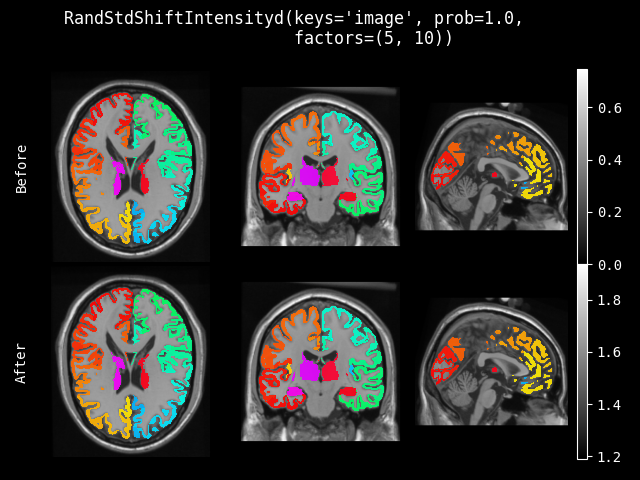
- class monai.transforms.RandStdShiftIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandStdShiftIntensity版本。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, prob=0.1, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfactors – 如果是元组,则随机选取范围为 (min(factors), max(factors))。如果是一个数字,则范围为 (-factors, factors)。
prob – 标准差调整的概率。
nonzero – 是否只计算非零值。
channel_wise – 如果为 True,则对每个通道分别计算。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
RandBiasFieldd#
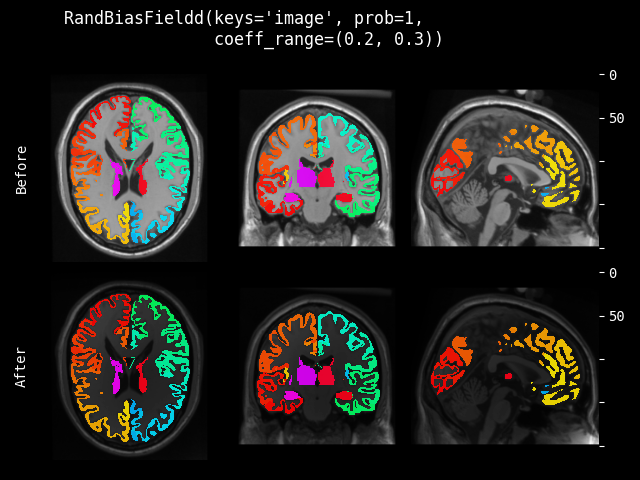
- class monai.transforms.RandBiasFieldd(keys, degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.RandBiasField版本。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, degree=3, coeff_range=(0.0, 0.1), dtype=<class 'numpy.float32'>, prob=0.1, allow_missing_keys=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformdegree (
int) – 多项式的自由度。该值应不小于 1。默认为 3。coeff_range (
tuple[float,float]) – 随机系数的范围。默认为 (0.0, 0.1)。dtype (
Union[dtype,type,str,None]) – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。prob (
float) – 执行随机偏置场的概率。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
ScaleIntensityd#
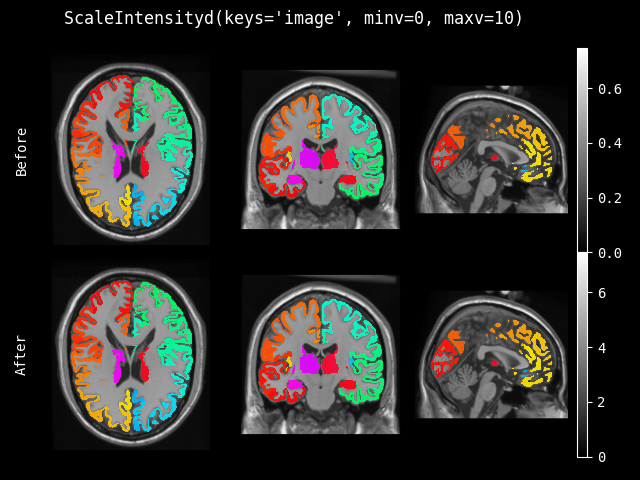
- class monai.transforms.ScaleIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ScaleIntensity包装器。将输入图像的强度缩放到给定值范围 (minv, maxv)。如果未提供 minv 和 maxv,则使用 factor 按v = v * (1 + factor)缩放图像。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, minv=0.0, maxv=1.0, factor=None, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformminv – 输出数据的最小值。
maxv – 输出数据的最大值。
factor – 按
v = v * (1 + factor)进行缩放的因子。要使用此参数,请将 minv 和 maxv 都设置为 None。channel_wise – 如果为 True,则对每个通道分别进行缩放。如果为 True,请确保第一个维度表示图像的通道。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
ClipIntensityPercentilesd#
- class monai.transforms.ClipIntensityPercentilesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ClipIntensityPercentiles包装器。根据输入图像的强度分布,将输入图像的强度值裁剪到特定范围。如果提供了 sharpness_factor,强度值将根据 f(x) = x + (1/sharpness_factor) * softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) 进行软裁剪。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict- 返回值:
应用转换后
data的更新字典版本。
RandScaleIntensityd#
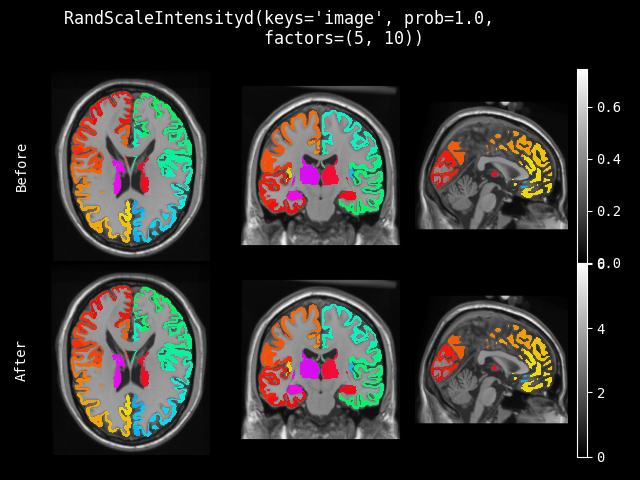
- class monai.transforms.RandScaleIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandScaleIntensity版本。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, prob=0.1, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfactors – 用于随机缩放的因子范围,缩放方式为
v = v * (1 + factor)。如果是一个数字,因子值从 (-factors, factors) 中选取。prob – 缩放的概率。(默认 0.1,有 10% 的概率返回一个缩放后的数组。)
channel_wise – 如果为 True,则对每个通道分别进行缩放。如果为 True,请确保第一个维度表示图像的通道。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
RandScaleIntensityFixedMeand#
- class monai.transforms.RandScaleIntensityFixedMeand(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandScaleIntensity版本。在用 factor 缩放之前减去平均强度,然后在缩放之后加上相同的值,以确保输出与输入具有相同的平均值。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, factors, fixed_mean=True, preserve_range=False, prob=0.1, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfactors – 用于随机缩放的因子范围,缩放方式为
v = v * (1 + factor)。如果是一个数字,因子值从 (-factors, factors) 中选取。preserve_range – 将输出数组/张量裁剪到输入数组/张量的范围。
fixed_mean – 在使用 factor 缩放之前减去平均强度,然后在缩放之后加上相同的值,以确保输出与输入具有相同的均值。
channel_wise – 如果为 True,则对每个通道分别进行缩放。如果 channel_wise 为 True,preserve_range 和 fixed_mean 也将分别应用于每个通道。如果为 True,请确保第一个维度表示图像的通道。
the (如果 channel_wise 为 True,则在每个通道上单独进行。请确保第一维度代表)
True. (图像的通道如果)
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
NormalizeIntensityd#
- class monai.transforms.NormalizeIntensityd(*args, **kwargs)[source]#
基于字典的
monai.transforms.NormalizeIntensity包装器。此转换可以仅标准化非零值或整个图像,也可以分别计算每个通道的均值和标准差。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
subtrahend – 要减去的量(通常是均值)
divisor – 要除以的量(通常是标准差)
nonzero – 是否只归一化非零值。
channel_wise – 如果为 True,则对每个通道分别计算,否则直接在整个图像上计算。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ThresholdIntensityd#
- class monai.transforms.ThresholdIntensityd(keys, threshold, above=True, cval=0.0, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.ThresholdIntensity包装器。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要转换的相应项的键。另请参见: monai.transforms.MapTransformthreshold (
float) – 用于过滤强度值的阈值。above (
bool) – 过滤高于阈值或低于阈值的值,默认为 True。cval (
float) – 用于填充图像剩余部分的值,默认为 0。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ScaleIntensityRanged#
- class monai.transforms.ScaleIntensityRanged(*args, **kwargs)[source]#
基于字典的
monai.transforms.ScaleIntensityRange包装器。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
a_min – 强度原始范围最小值。
a_max – 强度原始范围最大值。
b_min – 强度目标范围最小值。
b_max – 强度目标范围最大值。
clip – 是否在缩放后执行裁剪。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
GibbsNoised#
- class monai.transforms.GibbsNoised(keys, alpha=0.5, allow_missing_keys=False)[source]#
GibbsNoise 的基于字典的版本。
该变换对 2D/3D MRI 图像应用 Gibbs 噪声。Gibbs 伪影是 MRI 扫描中常见的伪影类型之一。
关于 Gibbs 伪影的一般信息,请参阅:https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – ‘image’、‘label’ 或 [‘image’, ‘label’],取决于您需要转换的数据。alpha (float) – 参数化应用的吉布斯噪声滤波器的强度。取值范围在 [0,1] 区间内,其中 alpha = 0 时相当于恒等映射。
allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RandGibbsNoised#
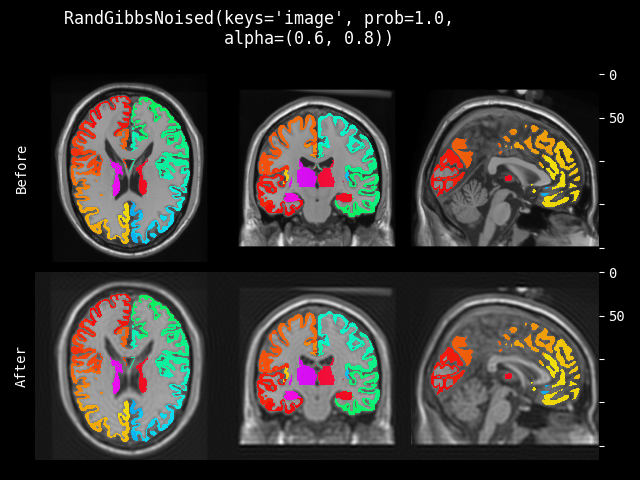
- class monai.transforms.RandGibbsNoised(*args, **kwargs)[source]#
RandGibbsNoise 的基于字典的版本。
通过 Gibbs 伪影进行自然图像增强。该变换随机对 2D/3D MRI 图像应用 Gibbs 噪声。Gibbs 伪影是 MRI 扫描中常见的伪影类型之一。
该变换应用于数据中的所有通道。
关于 Gibbs 伪影的一般信息,请参阅:https://pubs.rsna.org/doi/full/10.1148/rg.313105115 https://pubs.rsna.org/doi/full/10.1148/radiographics.22.4.g02jl14949
- 参数:
keys – ‘image’、‘label’ 或 [‘image’, ‘label’],取决于您需要转换的数据。
prob (float) – 应用变换的概率。
alpha (float, Sequence[float]) – 参数化应用的吉布斯噪声滤波器的强度。取值范围在 [0,1] 区间内,其中 alpha = 0 时相当于恒等映射。如果给定长度为 2 的列表 [a,b],则 alpha 的值将从区间 [a,b] 中均匀采样。如果给定一个浮点数,则 alpha 的值将从区间 [0, alpha] 中均匀采样。
allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
KSpaceSpikeNoised#
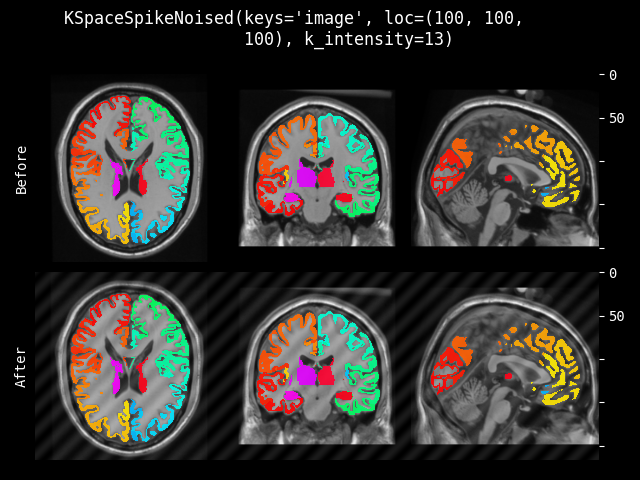
- class monai.transforms.KSpaceSpikeNoised(*args, **kwargs)[source]#
monai.transforms.KSpaceSpikeNoise的基于字典的封装。在给定位置和强度下的 k 空间中应用局部尖峰。尖峰(人字形)伪影是一种数据采集伪影,可能在 MRI 扫描期间发生。
关于尖峰伪影的一般信息,请参阅
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- 参数:
keys – “image”、“label” 或 [“image”, “label”],取决于您需要转换的数据。
loc – 尖峰的空间位置。对于具有 3D 空间维度的图像,用户可以提供 (C, X, Y, Z) 来固定受影响的通道 C,或者提供 (X, Y, Z) 以在所有通道中放置相同的尖峰。对于 2D 情况,用户可以提供 (C, X, Y) 或 (X, Y)。
k_intensity – 图像 k 空间版本的对数强度值。如果 loc 只传递一个位置或未指定通道,则此参数应接收一个浮点数。如果 loc 给定了一个位置序列,则此参数应接收一个强度序列。此值应进行测试,因为它取决于数据。默认值是每个通道对数强度的均值的 2.5 倍。
allow_missing_keys – 如果键缺失,不引发异常。
示例
处理 4D 数据时,
KSpaceSpikeNoised("image", loc = ((3,60,64,32), (64,60,32)), k_intensity = (13,14))会在 [3, 60, 64, 32] 位置放置一个对数强度为 13 的尖峰,并在 [: , 64, 60, 32] 位置为每个通道分别放置一个对数强度为 14 的尖峰。
RandKSpaceSpikeNoised#
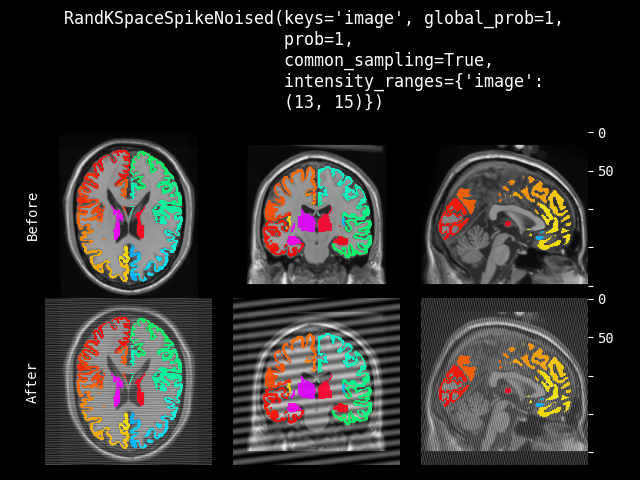
- class monai.transforms.RandKSpaceSpikeNoised(*args, **kwargs)[source]#
monai.transforms.RandKSpaceSpikeNoise的基于字典的版本。通过尖峰伪影进行自然数据增强。该变换在 k 空间中应用局部尖峰。
关于尖峰伪影的一般信息,请参阅
AAPM/RSNA physics tutorial for residents: fundamental physics of MR imaging.
Body MRI artifacts in clinical practice: A physicist’s and radiologist’s perspective.
- 参数:
keys – “image”、“label” 或 [“image”, “label”],取决于您需要转换的数据。
prob – 向字典中每个项目添加尖峰伪影的概率,前提是已确定将噪声应用于字典。
intensity_range – 传入一个元组 (a, b) 以从区间 (a, b) 中为所有通道均匀采样对数强度。或者传入一个区间序列 ((a0, b0), (a1, b1), …) 以分别采样每个通道。在第二种情况下,2 元组的数量必须与通道数匹配。默认范围为 (0.95x, 1.10x),其中 x 是每个通道的平均对数强度。
channel_wise – 独立处理每个通道。默认为 True。
allow_missing_keys – 如果键缺失,不引发异常。
示例
要仅对图像随机应用 k 空间尖峰,概率为 0.5,并且对数强度从区间 [13, 15] 中为每个通道独立采样,可以使用
RandKSpaceSpikeNoised("image", prob=0.5, intensity_ranges=(13, 15), channel_wise=True)。- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
RandRicianNoised#
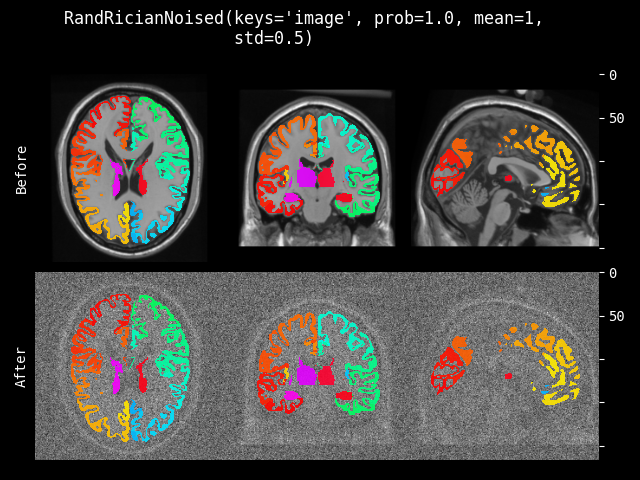
- class monai.transforms.RandRicianNoised(*args, **kwargs)[source]#
monai.transforms.RandRicianNoise的基于字典的版本。向图像添加 Rician 噪声。此变换假定所有预期字段具有相同的形状,如果想为每个字段添加不同的噪声,请单独使用此变换。- 参数:
keys – 需要变换的相应项目的键。另请参阅:
monai.transforms.compose.MapTransformprob – 向字典添加 Rician 噪声的概率。
mean – 构成 Rician 噪声的采样高斯分布的均值或“中心”。
std – 构成 Rician 噪声的采样高斯分布的标准差(分布范围)。
channel_wise – 如果为 True,则独立处理图像的每个通道。
relative – 如果为 True,则采样高斯分布的分布范围将是 std 乘以图像或通道强度直方图的标准差。
sample_std – 如果为 True,则从 0 到 std 范围内均匀采样高斯分布的分布范围。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
ScaleIntensityRangePercentilesd#
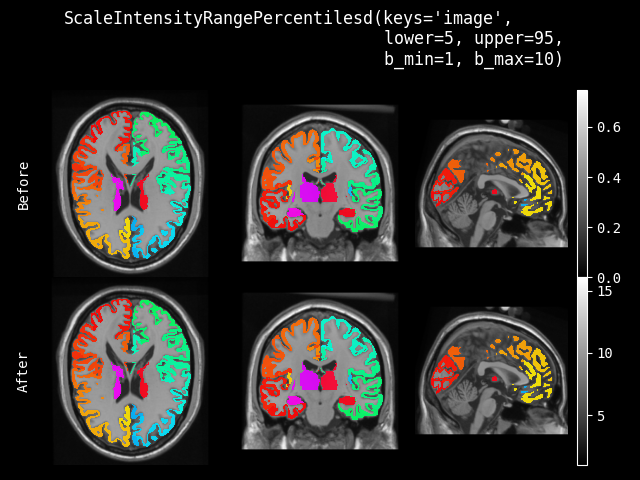
- class monai.transforms.ScaleIntensityRangePercentilesd(*args, **kwargs)[source]#
monai.transforms.ScaleIntensityRangePercentiles的基于字典的封装。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
lower – 下百分位数。
upper – 上百分位数。
b_min – 强度目标范围最小值。
b_max – 强度目标范围最大值。
clip – 是否在缩放后执行裁剪。
relative – 是否缩放到 [b_min, b_max] 的相应百分位数。
channel_wise – 如果为 True,则分别计算每个通道的强度百分位数并进行归一化。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
AdjustContrastd#
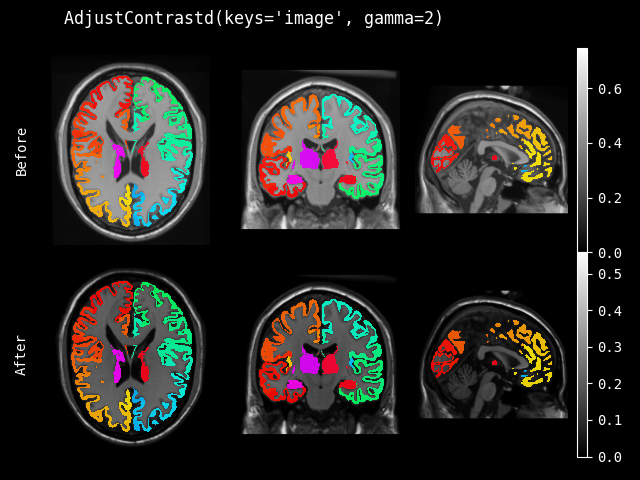
- class monai.transforms.AdjustContrastd(keys, gamma, invert_image=False, retain_stats=False, allow_missing_keys=False)[source]#
monai.transforms.AdjustContrast的基于字典的封装。使用伽马变换改变图像强度。每个像素/体素强度更新为x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要转换的相应项的键。另请参见: monai.transforms.MapTransformgamma (
float) – 用于按函数调整对比度的 gamma 值。invert_image (
bool) –是否在应用 gamma 增强之前反转图像。如果为 True,则在 gamma 变换之前和之后都将所有强度值乘以 -1。此行为模仿自 nnU-Net,特别是 此 函数。
retain_stats (
bool) –如果为 True,在 gamma 变换后对所有强度值应用一个缩放因子和偏移量,以确保输出强度分布与输入强度分布具有相同的均值和标准差。此行为模仿自 nnU-Net,特别是 此 函数。
allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RandAdjustContrastd#
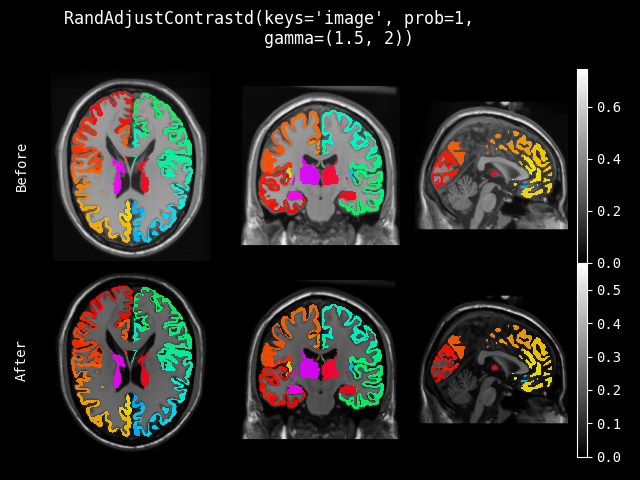
- class monai.transforms.RandAdjustContrastd(*args, **kwargs)[source]#
monai.transforms.RandAdjustContrast的基于字典的版本。使用伽马变换随机改变图像强度。每个像素/体素强度更新为x = ((x - min) / intensity_range) ^ gamma * intensity_range + min
- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
prob – 调整的概率。
gamma – gamma 值范围。如果是一个数字,值从 (0.5, gamma) 中选取,默认为 (0.5, 4.5)。
invert_image –
是否在应用 gamma 增强之前反转图像。如果为 True,则在 gamma 变换之前和之后都将所有强度值乘以 -1。此行为模仿自 nnU-Net,特别是 此 函数。
retain_stats –
如果为 True,在 gamma 变换后对所有强度值应用一个缩放因子和偏移量,以确保输出强度分布与输入强度分布具有相同的均值和标准差。此行为模仿自 nnU-Net,特别是 此 函数。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
MaskIntensityd#
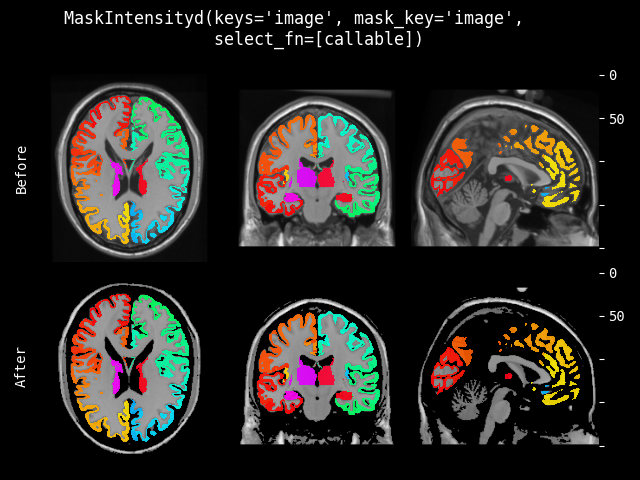
- class monai.transforms.MaskIntensityd(*args, **kwargs)[source]#
monai.transforms.MaskIntensity的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformmask_data – 如果掩膜数据是单通道,则应用于输入图像的每个通道。如果是多通道,通道数必须与输入数据匹配。输入图像中与掩膜数据中选定值相对应的强度值将保留原始值,其他值将设置为 0。如果为 None,则将根据 mask_key 从输入数据中提取掩膜数据。
mask_key – 从输入字典中提取掩膜数据的键,仅在 mask_data 为 None 时起作用。
select_fn – 用于选择 mask_data 有效值的函数,默认为选择 values > 0。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
SavitzkyGolaySmoothd#
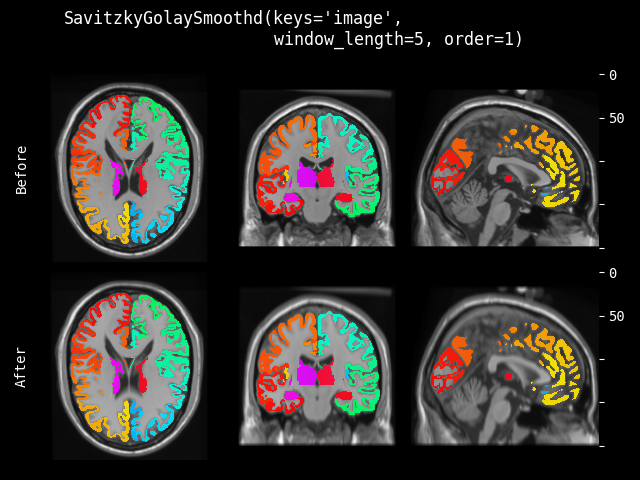
- class monai.transforms.SavitzkyGolaySmoothd(keys, window_length, order, axis=1, mode='zeros', allow_missing_keys=False)[source]#
monai.transforms.SavitzkyGolaySmooth的基于字典的封装。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformwindow_length (
int) – 滤波器窗口的长度,必须是正奇整数。order (
int) – 拟合每个窗口的多项式阶数,必须小于window_length。axis (
int) – 应用滤波器核的可选轴。默认为 1(第一个空间维度)。mode (
str) – 可选的填充模式,传递给卷积类。'zeros'、'reflect'、'replicate'或'circular'。默认值:'zeros'。请参阅torch.nn.Conv1d()以获取更多信息。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
MedianSmoothd#
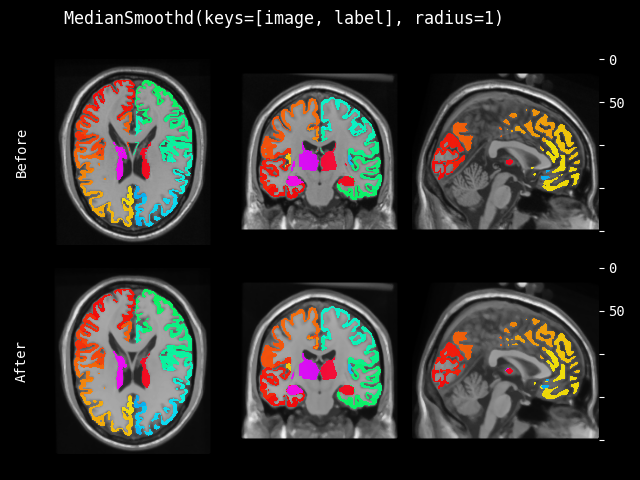
- class monai.transforms.MedianSmoothd(*args, **kwargs)[source]#
monai.transforms.MedianSmooth的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformradius – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
GaussianSmoothd#
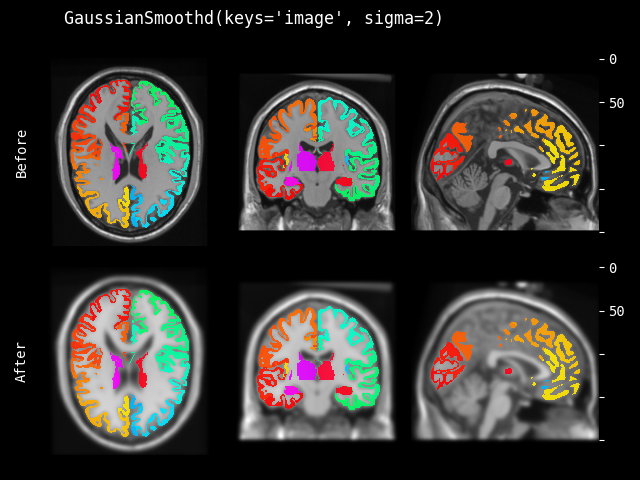
- class monai.transforms.GaussianSmoothd(*args, **kwargs)[source]#
monai.transforms.GaussianSmooth的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformsigma – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RandGaussianSmoothd#
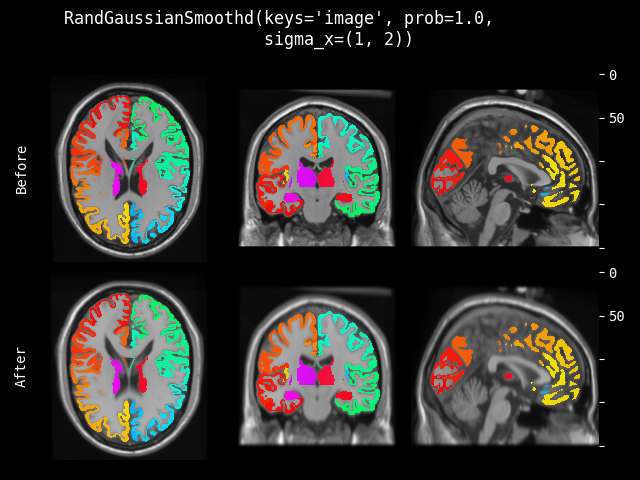
- class monai.transforms.RandGaussianSmoothd(keys, sigma_x=(0.25, 1.5), sigma_y=(0.25, 1.5), sigma_z=(0.25, 1.5), approx='erf', prob=0.1, allow_missing_keys=False)[source]#
monai.transforms.GaussianSmooth的基于字典的封装。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformsigma_x (
tuple[float,float]) – 随机选择第一个空间维度的 sigma 值。sigma_y (
tuple[float,float]) – 如果存在,随机选择第二个空间维度的 sigma 值。sigma_z (
tuple[float,float]) – 如果存在,随机选择第三个空间维度的 sigma 值。approx (
str) – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅monai.networks.layers.GaussianFilter()。prob (
float) – 高斯平滑的概率。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
GaussianSharpend#
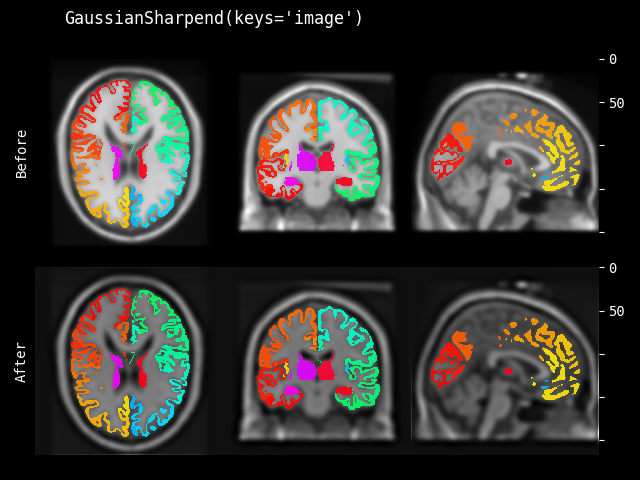
- class monai.transforms.GaussianSharpend(*args, **kwargs)[source]#
monai.transforms.GaussianSharpen的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformsigma1 – 第一个高斯核的 sigma 参数。如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
sigma2 – 第二个高斯核的 sigma 参数。如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
alpha – 用于计算最终结果的权重参数。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RandGaussianSharpend#
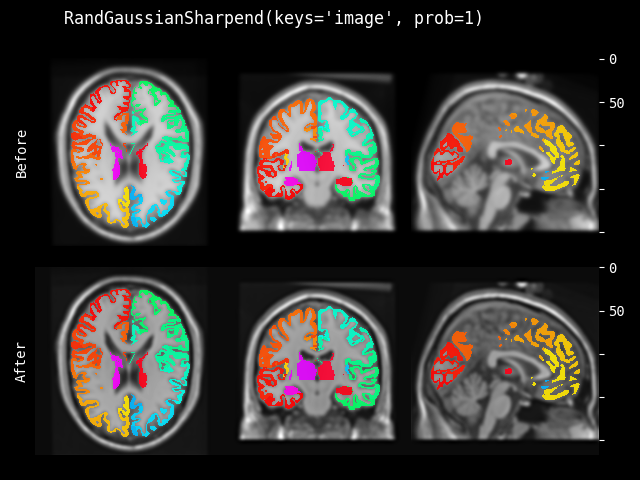
- class monai.transforms.RandGaussianSharpend(*args, **kwargs)[source]#
monai.transforms.GaussianSharpen的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformsigma1_x – 随机选择第一个高斯核的第一个空间维度的 sigma 值。
sigma1_y – 如果存在,随机选择第一个高斯核的第二个空间维度的 sigma 值。
sigma1_z – 如果存在,随机选择第一个高斯核的第三个空间维度的 sigma 值。
sigma2_x – 随机选择用于第二个高斯核第一空间维度的 sigma 值。如果只提供一个值 X,则它必须小于 sigma1_x 并在 [X, sigma1_x] 范围内随机选择。
sigma2_y – 随机选择用于第二个高斯核第二空间维度(如果存在)的 sigma 值。如果只提供一个值 Y,则它必须小于 sigma1_y 并在 [Y, sigma1_y] 范围内随机选择。
sigma2_z – 随机选择用于第二个高斯核第三空间维度(如果存在)的 sigma 值。如果只提供一个值 Z,则它必须小于 sigma1_z 并在 [Z, sigma1_z] 范围内随机选择。
alpha – 随机选择权重参数以计算最终结果。
approx – 离散高斯核类型,可用选项包括 “erf”、“sampled” 和 “scalespace”。另请参阅
monai.networks.layers.GaussianFilter()。prob – 高斯锐化的概率。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
RandHistogramShiftd#
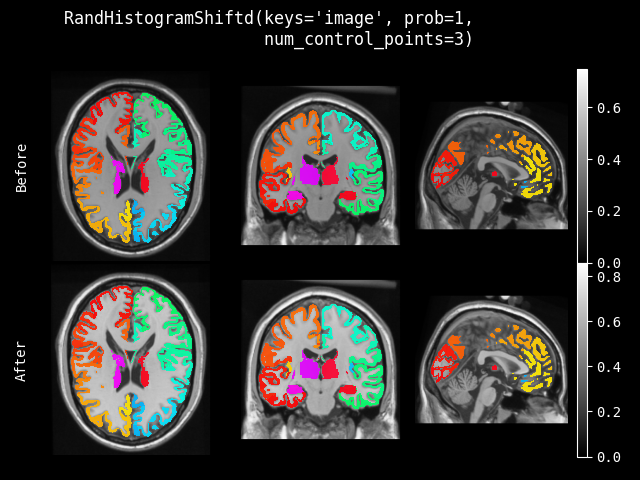
- class monai.transforms.RandHistogramShiftd(*args, **kwargs)[source]#
monai.transforms.RandHistogramShift的基于字典的版本。对图像的强度直方图应用随机非线性变换。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
num_control_points – 控制非线性强度映射的控制点数量。控制点数量越少,允许的强度偏移越大。如果提供两个值,则控制点数量从范围 (min_value, max_value) 中选择。
prob – 直方图偏移的概率。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
RandCoarseDropoutd#
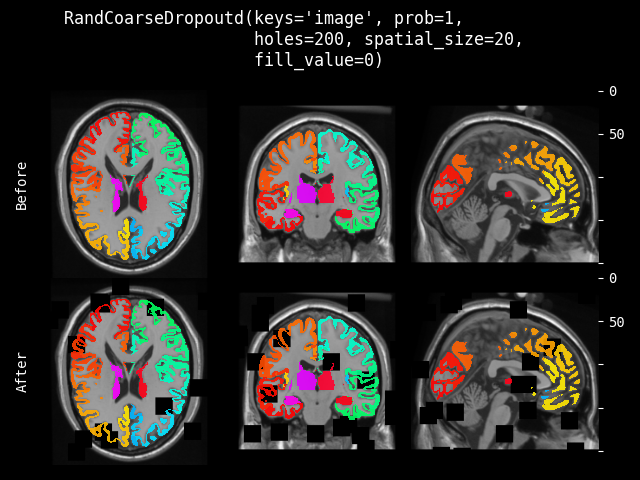
- class monai.transforms.RandCoarseDropoutd(*args, **kwargs)[source]#
monai.transforms.RandCoarseDropout的基于字典的封装。期望由 keys 指定的所有数据具有相同的空间形状,并且会为每个键随机丢弃相同的区域;如果想为每个键丢弃不同的区域,请单独使用此变换。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformholes – 要丢弃的区域数量,如果 max_holes 不是 None,则使用此参数作为随机选择预期区域数量的最小值。
spatial_size – 要丢弃区域的空间大小,如果 max_spatial_size 不是 None,则使用此参数作为随机选择每个区域大小的最小空间大小。如果 spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
dropout_holes – 如果为 True,则丢弃孔洞区域并填充值;如果为 False,则保留孔洞并丢弃外部区域并填充值。默认为 True。
fill_value – 用于填充丢弃区域的目标值,如果提供一个数字,将用作常数值填充所有区域。如果为 min 和 max 提供一个元组,将从范围 [min, max) 中为每个像素/体素随机选择值。如果为 None,将计算输入图像的 min 和 max 值,然后随机选择值进行填充,默认为 None。
max_holes – 如果不是 None,定义随机选择预期区域数量的最大值。
max_spatial_size – 如果不是 None,定义随机选择每个区域大小的最大空间大小。如果 max_spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 max_spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 应用变换的概率。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
RandCoarseShuffled#
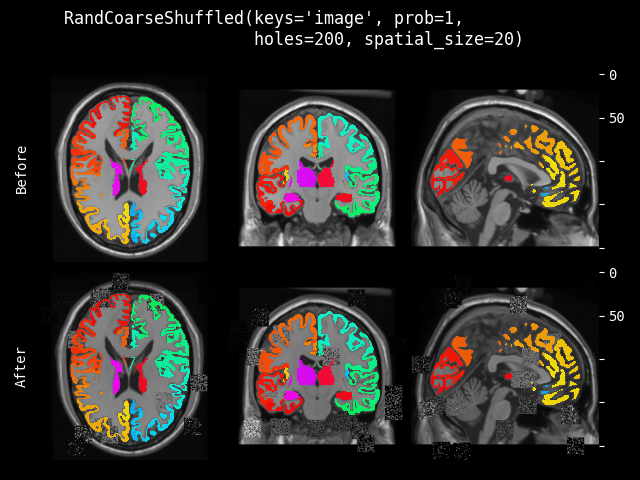
- class monai.transforms.RandCoarseShuffled(*args, **kwargs)[source]#
monai.transforms.RandCoarseShuffle的基于字典的封装。期望由 keys 指定的所有数据具有相同的空间形状,并且会为每个键随机打乱相同的区域;如果想为每个键打乱不同的区域,请单独使用此变换。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformholes – 要丢弃的区域数量,如果 max_holes 不是 None,则使用此参数作为随机选择预期区域数量的最小值。
spatial_size – 要丢弃区域的空间大小,如果 max_spatial_size 不是 None,则使用此参数作为随机选择每个区域大小的最小空间大小。如果 spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
max_holes – 如果不是 None,定义随机选择预期区域数量的最大值。
max_spatial_size – 如果不是 None,定义随机选择每个区域大小的最大空间大小。如果 max_spatial_size 的某些分量是非正值,变换将使用输入图像大小的对应分量。例如,如果图像的第二个空间维度大小为 64,则 max_spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 应用变换的概率。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
HistogramNormalized#
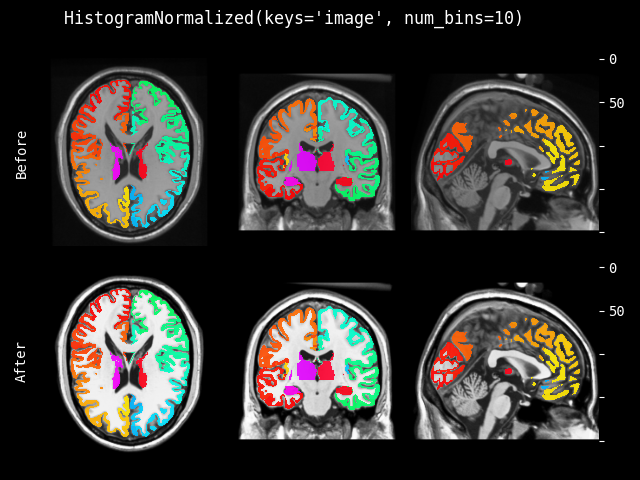
- class monai.transforms.HistogramNormalized(*args, **kwargs)[source]#
monai.transforms.HistogramNormalize的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformnum_bins – 直方图中使用的 bin 数量,默认为 256。更多详情请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.histogram.html。
min – 用于归一化输入图像的最小值,默认为 255。
max – 用于归一化输入图像的最大值,默认为 255。
mask – 如果提供,必须是 bool 或 0 和 1 的 ndarray,且与 image 形状相同。仅使用 mask==True 的点进行均衡化。也可以在运行时通过 mask_key 提供掩膜。
mask_key – 如果 mask 为 None,将尝试使用 mask_key 获取掩膜。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ForegroundMaskd#
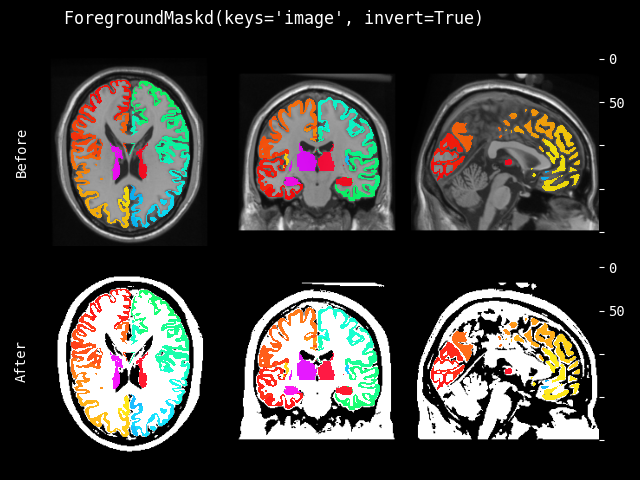
- class monai.transforms.ForegroundMaskd(*args, **kwargs)[source]#
根据 RGB 或 HSV 颜色空间的阈值创建定义前景的二进制掩膜。此变换接收一个 RGB(或灰度)图像,默认假定前景具有较低值(暗),而背景为白色。
- 参数:
keys – 需要变换的相应项目的键。
threshold – 定义阈值的整数或浮点数,小于该阈值的值被视为前景。它也可以是一个可调用对象,接收图像的每个维度并计算阈值,或者一个字符串,从 skimage.filter.threshold_… 定义此类可调用对象。有关可用阈值函数的列表,请参阅 https://scikit-image.cn/docs/stable/api/skimage.filters.html 此外,可以传入一个字典,为每个通道定义此类阈值,例如 {“R”: 100, “G”: “otsu”, “B”: skimage.filter.threshold_mean}
hsv_threshold – 类似于 threshold,但在 HSV 颜色空间(“H”、“S”和“V”)中。与 RBG 不同,在 HSV 中,大于 hsv_threshold 的值被视为前景。
invert – 反转输入图像的强度范围,使 dtype 最大值变为 dtype 最小值,反之亦然。
new_key_prefix – 此前缀将添加到键前面,以创建输出的新键并保持原始键的值不变。默认不设置前缀,键对应的数组将被替换。
allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ComputeHoVerMapsd#
- class monai.transforms.ComputeHoVerMapsd(keys, dtype='float32', new_key_prefix='hover_', allow_missing_keys=False)[source]#
从实例掩膜计算水平和垂直映射。它生成到每个区域质心的归一化水平和垂直距离。
- 参数:
keys (
Union[Collection[Hashable],Hashable]]) – 需要变换的相应项目的键。dtype (
Union[dtype,type,str,None]) – 输出张量的类型。默认为 “float32”。new_key_prefix (
str) – 此前缀将添加到键前面,以创建输出的新键并保持原始键的值不变。默认为 ‘“_hover”,因此如果输入键是“mask”,输出将是“hover_mask”。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
IO(字典)#
LoadImaged#
- class monai.transforms.LoadImaged(*args, **kwargs)[source]#
monai.transforms.LoadImage的基于字典的封装,它可以加载图像数据和元数据。当在一个键中加载文件列表时,数组将被堆叠,并添加一个新的维度作为第一个维度。在这种情况下,第一个图像的元数据将用于表示堆叠结果。所有堆叠图像的仿射变换应相同。输出元数据字段将创建为 meta_keys 或 key_{meta_key_postfix}。如果未指定读取器,此类将根据支持的后缀并按以下顺序自动选择读取器
调用此加载器时在运行时用户指定的读取器。
在 LoadImage 构造函数中用户指定的读取器。
注册列表中的读取器,从最后一个到第一个。
当前默认读取器:(nii, nii.gz -> NibabelReader), (png, jpg, bmp -> PILReader), (npz, npy -> NumpyReader), (dcm, DICOM 系列及其他 -> ITKReader)。
请注意,对于 png、jpg、bmp 和其他 2D 格式,读取器默认在加载数组后将
reverse_indexing设置为True来交换轴 0 和 1,因为非医学特定文件格式的空间轴定义与其他常见医学包不同。注意
如果指定了 reader,加载器将尝试使用指定的读取器和默认支持的读取器。这在处理尝试不兼容加载器的异常时可能会引入开销。在这种情况下,建议将最合适的读取器设置为 reader 参数的最后一项。
另请参阅
- __init__(keys, reader=None, dtype=<class 'numpy.float32'>, meta_keys=None, meta_key_postfix='meta_dict', overwriting=False, image_only=True, ensure_channel_first=False, simple_keys=False, prune_meta_pattern=None, prune_meta_sep='.', allow_missing_keys=False, expanduser=True, *args, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformreader – 用于加载图像文件和元数据的读取器 - 如果 reader 为 None,将使用一组默认的 SUPPORTED_READERS。 - 如果 reader 是字符串,则将其视为类名或点分路径(例如
"monai.data.ITKReader"),支持的内置读取器类有"ITKReader"、"NibabelReader"、"NumpyReader"。将使用 *args 和 **kwargs 参数构造读取器实例。 - 如果 reader 是读取器类/实例,则会将其注册到此加载器。dtype – 如果不为 None,将加载的图像数据转换为此数据类型。
meta_keys – 明确指定存储相应元数据字典的键。元数据是一个字典对象,包含:文件名、原始形状等。它可以是一个字符串序列,映射到 keys。如果为 None,将尝试通过 key_{meta_key_postfix} 构建 meta_keys。
meta_key_postfix – 如果 meta_keys 为 None,使用 key_{postfix} 存储 nifti 图像的元数据,默认值为 meta_dict。元数据是一个字典对象。例如,加载 image 的 nifti 文件,将其元数据存储到 image_meta_dict 中。
overwriting – 是否允许覆盖具有相同键的现有元数据。默认为 False,如果遇到现有键将引发异常。
image_only – 如果为 True,返回只包含图像体素的字典;否则,返回包含每个输入键的图像数据数组和头部字典的字典。
ensure_channel_first – 如果 True 且同时加载了图像数组和元数据,则自动将图像数组形状转换为通道优先。默认为 False。
simple_keys – 是否移除冗余的元数据键,为向后兼容性默认为 False。
prune_meta_pattern – 与 prune_meta_sep 结合使用,是一个正则表达式,用于匹配和修剪元数据(嵌套字典)中的键,默认为 None,不删除键。
prune_meta_sep – 与 prune_meta_pattern 结合使用,用于匹配和修剪元数据(嵌套字典)中的键。默认为 ".",另请参阅
monai.transforms.DeleteItemsd。例如,prune_meta_pattern=".*_code$", prune_meta_sep=" "会移除以"_code"结尾的元数据键。allow_missing_keys – 如果键丢失,则不引发异常。
expanduser – 如果为 True,将文件名转换为 Path 并对其调用 .expanduser,否则保持文件名不变。
args – 如果提供读取器名称,则为读取器的附加参数。
kwargs – 如果提供读取器名称,则为读取器的附加参数。
SaveImaged#
- class monai.transforms.SaveImaged(*args, **kwargs)[source]#
monai.transforms.SaveImage的基于字典的封装。注意
图像应为通道优先形状:[C,H,W,[D]]。如果数据是图像的一个补丁,补丁索引将附加到文件名中。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformmeta_keys – 明确指定相应元数据字典的键。例如,对于键为 image 的数据,元数据默认位于 image_meta_dict 中。元数据是一个包含 filename、original_shape 等值的字典。此参数可以是一个字符串序列,映射到 keys。如果 None,将尝试通过 key_{meta_key_postfix} 构建 meta_keys。
meta_key_postfix – 如果 meta_keys 为 None,使用 key_{meta_key_postfix} 检索元数据字典。
output_dir – 输出图像目录。如果
folder_layout不是None,则由folder_layout处理。output_postfix – 附加到所有输出文件名的字符串,默认为 trans。如果 folder_layout 不为 None,则改由 folder_layout 处理。
output_ext – 输出文件扩展名,可用扩展名:.nii.gz、.nii、.png、.dcm。如果 folder_layout 不为 None,则改由 folder_layout 处理。
resample – 在保存数据数组之前是否对图像进行重采样(如果需要),基于元数据中的 spatial_shape(和 original_affine)。
mode –
此选项在
resample=True时使用。默认为"nearest"。根据写入器不同,可能的选项包括{
"bilinear","nearest","bicubic"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-sample{
"nearest","linear","bilinear","bicubic","trilinear","area"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#interpolate
padding_mode – 此选项在
resample = True时使用。默认为"border"。可能的选项包括 {"zeros","border","reflection"}。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-samplescale – {
255,65535} 通过裁剪到 [0, 1] 并缩放到 [0, 255] (uint8) 或 [0, 65535] (uint16) 来后处理数据。默认值为None(不缩放)。dtype – 重采样计算期间的数据类型。默认为 np.float64 以获得最佳精度。如果为 None,使用输入数据的数据类型。要设置输出数据类型,请使用 output_dtype。
output_dtype – 保存数据的数据类型。默认为 np.float32。
allow_missing_keys – 如果键丢失,则不引发异常。
squeeze_end_dims – 如果为 True,任何末尾的单维(在通道移到末尾之后)将被移除。因此,如果输入是 (C,H,W,D),将改为 (H,W,D,C),然后如果 C==1,将保存为 (H,W,D)。如果 D 也为 1,将保存为 (H,W)。如果为 false,图像将始终保存为 (H,W,D,C)。
data_root_dir –
如果非空,它指定输入文件绝对路径的起始部分。它用于计算
input_file_rel_path,即文件从data_root_dir的相对路径,以在保存时保留文件夹结构,以防不同文件夹中有同名文件。例如,对于以下输入input_file_name:
/foo/bar/test1/image.niioutput_postfix:
segoutput_ext:
.nii.gzoutput_dir:
/outputdata_root_dir:
/foo/bar
输出将是:
/output/test1/image/image_seg.nii.gz如果
folder_layout不是None,则由folder_layout处理。separate_folder – 是否将每个文件保存在单独的文件夹中。例如:对于输入文件名 image.nii,后缀为 seg,文件夹路径为 output,如果 separate_folder=True,将保存为:output/image/image_seg.nii;如果为 False,保存为 output/image_seg.nii。默认为 True。如果 folder_layout 不为 None,则改由 folder_layout 处理。
print_log – 保存时是否打印日志。默认为
True。output_format – 用于指定输出图像写入器的可选字符串。另请参阅:
monai.data.image_writer.SUPPORTED_WRITERS。writer – 用于保存数据数组的自定义 monai.data.ImageWriter 子类。如果 None,根据 output_ext 使用 monai.data.image_writer 中的默认写入器。如果是字符串,则将其视为类名或点分路径;支持的内置写入器类有 "NibabelWriter"、"ITKWriter"、"PILWriter"。
output_name_formatter – 一个可调用函数(返回一个 kwargs 字典)用于格式化输出文件名。另请参阅:
monai.data.folder_layout.default_name_formatter()。如果使用自定义 folder_layout,请考虑提供自己的格式化器。folder_layout – 一个自定义的
monai.data.FolderLayoutBase子类,用于定义文件命名方案。如果为None,则使用默认的FolderLayout。savepath_in_metadict – 如果 True,向元数据添加一个键 saved_to,其中包含输入图像保存到的路径。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
WriteFileMappingd#
- class monai.transforms.WriteFileMappingd(*args, **kwargs)[source]#
monai.transforms.WriteFileMapping的基于字典的封装。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformmapping_file_path – 保存映射的 JSON 文件路径。默认为 “mapping.json”。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
后处理(字典)#
Activationsd#
- class monai.transforms.Activationsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.AddActivations包装器。为 keys 指定的输入数据添加激活层。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, sigmoid=False, softmax=False, other=None, allow_missing_keys=False, **kwargs)[source]#
- 参数:
keys – 模型输出和标签对应项的键。另请参阅:
monai.transforms.compose.MapTransformsigmoid – 是否在变换前对模型输出执行 sigmoid 函数。也可以是布尔值序列,每个元素对应
keys中的一个键。softmax – 是否在变换前对模型输出执行 softmax 函数。也可以是布尔值序列,每个元素对应
keys中的一个键。other – 用于执行其他激活层的可调用函数,例如:other = torch.tanh。也可以是 Callable 序列,每个元素对应
keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
kwargs – 传递给 torch.softmax 的附加参数 (当
softmax=True时使用)。默认为dim=0,未识别的参数将被忽略。
AsDiscreted#
- class monai.transforms.AsDiscreted(*args, **kwargs)[source]#
基于字典的
monai.transforms.AsDiscrete包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, argmax=False, to_onehot=None, threshold=None, rounding=None, allow_missing_keys=False, **kwargs)[source]#
- 参数:
keys – 模型输出和标签对应项的键。另请参阅:
monai.transforms.compose.MapTransformargmax – 是否在变换前对输入数据执行 argmax 函数。也可以是布尔值序列,每个元素对应
keys中的一个键。to_onehot – 如果非 None,则将输入数据转换为指定类别数的 one-hot 格式。默认为
None。也可以是序列,每个元素对应keys中的一个键。threshold – 如果非 None,则使用指定的阈值将浮点值阈值化为整数 0 或 1。默认为
None。也可以是序列,每个元素对应keys中的一个键。rounding – 如果非 None,则根据指定选项对数据进行四舍五入,可用选项:[“torchrounding”]。也可以是 str 或 None 序列,每个元素对应
keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
kwargs – 传递给
AsDiscrete的附加参数。支持dim、keepdim、dtype参数,未识别的参数将被忽略。这些参数默认值分别为0、True、torch.float。
KeepLargestConnectedComponentd#
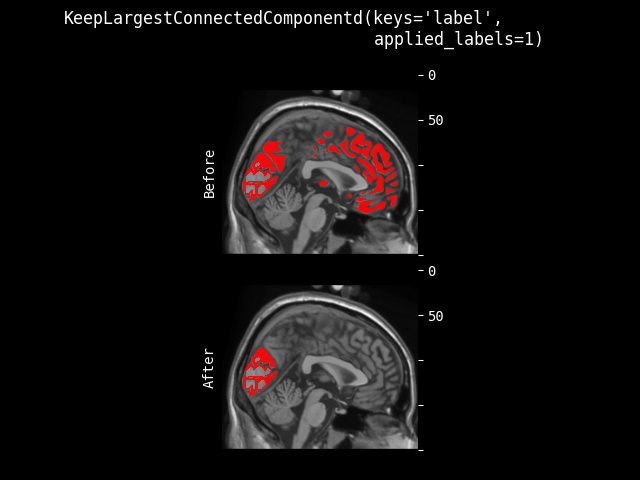
- class monai.transforms.KeepLargestConnectedComponentd(*args, **kwargs)[source]#
基于字典的
monai.transforms.KeepLargestConnectedComponent包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, applied_labels=None, is_onehot=None, independent=True, connectivity=None, num_components=1, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformapplied_labels – 对其应用连通分量分析的标签。如果给定,则将分析值在此列表中的体素。如果 None,则将分析所有非零值。
is_onehot – 如果 True,将输入数据视为 OneHot 格式数据,否则视为非 OneHot 格式数据。默认为 None,将多通道数据视为 OneHot,单通道数据视为非 OneHot。
independent – 是否将
applied_labels视为前景标签的联合。如果True,将独立地对每个前景标签执行连通分量分析并返回最大连通分量的交集。如果False,将对前景标签的联合执行分析。默认为 True。connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅:https://scikit-image.cn/docs/dev/api/skimage.measure.html#skimage.measure.label。num_components – 要保留的最大连通分量的数量。
allow_missing_keys – 如果键丢失,则不引发异常。
DistanceTransformEDTd#
- class monai.transforms.DistanceTransformEDTd(*args, **kwargs)[source]#
对输入应用欧几里得距离变换。可以是基于 GPU(使用 CuPy / cuCIM)或基于 CPU(使用 scipy)。要使用 GPU 实现,请确保 cuCIM 可用且数据是 GPU 设备上的 torch.tensor。
请注意,不同库的结果可能有所不同,因此如果可能,请坚持使用一种。详细信息请查阅 SciPy 和 cuCIM 文档和/或
monai.transforms.utils.distance_transform_edt()。- 关于输入形状的说明
必须是 channel first 数组,形状必须为:(num_channels, H, W [,D])。可以是任何类型,但会被转换为二值:图像等于 True 的地方为 1,其他地方为 0。输入按通道传递给距离变换,因此此函数的结果将与直接调用 CuPy 或 SciPy 中的
distance_transform_edt()不同。
- 参数:
keys – 需要变换的相应项目的键。
allow_missing_keys – 如果键丢失,则不引发异常。
sampling – 沿每个维度的元素间距。如果是序列,其长度必须等于输入秩减 1;如果是单个数字,则用于所有轴。如果未指定,则表示单位网格间距。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Mapping[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RemoveSmallObjectsd#

- class monai.transforms.RemoveSmallObjectsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RemoveSmallObjects包装器。- 参数:
min_size – 小于此尺寸(以体素数量计;如果 by_measure 为 True,则以图像单位表示的表面积/体积值)的对象将被移除。
connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅链接的 scikit-image 文档。independent_channels – 是否将通道视为独立的。如果为 true,则来自不同标签的连接岛屿如果小于阈值将被移除。如果为 false,则使用由所有非背景体素组成的岛屿的总大小。
by_measure – 指定的 min_size 是否以体素数量计。如果为 True,则 min_size 表示以图像单位(mm^3, cm^2 等)表示的表面积或体积值。默认为 False。例如,如果 min_size 为 3,by_measure 为 True,且数据单位为 mm,则移除小于 3mm^3 的对象。
pixdim – 输入图像的像素尺寸。如果为单个数字,则用于所有轴。如果是数字序列,序列长度必须等于图像维度。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
LabelFilterd#
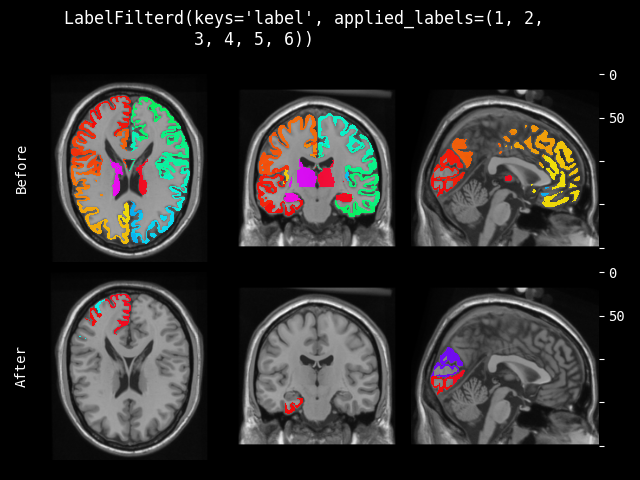
- class monai.transforms.LabelFilterd(*args, **kwargs)[source]#
基于字典的
monai.transforms.LabelFilter包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
FillHolesd#
- class monai.transforms.FillHolesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.FillHoles包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, applied_labels=None, connectivity=None, allow_missing_keys=False)[source]#
初始化连接性并限制要填充空洞的标签。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformapplied_labels (Optional[Union[Iterable[int], int]], optional) – 需要填充孔洞的标签。默认为 None,即填充所有标签的孔洞。
connectivity (int, optional) – 考虑像素/体素为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。默认为
input.ndim的完全连接。allow_missing_keys – 如果键丢失,则不引发异常。
LabelToContourd#
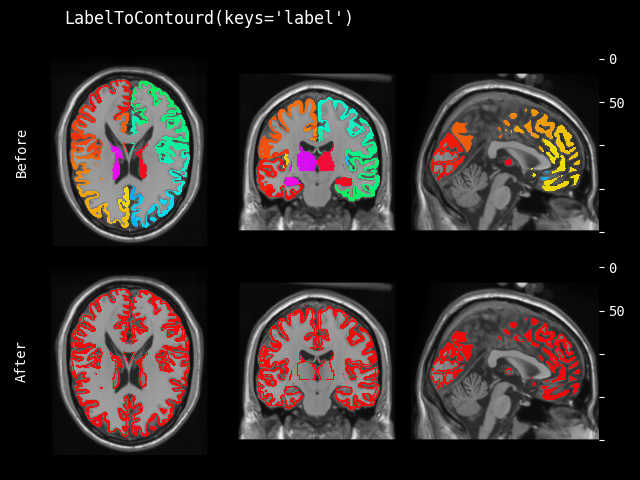
- class monai.transforms.LabelToContourd(keys, kernel_type='Laplace', allow_missing_keys=False)[source]#
基于字典的
monai.transforms.LabelToContour包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
Ensembled#
- class monai.transforms.Ensembled(*args, **kwargs)[source]#
基于字典的集成变换的基类。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, ensemble, output_key=None, allow_missing_keys=False)[source]#
- 参数:
keys – 要堆叠并执行集成的对应项的键。如果只提供 1 个键,则假定它是数据在维度 E 上堆叠的 PyTorch Tensor。
output_key – 在字典中存储集成结果的键。
ensemble – 在指定数据上执行集成的可调用方法。如果 keys 中只提供 1 个键,output_key 可以为 None 并使用 keys 作为默认值。
allow_missing_keys – 如果键丢失,则不引发异常。
- 抛出异常:
TypeError – 当
ensemble不可调用时。ValueError – 当
len(keys) > 1且output_key=None时。不兼容的值。
MeanEnsembled#
- class monai.transforms.MeanEnsembled(*args, **kwargs)[source]#
基于字典的
monai.transforms.MeanEnsemble包装器。- __init__(keys, output_key=None, weights=None)[source]#
- 参数:
keys – 要堆叠并执行集成的对应项的键。如果只提供 1 个键,则假定它是数据在维度 E 上堆叠的 PyTorch Tensor。
output_key – 在字典中存储集成结果的键。如果 keys 中只提供 1 个键,output_key 可以为 None 并使用 keys 作为默认值。
weights – 对于形状为:[E, C, H, W[, D]] 的输入数据,可以是数字列表或元组。也可以是 Numpy ndarray 或 PyTorch 张量数据。weights 将从最高维度添加到输入数据,例如:1. 如果 weights 只有 1 个维度,它将添加到输入数据的 E 维度。2. 如果 weights 有两个维度,它将添加到 E 和 C 维度。为不同类别添加权重是一种典型的做法:集成 3 个分割模型输出,每个输出有 4 个通道(类别),因此输入数据形状可以是:[3, 4, H, W, D]。为不同类别添加不同的 weights,因此 weights 形状可以是:[3, 4]。例如:weights = [[1, 2, 3, 4], [4, 3, 2, 1], [1, 1, 1, 1]]。
VoteEnsembled#
- class monai.transforms.VoteEnsembled(*args, **kwargs)[source]#
基于字典的
monai.transforms.VoteEnsemble包装器。
Invertd#
- class monai.transforms.Invertd(*args, **kwargs)[source]#
用于反转先前应用的变换的实用变换。
获取之前应用于
orig_keys的transform,此Invertd会将其逆变换应用于存储在keys处的数据。Invertd的输出还将包含元数据字典的副本(最初来自orig_meta_keys或orig_keys的元数据),其相关字段已被反转并存储在meta_keys处。典型的用法是将预处理(
transform=preprocessings)的逆变换应用于输入orig_keys=image,然后应用于模型预测keys=pred。详细用法示例请参阅教程:Project-MONAI/tutorials
注意
反转后的数据和元数据将分别存储在
keys和meta_keys处。要正确反转变换,先前应用的变换信息应可在
{orig_keys}_transforms处获得,原始元数据可在orig_meta_keys处获得。(meta_key_postfix是一个可选字符串,用于方便地构建“meta_keys”和/或“orig_meta_keys”。)另请参阅:monai.transforms.TraceableTransform。此变换不会更改
orig_keys和orig_meta_key中的内容。这些键仅用于表示反转前key的数据状态。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Any]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, transform, orig_keys=None, meta_keys=None, orig_meta_keys=None, meta_key_postfix='meta_dict', nearest_interp=True, to_tensor=True, device=None, post_func=None, allow_missing_keys=False)[source]#
- 参数:
keys – 字典中预期数据的键,
transforms的逆变换将原地应用于它。也可以是键列表,将分别应用逆变换。transform – 应用于
orig_key的变换,其逆变换将应用于key。orig_keys – 字典中原始输入数据的键。如果未设置,这些键默认为 self.keys。`transforms` 的变换跟踪信息应存储在
{orig_keys}_transforms处。也可以是键列表,每个键与keys匹配。meta_keys – 输出反转后的元数据字典的键。元数据是一个字典,可选地包含:filename, original_shape。可以是字符串序列,映射到
keys。如果为 None,将尝试使用默认键 {key}_{meta_key_postfix} 创建元数据字典。orig_meta_keys – 原始输入数据元数据的键。元数据是一个字典,可选地包含:filename, original_shape。可以是字符串序列,映射到 keys。如果为 None,将尝试使用默认键 {orig_key}_{meta_key_postfix} 创建元数据字典。此元数据字典也将包含在反转后的字典中,存储在 meta_keys 中。
meta_key_postfix – 如果 orig_meta_keys 为 None,则使用 {orig_key}_{meta_key_postfix} 从字典中获取元数据;如果 meta_keys 为 None,则使用 {key}_{meta_key_postfix}。默认值:
"meta_dict"。nearest_interp – 反转空间变换时是否使用 nearest 插值模式,默认为 True。如果为 False,则使用与原始变换相同的插值模式。也可以是布尔值列表,每个与 keys 数据匹配。
to_tensor – 是否首先将反转后的数据转换为 PyTorch Tensor,默认为 True。也可以是布尔值列表,每个与 keys 数据匹配。
device – 如果转换为 Tensor,则在 post_func 之前将反转结果移动到目标设备,默认为 None,也可以是字符串列表或 torch.device,每个与 keys 数据匹配。
post_func – 反转数据的后处理函数,应该是一个可调用函数。也可以是 Callable 列表,每个与 keys 数据匹配。
allow_missing_keys – 如果键丢失,则不引发异常。
SaveClassificationd#
- class monai.transforms.SaveClassificationd(*args, **kwargs)[source]#
将分类结果和元数据保存到 CSV 文件或其他存储介质中。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, meta_keys=None, meta_key_postfix='meta_dict', saver=None, output_dir='./', filename='predictions.csv', delimiter=',', overwrite=True, flush=True, allow_missing_keys=False)[source]#
- 参数:
keys – 模型输出对应项的键,此变换仅支持 1 个键。另请参阅:
monai.transforms.compose.MapTransformmeta_keys – 明确指定对应元数据字典的键。例如,对于键为 image 的数据,元数据默认位于 image_meta_dict 中。元数据是包含以下信息的字典对象:filename, original_shape 等。可以是字符串序列,映射到 keys。如果为 None,将尝试通过 key_{meta_key_postfix} 构造 meta_keys。将提取输入图像的文件名以保存分类结果。
meta_key_postfix – 在 LoadImaged 中使用 key_{postfix} 存储元数据。因此需要该键来提取输入图像的元数据,如 filename 等。默认值为 meta_dict。例如,对于键为 image 的数据,元数据默认位于 image_meta_dict 中。元数据是包含以下信息的字典对象:filename, original_shape 等。此参数仅在 meta_keys=None 时有效。如果没有相应的元数据,请设置为 None。
saver – 用于保存分类结果的 saver 实例,如果为 None,则内部创建一个 CSVSaver。saver 必须提供 save(data, meta_data) 和 finalize() API。
output_dir – 如果 saver=None,指定保存 CSV 文件的目录。
filename – 如果 saver=None,指定保存的 CSV 文件的名称。
delimiter – 保存文件中使用的分隔符字符,默认为“,”,因为默认输出类型为 csv。与以下内容保持一致:https://docs.pythonlang.cn/3/library/csv.html#csv.Dialect.delimiter。
overwrite – 如果 saver=None,指示是否覆盖现有 CSV 文件内容,如果为 True,则在保存前清空文件。否则,将新内容追加到 CSV 文件。
flush – 如果 saver=None,指示是否在此变换中立即将缓存数据写入 CSV 文件并清除缓存。默认为 True。如果为 False,用户可能需要手动调用 saver.finalize() 或使用 ClassificationSaver 处理程序。
allow_missing_keys – 如果键丢失,则不引发异常。
ProbNMSd#
- class monai.transforms.ProbNMSd(*args, **kwargs)[source]#
通过迭代选择概率最高的坐标,然后移除该坐标及其周围的值,在概率图上执行基于概率的非最大抑制(NMS)。移除范围由参数 box_size 决定。如果多个坐标具有相同的最高概率,则只选择其中一个。
- 参数:
spatial_dims – 输入概率图的空间维度数量。默认为 2。
sigma – 高斯滤波器的标准差。可以是一个单独的值,也可以是 spatial_dims 个值。默认为 0.0。
prob_threshold – 概率阈值,如果最高概率不大于该阈值,函数将停止搜索。该值应不小于 0.0。默认为 0.5。
box_size – 围绕具有最大概率的像素移除的框大小(以像素为单位)。可以是一个整数,定义方形或立方体的大小,也可以是一个包含每个维度不同值的列表。默认为 48。
- 返回值:
选定列表的列表,其中内部列表包含概率和坐标。例如,对于 3D 输入,内部列表的形式为 [probability, x, y, z]。
- 抛出异常:
ValueError – 当
prob_threshold小于 0.0 时。ValueError – 当
box_size是列表或元组,且其长度不等于 spatial_dims 时。ValueError – 当
box_size的值小于 1 时。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
SobelGradientsd#
- class monai.transforms.SobelGradientsd(*args, **kwargs)[source]#
计算灰度图像的 Sobel 水平梯度和垂直梯度。
- 参数:
keys – 模型输出对应项的键。
kernel_size – Sobel 核的大小。默认为 3。
spatial_axes – 定义梯度计算方向的轴。它沿提供的每个轴计算梯度。默认计算所有空间轴的梯度。
normalize_kernels – 是否归一化 Sobel 核以提供正确的梯度。默认为 True。
normalize_gradients – 是否将输出梯度归一化到 0 和 1。默认为 False。
padding_mode – 与 Sobel 核卷积时图像的填充模式。默认为 “reflect”。可接受的值有
'zeros'、'reflect'、'replicate'或'circular'。更多信息请参阅torch.nn.Conv1d()。dtype – 核数据类型 (torch.dtype)。默认为 torch.float32。
new_key_prefix – 此前缀将添加到键前面,以创建输出的新键并保持原始键的值不变。默认不设置前缀,键对应的数组将被替换。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
正则化 (字典)#
CutMixd#
- class monai.transforms.CutMixd(*args, **kwargs)[source]#
基于字典的
monai.transforms.CutMix版本。请注意,为了一致性,所有条目的混合权重将相同,即图像和标签必须以相同的权重进行聚合,但随机裁剪则不同。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
CutOutd#
- class monai.transforms.CutOutd(keys, batch_size, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.CutOut版本。请注意,字典中的每个条目的 cutout 是不同的。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
MixUpd#
- class monai.transforms.MixUpd(keys, batch_size, alpha=1.0, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.MixUp版本。请注意,为了一致性,所有条目的 mixup 变换将相同,即必须对图像和标签应用相同的增强。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
信号 (字典)#
SignalFillEmptyd#
- class monai.transforms.SignalFillEmptyd(keys=None, allow_missing_keys=False, replacement=0.0)[source]#
对输入应用 SignalFillEmptyd 变换。所有 NaN 值将被替换为 replacement 值。
- 参数:
keys (
Union[Collection[Hashable],Hashable,None]) – 模型输出对应项的键。allow_missing_keys (
bool) – 如果键缺失,不引发异常。replacement – NaN 条目将被映射到的值。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Mapping[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
空间 (字典)#
SpatialResampled#
- class monai.transforms.SpatialResampled(*args, **kwargs)[source]#
基于字典的
monai.transforms.SpatialResample包装器。此变换假定
data字典包含输入数据元数据的键,并且包含 SpatialResample 所需的src_affine和dst_affine。该键由key_{meta_key_postfix}形成。变换将交换字典中的src_affine和dst_affine仿射矩阵(可能带有数据类型更改),以便src_affine始终指代当前仿射矩阵的状态。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, dst_keys='dst_affine', allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。align_corners – 几何上,我们将输入的像素视为正方形而不是点。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-sample 也可以是布尔值序列,每个元素对应
keys中的一个键。dtype – 重采样计算的数据类型。为了获得最佳精度,默认为
float64。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。也可以是 dtype 序列,每个元素对应keys中的一个键。dst_keys – 元数据字典中对应
dst_affine的键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 指示此变换是否应延迟执行的标志。默认为 False。
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
ResampleToMatchd#
- class monai.transforms.ResampleToMatchd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ResampleToMatch包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, key_dst, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
key_dst – 要重采样以匹配的图像的键。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。align_corners – 几何上,我们将输入的像素视为正方形而不是点。另请参阅:https://pytorch.ac.cn/docs/stable/nn.functional.html#grid-sample 也可以是布尔值序列,每个元素对应
keys中的一个键。dtype – 重采样计算的数据类型。为了获得最佳精度,默认为
float64。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。也可以是 dtype 序列,每个元素对应keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Spacingd#
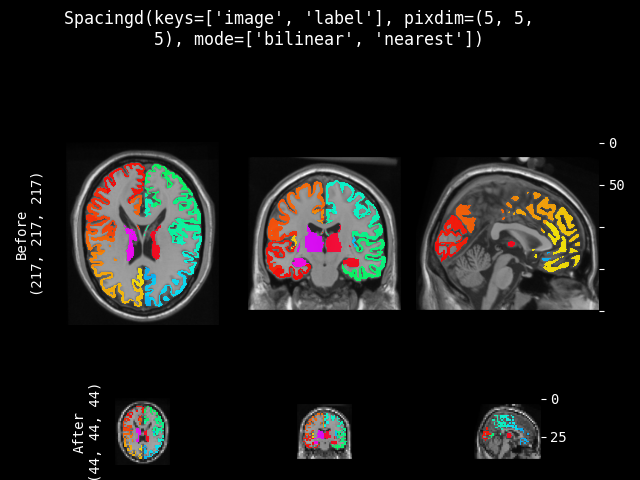
- class monai.transforms.Spacingd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Spacing包装器。此变换假定
data字典包含输入数据元数据的键,并且包含 affine 字段。该键由key_{meta_key_postfix}形成。重采样输入数组后,此变换会将新的仿射矩阵写入元数据中由
key_{meta_key_postfix}形成的 affine 字段。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, pixdim, diagonal=False, mode=bilinear, padding_mode=border, align_corners=False, dtype=<class 'numpy.float64'>, scale_extent=False, recompute_affine=False, min_pixdim=None, max_pixdim=None, ensure_same_shape=True, allow_missing_keys=False, lazy=False)[source]#
- 参数:
pixdim – 输出体素间距。如果提供单个数字,将用于第一个维度。pixdim 序列中的项映射到输入图像的空间维度,如果 pixdim 序列长度长于图像空间维度,将忽略较长部分;如果较短,将用
1.0填充。如果 pixdim 的分量为非正值,变换将使用原始 pixdim 的相应分量,该分量根据输入图像的 affine 矩阵计算得出。diagonal –
是否将输入重采样为具有对角仿射矩阵。如果为 True,输入数据将重采样为以下仿射矩阵
np.diag((pixdim_0, pixdim_1, pixdim_2, 1))
这实际上将体积重置为世界坐标系(在 nibabel 中为 RAS+)。原始方向、旋转、剪切均不保留。
如果为 False,则原始仿射矩阵中的轴方向、正交旋转和平移分量将保留在目标仿射矩阵中。此选项不会相对于原始轴进行翻转/交换。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。align_corners – 几何上,我们将输入的像素视为正方形而不是点。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 也可以是布尔值序列,每个元素对应
keys中的一个键。dtype – 重采样计算的数据类型。为了获得最佳精度,默认为
float64。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。也可以是 dtype 序列,每个元素对应keys中的一个键。scale_extent – 缩放是基于间距还是基于体素的完整范围计算,默认为 False。如果在调用此变换时指定了输出空间大小,则忽略此选项。另请参阅:
monai.data.utils.compute_shape_offset()。当此值为 True 时,align_corners 应为 True,因为 compute_shape_offset 已提供角点对齐的移位/缩放。recompute_affine – 是否根据输出形状重新计算仿射矩阵。解析计算的仿射矩阵不反映输出形状方面的潜在量化误差。将此标志设置为 True 以根据实际 pixdim 重新计算输出仿射矩阵。默认为
False。min_pixdim – 要重采样的最小输入间距。如果提供此值,间距大于此值的输入图像将保留其原始间距(不重采样到 pixdim)。将其设置为 None 以使用 pixdim 的值。默认为 None。
max_pixdim – 要重采样的最大输入间距。如果提供此值,间距小于此值的输入图像将保留其原始间距(不重采样到 pixdim)。将其设置为 None 以使用 pixdim 的值。默认为 None。
ensure_same_shape – 当输入具有相同的空间形状且 pixdim 几乎相同时,是否确保输出空间形状完全相同。默认为 True。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Orientationd#
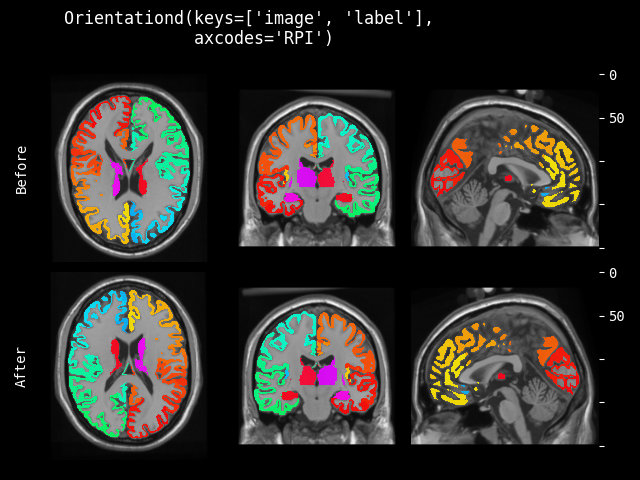
- class monai.transforms.Orientationd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Orientation包装器。此变换假定输入格式为 channel-first。如果使用此变换来标准化图像的方向,则应在任何非各向同性空间变换之前使用它。
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, axcodes=None, as_closest_canonical=False, labels=(('L', 'R'), ('P', 'A'), ('I', 'S')), allow_missing_keys=False, lazy=False)[source]#
- 参数:
axcodes – 空间 ND 输入方向的 N 个元素序列。例如,axcodes='RAS' 表示 3D 方向:(左,右),(后,前),(下,上)。默认方向标签选项为:第一维的 'L' 和 'R',第二维的 'P' 和 'A',第三维的 'I' 和 'S'。
as_closest_canonical – 如果为 True,则以最接近规范轴格式的方式加载图像。
labels – 可选,None 或 (2,) 序列的序列。(2,) 序列是输出轴的(开始,结束)标签。默认为
(('L', 'R'), ('P', 'A'), ('I', 'S'))。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
另请参阅
nibabel.orientations.ornt2axcodes.
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Flipd#
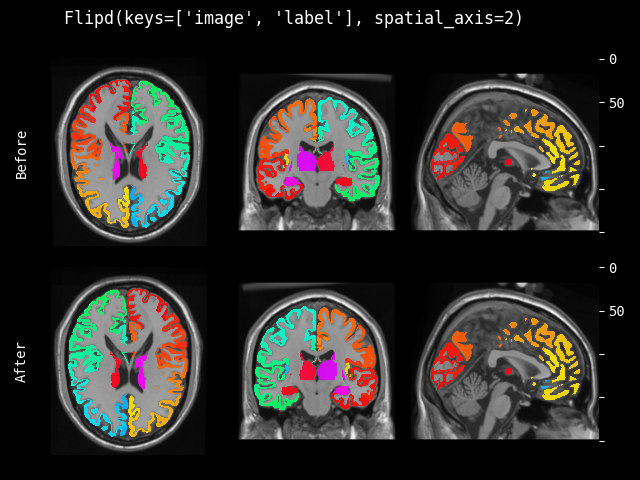
- class monai.transforms.Flipd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Flip包装器。更多详细信息请参阅 numpy.flip。 https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
spatial_axis – 要沿着其翻转的空间轴。默认为 None。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandFlipd#
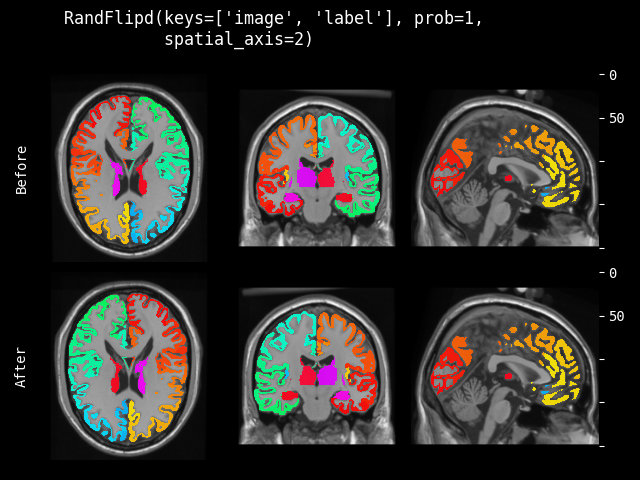
- class monai.transforms.RandFlipd(*args, **kwargs)[source]#
monai.transforms.RandFlip的基于字典的版本。更多详细信息请参阅 numpy.flip。 https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
prob – 翻转的概率。
spatial_axis – 要沿着其翻转的空间轴。默认为 None。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandAxisFlipd#
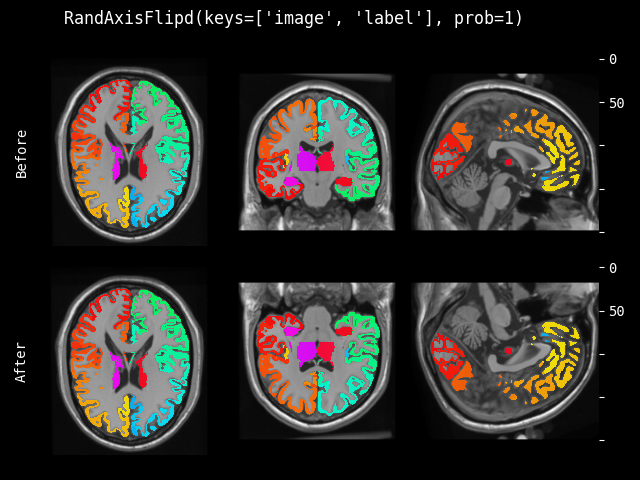
- class monai.transforms.RandAxisFlipd(keys, prob=0.1, allow_missing_keys=False, lazy=False)[source]#
monai.transforms.RandAxisFlip的基于字典的版本。更多详细信息请参阅 numpy.flip。 https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.flip.html
此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 用于选取数据进行转换的键。prob (
float) – 翻转的概率。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Rotated#
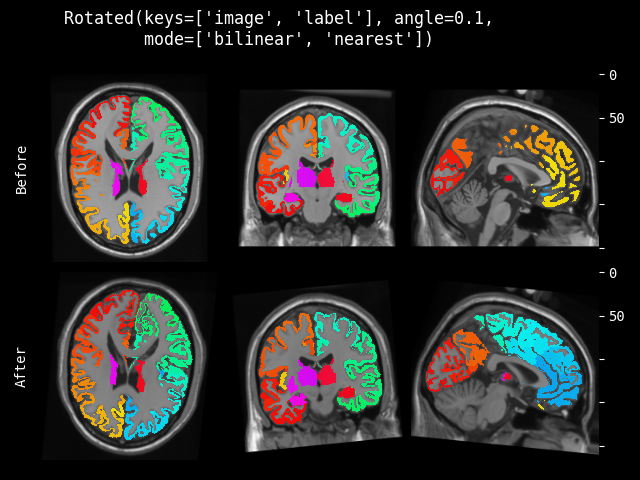
- class monai.transforms.Rotated(*args, **kwargs)[source]#
基于字典的
monai.transforms.Rotate包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
angle – 旋转角度(弧度)。
keep_size – 如果为 False,则调整输出形状以使输入数组完全包含在输出中。如果为 True,则输出形状与输入相同。默认为 True。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为"bilinear"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"border"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。align_corners – 默认为 False。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 它也可以是一个布尔值序列,每个元素对应于
keys中的一个键。dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。它也可以是一个 dtype 或 None 的序列,每个元素对应于keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandRotated#
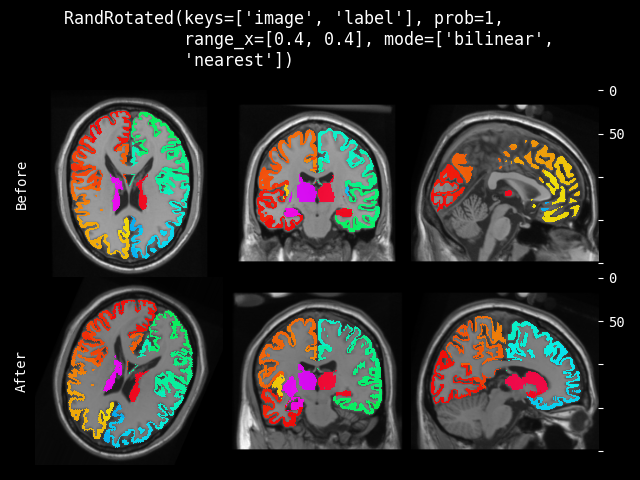
- class monai.transforms.RandRotated(*args, **kwargs)[source]#
monai.transforms.RandRotate的基于字典的版本,随机旋转输入数组。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
range_x – 在由第一轴和第二轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_x, range_x) 中均匀采样。
range_y – 在由第一轴和第三轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_y, range_y) 中均匀采样。仅适用于 3D 数据。
range_z – 在由第二轴和第三轴定义的平面中,旋转角度的范围(以弧度为单位)。如果为单个数字,角度将从 (-range_z, range_z) 中均匀采样。仅适用于 3D 数据。
prob – 旋转的概率。
keep_size – 如果为 False,则调整输出形状以使输入数组完全包含在输出中。如果为 True,则输出形状与输入相同。默认为 True。
mode – {
"bilinear","nearest"} 用于计算输出值的插值模式。默认为"bilinear"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"border"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。align_corners – 默认为 False。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个布尔值序列,每个元素对应于
keys中的一个键。dtype – 重采样计算的数据类型。为了获得最佳精度,默认为
float64。如果为 None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为float32。它也可以是一个 dtype 或 None 的序列,每个元素对应于keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Zoomd#
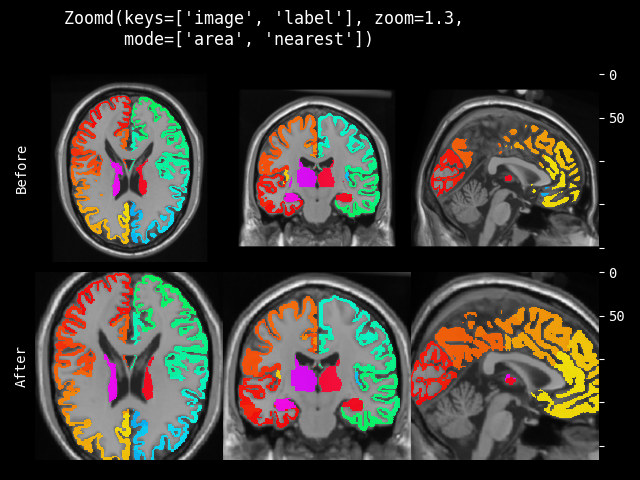
- class monai.transforms.Zoomd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Zoom包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
zoom – 沿空间轴的缩放因子。如果是浮点数,则每个空间轴的缩放因子相同。如果是序列,则 zoom 应包含每个空间轴的一个值。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。padding_mode – 可用于 numpy 数组的模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} 可用于 PyTorch Tensor 的模式:{"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为"edge"。缩放后填充数据所用的模式。另请参阅: https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅在 mode 为 'linear', 'bilinear', 'bicubic' 或 'trilinear' 时生效。默认值: None。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个布尔值或 None 的序列,每个元素对应于
keys中的一个键。dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。keep_size – 是否保持原始大小(如果需要则填充),默认为 True。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandZoomd#
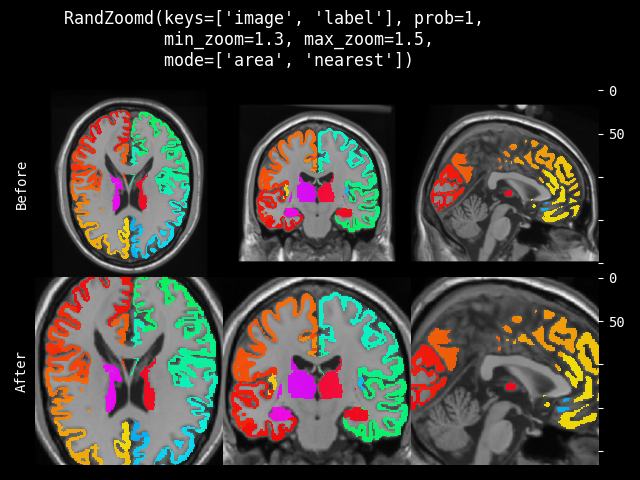
- class monai.transforms.RandZoomd(*args, **kwargs)[source]#
monai.transforms.RandZoom的基于字典的版本。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 用于选取数据进行转换的键。
prob – 缩放的概率。
min_zoom – 最小缩放因子。可以是浮点数或与图像大小相同的序列。如果为浮点数,则从 [min_zoom, max_zoom] 中选择一个随机因子,然后应用于所有空间维度以保持原始空间形状比例。如果为序列,min_zoom 应包含每个空间轴的一个值。如果为 3D 数据提供了 2 个值,则将第一个值用于 H 和 W 维度以保持相同的缩放比例。
max_zoom – 最大缩放因子。可以是浮点数或与图像大小相同的序列。如果为浮点数,则从 [min_zoom, max_zoom] 中选择一个随机因子,然后应用于所有空间维度以保持原始空间形状比例。如果为序列,max_zoom 应包含每个空间轴的一个值。如果为 3D 数据提供了 2 个值,则将第一个值用于 H 和 W 维度以保持相同的缩放比例。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。padding_mode – 可用于 numpy 数组的模式:{
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"} 可用于 PyTorch Tensor 的模式:{"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为"edge"。缩放后填充数据所用的模式。另请参阅: https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.htmlalign_corners – 仅在 mode 为 'linear', 'bilinear', 'bicubic' 或 'trilinear' 时生效。默认值: None。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个布尔值或 None 的序列,每个元素对应于
keys中的一个键。dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。keep_size – 是否保持原始大小(如果需要则填充),默认为 True。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
kwargs – np.pad API 的其他参数,请注意 np.pad 将通道维度视为第一个维度。更多详情请参阅: https://numpy.com.cn/doc/1.18/reference/generated/numpy.pad.html
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
GridPatchd#
- class monai.transforms.GridPatchd(*args, **kwargs)[source]#
以行主序滑动窗口的方式提取扫描整个图像的所有分块,可能存在重叠。它可以对分块进行排序并返回全部或部分分块。
- 参数:
keys – 需要变换的相应项目的键。
patch_size – 用于生成切片的分块大小,0 或 None 选择整个维度
offset – 数组中的起始位置,每个维度默认为 0。np.random.randint(0, patch_size, 2) 为 2D 图像创建介于 0 和 patch_size 之间的随机起始位置。
num_patches – 要返回的分块数量(或最大分块数量)。如果请求的分块数量大于可用分块数量,除非设置了 threshold,否则将应用填充以精确提供 num_patches 个分块。当设置了 threshold 时,此值被视为最大分块数量。默认为 None,表示不限制分块数量。
overlap – 每个维度中块之间的重叠量。默认为 0.0。
sort_fn – 当提供了 num_patches 时,它决定是保留具有最高值的分块 (“max”)、最低值的 (“min”),还是按默认顺序 (None)。默认为 None。
threshold – 一个值,只保留强度总和小于该阈值的分块。默认为不进行过滤。
pad_mode – 根据 patch_size 填充输入图像以包含跨越边界的分块的模式。可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"}(PyTorch){"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为 None,表示不应用填充。另请参阅: https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 需要 pytorch >= 1.10 以获得最佳兼容性。allow_missing_keys – 如果键丢失,则不引发异常。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回值:
- 字典,包含所有原始键/值对,其中 keys 对应的值
被块替换,这是一个包含以下元数据的 MetaTensor
PatchKeys.LOCATION:分块在图像中的起始位置,
PatchKeys.COUNT:图像中的分块总数,
“spatial_shape”:提取的分块的空间大小,以及
“offset”:图像中分块的偏移量(第一个分块的起始位置)
RandGridPatchd#
- class monai.transforms.RandGridPatchd(*args, **kwargs)[source]#
以行主序滑动窗口的方式提取扫描整个图像的所有分块,可能存在重叠,并对图像的最小角(2D 为 (0,0),3D 为 (0,0,0))应用随机偏移。它可以对分块进行排序并返回全部或部分分块。
- 参数:
keys – 需要变换的相应项目的键。
patch_size – 用于生成切片的分块大小,0 或 None 选择整个维度
min_offset – 随机选择的起始位置的最小范围。默认为 0。
max_offset – 随机选择的起始位置的最大范围。默认为图像大小对块大小取模。
num_patches – 要返回的分块数量(或最大分块数量)。如果请求的分块数量大于可用分块数量,除非设置了 threshold,否则将应用填充以精确提供 num_patches 个分块。当设置了 threshold 时,此值被视为最大分块数量。默认为 None,表示不限制分块数量。
overlap – 每个维度中相邻分块的重叠量(0.0 到 1.0 之间的值)。如果只给出一个浮点数,它将应用于所有维度。默认为 0.0。
sort_fn – 当提供了 num_patches 时,它决定是保留具有最高值的分块 (“max”)、最低值的 (“min”)、随机的 (“random”),还是按默认顺序 (None)。默认为 None。
threshold – 一个值,只保留强度总和小于该阈值的分块。默认为不进行过滤。
pad_mode – 根据 patch_size 填充输入图像以包含跨越边界的分块的模式。可用模式:(Numpy){
"constant","edge","linear_ramp","maximum","mean","median","minimum","reflect","symmetric","wrap","empty"}(PyTorch){"constant","reflect","replicate","circular"}。列表中的字符串值之一或用户提供的函数。默认为 None,表示不应用填充。另请参阅: https://numpy.com.cn/doc/stable/reference/generated/numpy.pad.html https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.pad.html 需要 pytorch >= 1.10 以获得最佳兼容性。allow_missing_keys – 如果键丢失,则不引发异常。
pad_kwargs – np.pad 或 torch.pad 函数的其他参数。请注意,np.pad 将通道维度视为第一个维度。
- 返回值:
- 字典,包含所有原始键/值对,其中 keys 对应的值
被块替换,这是一个包含以下元数据的 MetaTensor
PatchKeys.LOCATION:分块在图像中的起始位置,
PatchKeys.COUNT:图像中的分块总数,
“spatial_shape”:提取的分块的空间大小,以及
“offset”:图像中分块的偏移量(第一个分块的起始位置)
GridSplitd#
- class monai.transforms.GridSplitd(*args, **kwargs)[source]#
根据提供的网格将图像分割成 2D 分块。
- 参数:
keys – 需要变换的相应项目的键。
grid – 定义用于分割图像的网格形状的元组。默认为 (2, 2)
size – 一个元组或整数,定义输出块大小,或一个字典,为每个键单独定义,例如 {"image": 3, "mask", (2, 2)}。如果是一个整数,该值将重复应用于每个维度。默认值为 None,此时块大小将从网格形状推断。
allow_missing_keys – 如果键丢失,则不引发异常。
注意:此变换目前仅支持具有两个空间维度的图像。
RandRotate90d#
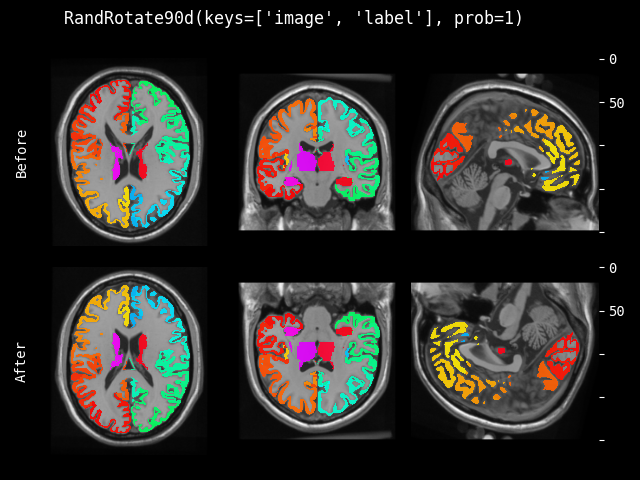
- class monai.transforms.RandRotate90d(keys, prob=0.1, max_k=3, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
monai.transforms.RandRotate90的基于字典的版本。以 prob 的概率,输入数组在由 spatial_axes 指定的平面上旋转 90 度。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, prob=0.1, max_k=3, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformprob (
float) – 旋转的概率。(默认 0.1,有 10% 的概率返回旋转后的数组。)max_k (
int) – 旋转次数将从 np.random.randint(max_k) + 1 中采样。(默认 3)spatial_axes (
tuple[int,int]) – 两个整数,定义了使用两个空间轴进行旋转的平面。默认值:(0, 1),这是空间维度中的前两个轴。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 一个标志,指示此变换是否应延迟执行。默认为 False
Rotate90d#
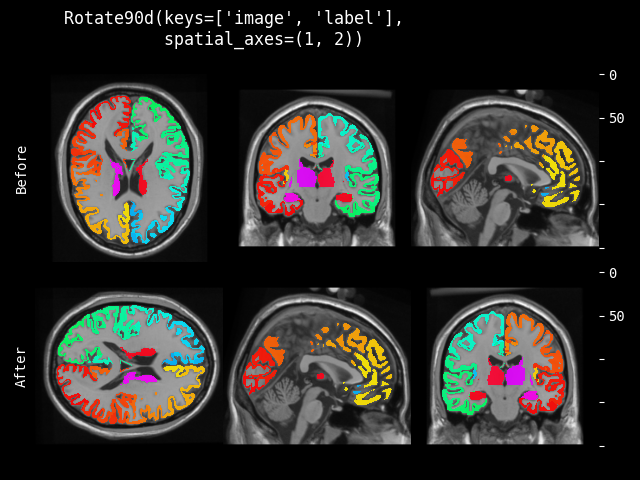
- class monai.transforms.Rotate90d(keys, k=1, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
基于字典的
monai.transforms.Rotate90包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, k=1, spatial_axes=(0, 1), allow_missing_keys=False, lazy=False)[source]#
- 参数:
k (
int) – 旋转 90 度的次数。spatial_axes (
tuple[int,int]) – 两个整数,定义了使用两个空间轴进行旋转的平面。默认值:(0, 1),这是空间维度中的前两个轴。allow_missing_keys (
bool) – 如果键缺失,不引发异常。lazy (
bool) – 一个标志,指示此变换是否应延迟执行。默认为 False
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Resized#
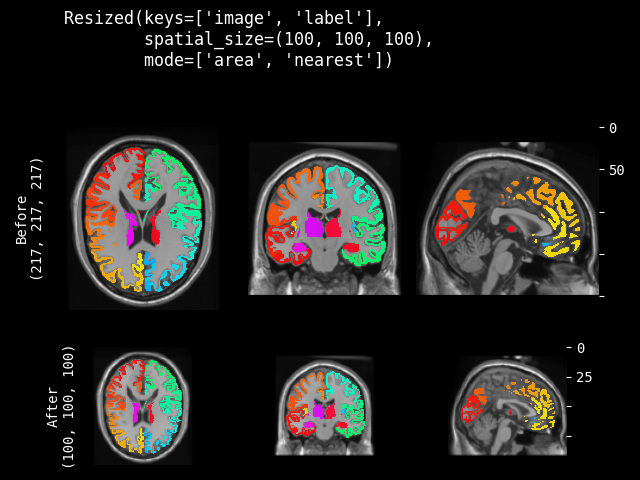
- class monai.transforms.Resized(*args, **kwargs)[source]#
基于字典的
monai.transforms.Resize包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformspatial_size – 改变大小操作后空间维度的预期形状。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将被调整为 (32, 64)。
size_mode – 应为“all”或“longest”,如果是“all”,将对所有空间维度使用 spatial_size,如果是“longest”,则缩放图像,使最长边等于指定的 spatial_size(在这种情况下必须是整数),同时保持原始图像的纵横比,请参阅: https://albumentations.ai/docs/api_reference/augmentations/geometric/resize/ #albumentations.augmentations.geometric.resize.LongestMaxSize。
mode – {
"nearest","nearest-exact","linear","bilinear","bicubic","trilinear","area"} 插值模式。默认为"area"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个字符串序列,每个元素对应于keys中的一个键。align_corners – 仅在 mode 为 'linear', 'bilinear', 'bicubic' 或 'trilinear' 时生效。默认值: None。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html 它也可以是一个布尔值或 None 的序列,每个元素对应于
keys中的一个键。anti_aliasing – 布尔值,指示是否在下采样之前应用高斯滤波器平滑图像。在对图像进行下采样时进行滤波以避免混叠伪影至关重要。另请参阅
skimage.transform.resizeanti_aliasing_sigma – {float, 浮点数元组},可选,用于抗锯齿时使用的高斯滤波器的标准差。默认情况下,此值选择为 (s - 1) / 2,其中 s 是下采样因子,且 s > 1。对于放大情况 (s < 1),在重新缩放之前不执行抗锯齿。
dtype – 重采样计算的数据类型。默认为
float32。如果为 None,则使用输入数据的数据类型。allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Affined#
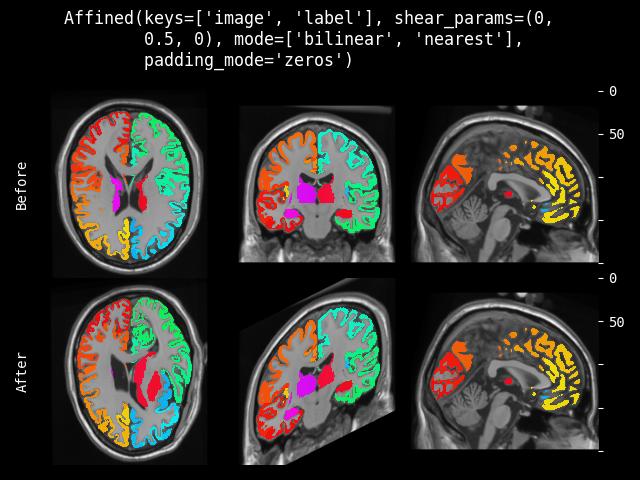
- class monai.transforms.Affined(*args, **kwargs)[source]#
基于字典的
monai.transforms.Affine包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, rotate_params=None, shear_params=None, translate_params=None, scale_params=None, affine=None, spatial_size=None, mode=bilinear, padding_mode=reflection, device=None, dtype=<class 'numpy.float32'>, align_corners=False, allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
rotate_params – 旋转角度(以弧度为单位),2D 图像为标量,3D 图像为 3 个浮点数的元组。默认为不旋转。
shear_params –
仿射矩阵的剪切因子,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ] a tuple of 2 floats for 2D, a tuple of 6 floats for 3D. Defaults to no shearing.
translate_params – 2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。平移是以像素/体素为单位,相对于输入图像的中心。默认为不平移。
scale_params – 每个空间维度的缩放因子。2D 为 2 个浮点数的元组,3D 为 3 个浮点数的元组。默认为 1.0。
affine – 如果应用,忽略参数(rotate_params 等)并使用提供的矩阵。矩阵应为方阵,每边长度 = 图像空间维度数 + 1。
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,变换将使用图像大小的相应分量。例如,如果图像的第二个空间维度大小为 64,spatial_size=(32, -1) 将被调整为 (32, 64)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"reflection"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅: https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 它也可以是一个序列,每个元素对应于keys中的一个键。device – 张量将分配到的设备。
dtype – 用于重采样计算的数据类型。默认为
float32。如果为None,则使用输入数据的数据类型。为了与其他模块兼容,输出数据类型始终为 float32。align_corners – 默认为 False。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
另请参阅
monai.transforms.compose.MapTransform关于随机仿射参数配置,请参阅
RandAffineGrid。
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
RandAffined#
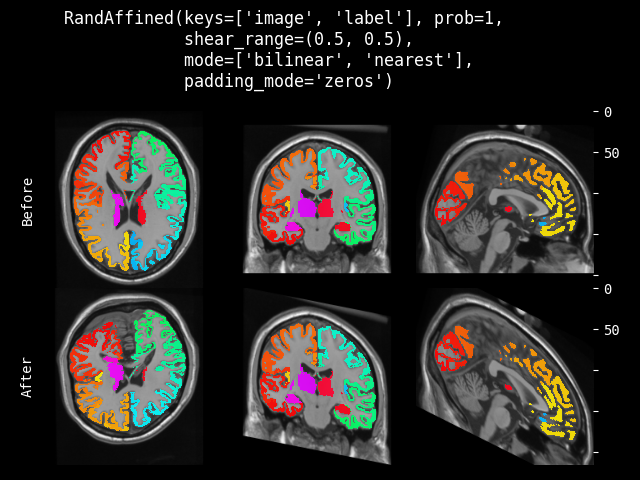
- class monai.transforms.RandAffined(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandAffine包装器。此变换支持延迟执行。有关详细信息,请参阅延迟重采样主题。
- __call__(data, lazy=None)[source]#
- 参数:
data – 包含要处理的类张量数据的字典。此字典中指定的
keys必须是 channel first 且最多具有三个空间维度的类张量数组lazy – 一个标志,指示此变换在此调用期间是否应延迟执行。将其设置为 False 或 True 会覆盖初始化期间为此调用设置的
lazy标志。默认为 None。
- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, cache_grid=False, device=None, allow_missing_keys=False, lazy=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
spatial_size – 输出图像空间大小。如果未定义 spatial_size 和 self.spatial_size,或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,变换将使用图像大小的相应分量。例如,如果图像的第二个空间维度大小为 64,spatial_size=(32, -1) 将被调整为 (32, 64)。
prob – 返回随机仿射网格的概率。默认为 0.1,即有 10% 的机会返回随机网格。
rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(2D 为包含 2 个浮点数的元组,3D 为包含 6 个浮点数的元组)的范围,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移像素/体素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"reflection"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅: https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 它也可以是一个序列,每个元素对应于keys中的一个键。cache_grid – 是否缓存恒等采样网格。如果空间大小不由输入图像动态定义,启用此选项可以加速变换。
device – 张量将分配到的设备。
allow_missing_keys – 如果键丢失,则不引发异常。
lazy – 一个标志,指示此变换是否应延迟执行。默认为 False
另请参阅
monai.transforms.compose.MapTransform关于随机仿射参数配置,请参阅
RandAffineGrid。
- inverse(data)[source]#
__call__的逆操作。- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- property lazy#
获取是否为此转换实例启用了延迟计算。:returns: 如果转换以延迟方式运行,则为 True,否则为 False。
Rand2DElasticd#
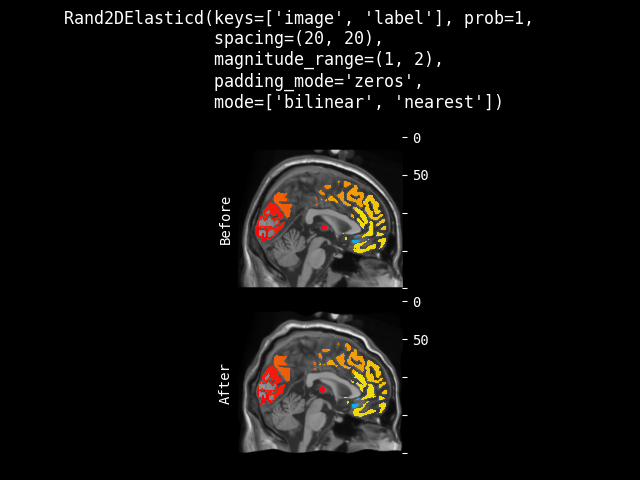
- class monai.transforms.Rand2DElasticd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Rand2DElastic包装器。- __call__(data)[source]#
- 参数:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – 一个字典,包含待处理的类似张量的数据。此字典中指定的keys必须是通道优先且最多具有三个空间维度的类似张量数组- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, spacing, magnitude_range, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, device=None, allow_missing_keys=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
spacing – 控制点之间的距离。
magnitude_range – 2 个整数,随机偏移将从
uniform[magnitude[0], magnitude[1])生成。spatial_size – 指定输出图像空间大小 [h, w]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第二个空间维度大小为 64,则 spatial_size=(32, -1) 将调整为 (32, 64)。
prob – 返回随机仿射网格的概率。默认为 0.1,有 10% 的几率返回随机网格,否则返回从输入图像中提取的以
spatial_size为中心的区域。rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(2D 为包含 2 个浮点数的元组)的范围,以 2D 仿射为例
[ [1.0, params[0], 0.0], [params[1], 1.0, 0.0], [0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移像素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"reflection"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅: https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 它也可以是一个序列,每个元素对应于keys中的一个键。device – 张量将分配到的设备。
allow_missing_keys – 如果键丢失,则不引发异常。
另请参阅
关于随机仿射参数配置,请参阅
RandAffineGrid。关于仿射变换参数配置,请参阅
Affine。
Rand3DElasticd#
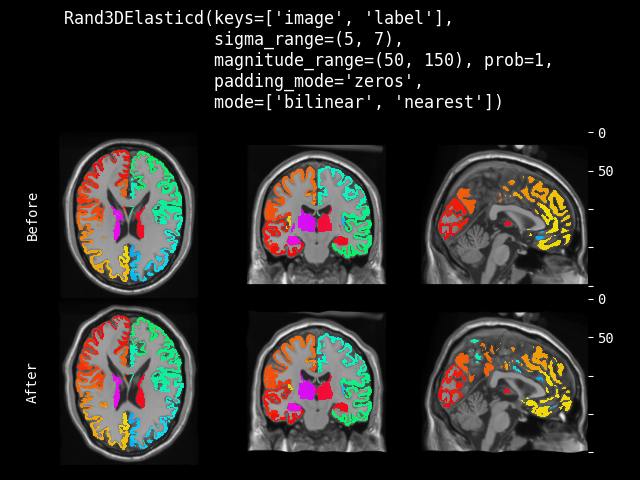
- class monai.transforms.Rand3DElasticd(*args, **kwargs)[source]#
基于字典的
monai.transforms.Rand3DElastic包装器。- __call__(data)[source]#
- 参数:
data (
Mapping[Hashable,Tensor]) – 一个字典,包含待处理的类似张量的数据。此字典中指定的keys必须是通道优先且最多具有三个空间维度的类似张量数组- 返回类型:
dict[Hashable,Tensor]- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, sigma_range, magnitude_range, spatial_size=None, prob=0.1, rotate_range=None, shear_range=None, translate_range=None, scale_range=None, mode=bilinear, padding_mode=reflection, device=None, allow_missing_keys=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
sigma_range – 将使用从
uniform[sigma_range[0], sigma_range[1])中采样的标准差的高斯核来平滑随机偏移网格。magnitude_range – 网格上的随机偏移将从
uniform[magnitude[0], magnitude[1])中生成。spatial_size – 指定空间 3D 输出图像空间大小 [h, w, d]。如果 spatial_size 和 self.spatial_size 未定义或小于 1,则变换将使用 img 的空间大小。如果 spatial_size 的某些分量是非正值,则变换将使用 img 大小的相应分量。例如,如果 img 的第三个空间维度大小为 64,则 spatial_size=(32, 32, -1) 将调整为 (32, 32, 64)。
prob – 返回随机仿射网格的概率。默认为 0.1,有 10% 的几率返回随机网格,否则返回从输入图像中提取的以
spatial_size为中心的区域。rotate_range – 角度范围,单位为弧度。如果元素 i 是一对 (min, max) 值,则使用 uniform[-rotate_range[i][0], rotate_range[i][1]) 为第 i 个空间维度生成旋转参数。如果不是,则使用 uniform[-rotate_range[i], rotate_range[i])。这可以按每个维度进行更改。例如,((0,3), 1, …):对于 dim0,旋转范围为 [0, 3],对于 dim1,将使用 [-1, 1]。设置单个值将使用 [-x, x] 用于 dim0,其余维度不进行旋转。
shear_range –
与 rotate_range 格式匹配的剪切范围,它定义了用于仿射矩阵随机选择剪切因子(3D 为包含 6 个浮点数的元组)的范围,以 3D 仿射为例
[ [1.0, params[0], params[1], 0.0], [params[2], 1.0, params[3], 0.0], [params[4], params[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
translate_range – 与 rotate_range 格式匹配的平移范围,它定义了为每个空间维度随机选择平移体素的范围。
scale_range – 与 rotate_range 格式匹配的缩放范围。它定义了为每个空间维度随机选择缩放因子进行平移的范围。结果中会加上 1.0。这使得 0 对应于无变化(即缩放因子为 1.0)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外围值的填充模式。默认为"reflection"。另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅: https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 它也可以是一个序列,每个元素对应于keys中的一个键。device – 张量将分配到的设备。
allow_missing_keys – 如果键丢失,则不引发异常。
另请参阅
关于随机仿射参数配置,请参阅
RandAffineGrid。关于仿射变换参数配置,请参阅
Affine。
GridDistortiond#
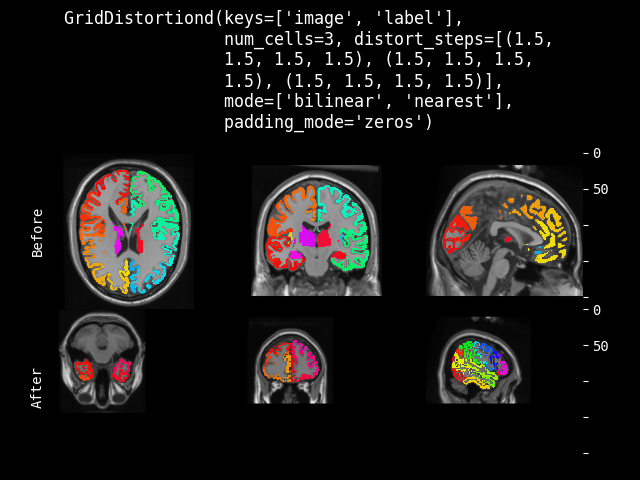
- class monai.transforms.GridDistortiond(*args, **kwargs)[source]#
基于字典的
monai.transforms.GridDistortion包装器。- __call__(data)[source]#
- 参数:
data (
Mapping[Hashable,Tensor]) – 一个字典,包含待处理的类似张量的数据。此字典中指定的keys必须是通道优先且最多具有三个空间维度的类似张量数组- 返回类型:
dict[Hashable,Tensor]- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, num_cells, distort_steps, mode=bilinear, padding_mode=border, device=None, allow_missing_keys=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
num_cells – 每个维度的网格单元数。
distort_steps – 此参数是一个元组列表,其中每个元组包含相应维度(按 H, W[, D] 的顺序)的形变步长。每个元组的长度等于 num_cells + 1。元组中的每个值表示相关单元格的形变步长。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。device – 张量将分配到的设备。
allow_missing_keys – 如果键丢失,则不引发异常。
RandGridDistortiond#
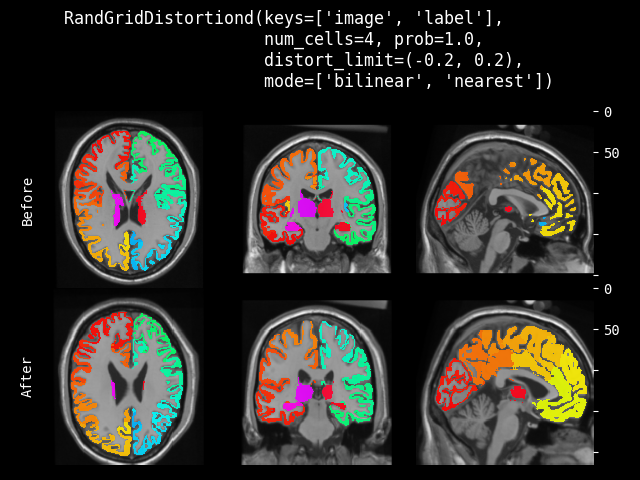
- class monai.transforms.RandGridDistortiond(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandGridDistortion包装器。- __call__(data)[source]#
- 参数:
data (
Mapping[Hashable,Tensor]) – 一个字典,包含待处理的类似张量的数据。此字典中指定的keys必须是通道优先且最多具有三个空间维度的类似张量数组- 返回类型:
dict[Hashable,Tensor]- 返回值:
包含变换后数据以及字典中存在的任何其他数据的字典
- __init__(keys, num_cells=5, prob=0.1, distort_limit=(-0.03, 0.03), mode=bilinear, padding_mode=border, device=None, allow_missing_keys=False)[source]#
- 参数:
keys – 需要变换的相应项目的键。
num_cells – 每个维度的网格单元数。
prob – 返回随机网格形变变换的概率。默认为 0.1。
distort_limit – 随机形变的范围。如果是一个数字,则形变限制从 (-distort_limit, distort_limit) 中选择。默认为 (-0.03, 0.03)。
mode – {
"bilinear","nearest"} 或样条插值阶数 0-5(整数)。用于计算输出值的插值模式。默认为"bilinear"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当它是整数时,将使用 numpy (cpu tensor)/cupy (cuda tensor) 后端,该值表示样条插值的阶数。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。padding_mode – {
"zeros","border","reflection"} 网格外部值的填充模式。默认为"border"。另请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.grid_sample.html 当 mode 是整数时,使用 numpy/cupy 后端,此参数接受 {‘reflect’, ‘grid-mirror’, ‘constant’, ‘grid-constant’, ‘nearest’, ‘mirror’, ‘grid-wrap’, ‘wrap’}。另请参阅:https://docs.scipy.org.cn/doc/scipy/reference/generated/scipy.ndimage.map_coordinates.html 也可以是序列,每个元素对应keys中的一个键。device – 张量将分配到的设备。
allow_missing_keys – 如果键丢失,则不引发异常。
RandSimulateLowResolutiond#
- class monai.transforms.RandSimulateLowResolutiond(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandSimulateLowResolution包装器。低分辨率的随机模拟,对应于 nnU-Net 的 SimulateLowResolutionTransform (MIC-DKFZ/batchgenerators)。首先,根据从 zoom_range 中均匀采样的 zoom_factor 确定的较低分辨率对数组/张量进行重采样。然后,在原始分辨率下对数组/张量进行重采样。- __call__(data)[source]#
- 参数:
data (
Mapping[Hashable,Union[ndarray,Tensor]]) – 包含要转换的张量状数据的字典。此字典中指定的keys必须是通道优先且最多具有三个空间维度的张量状数组- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, prob=0.1, downsample_mode=nearest, upsample_mode=trilinear, zoom_range=(0.5, 1.0), align_corners=False, allow_missing_keys=False, device=None)[source]#
- 参数:
keys – 需要变换的相应项目的键。
prob – 执行此增强的概率
downsample_mode – 下采样操作的插值模式
upsample_mode – 上采样操作的插值模式
zoom_range – 用于下采样和上采样操作的随机缩放因子的范围,
张量。 (从中采样。它决定了下采样张量的形状)
align_corners – 仅当 downsample_mode 或 upsample_mode 为 'linear'、'bilinear'、'bicubic' 或 'trilinear' 时有效。默认值:False 另请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.nn.functional.interpolate.html
allow_missing_keys – 如果键丢失,则不引发异常。
device – 张量将分配到的设备。
另请参阅
monai.transforms.compose.MapTransform
ConvertBoxToPointsd#
- class monai.transforms.ConvertBoxToPointsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ConvertBoxToPoints包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
ConvertPointsToBoxesd#
- class monai.transforms.ConvertPointsToBoxesd(keys, box_key='box', allow_missing_keys=False)[source]#
基于字典的
monai.transforms.ConvertPointsToBoxes包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
平滑场 (Dict)#
RandSmoothFieldAdjustContrastd#
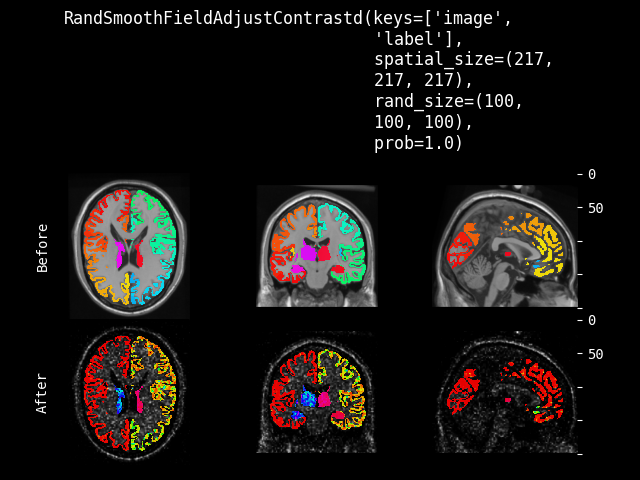
- class monai.transforms.RandSmoothFieldAdjustContrastd(*args, **kwargs)[source]#
RandSmoothFieldAdjustContrast 的字典版本。
默认情况下,每次调用时随机化场一次,因此相同的场会应用于每个选定的键。指定场插值模式的 mode 参数可以是单个值,也可以是序列值,序列中的每个值对应 keys 中的一个键。
- 参数:
keys – 应用增强的键名
spatial_size – 输入数组的大小,keys 中指定的所有数组必须具有相同的维度
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 0 填充的像素/体素数量
mode – 上采样时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
gamma – 指数场的 (min, max) 范围
device – 用于定义场的 Pytorch 设备
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Mapping[Hashable,Union[ndarray,Tensor]]
RandSmoothFieldAdjustIntensityd#
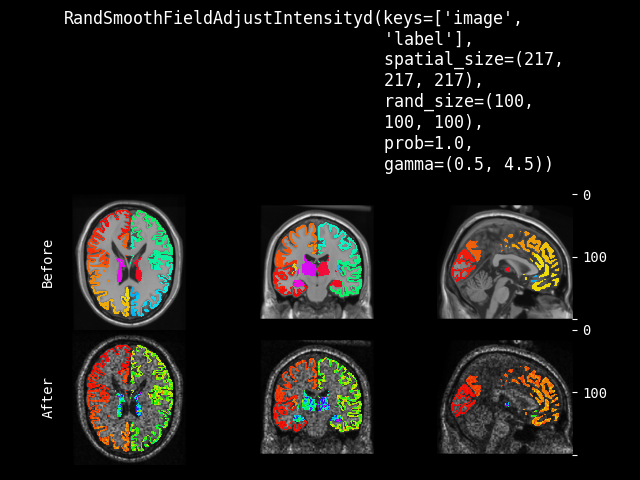
- class monai.transforms.RandSmoothFieldAdjustIntensityd(*args, **kwargs)[source]#
RandSmoothFieldAdjustIntensity 的字典版本。
默认情况下,每次调用时随机化场一次,因此相同的场会应用于每个选定的键。指定场插值模式的 mode 参数可以是单个值,也可以是序列值,序列中的每个值对应 keys 中的一个键。
- 参数:
keys – 应用增强的键名
spatial_size – 输入数组的大小,keys 中指定的所有数组必须具有相同的维度
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 0 填充的像素/体素数量
mode – 上采样时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
gamma – 强度乘数范围 (min, max)
device – 用于定义场的 Pytorch 设备
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Mapping[Hashable,Union[ndarray,Tensor]]
RandSmoothDeformd#

- class monai.transforms.RandSmoothDeformd(*args, **kwargs)[source]#
RandSmoothDeform 的字典版本。
默认情况下,每次调用时随机化场一次,因此相同的场会应用于每个选定的键。指定场插值模式的 field_mode 参数可以是单个值,也可以是序列值,序列中的每个值对应 keys 中的一个键。类似地,grid_mode 参数可以是单个值或每个键一个值。
- 参数:
keys – 应用增强的键名
spatial_size – 用于插值形变网格的输入数组大小
rand_size – 开始生成随机场的尺寸
pad – 沿场边缘用 0 填充的像素/体素数量
field_mode – 上采样形变场时使用的插值模式
align_corners – 如果为 True,则在上采样场时对齐角点
prob – 应用变换的概率
def_range – 图像大小分数表示的形变范围值
grid_dtype – 根据场计算出的形变网格的类型
grid_mode – 使用形变网格对输入进行采样时使用的插值模式
grid_padding_mode – 使用形变网格对输入进行采样时使用的填充模式
grid_align_corners – 如果为 True,则在对形变网格采样时对齐角点
device – 用于定义场的 Pytorch 设备
- __call__(data)[source]#
data是一个元素,通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。此方法应返回data的更新版本。为简化输入验证,大多数转换假定data是 Numpy ndarray、PyTorch Tensor 或字符串,数据形状可以是
无形状的字符串数据,LoadImage 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChannel 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
此方法可以选择接受额外的参数来帮助执行转换操作。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
Mapping[Hashable,Union[ndarray,Tensor]]
MRI 变换 (Dict)#
K空间欠采样 (Dict)#
- class monai.apps.reconstruction.transforms.dictionary.RandomKspaceMaskd(keys, center_fractions, accelerations, spatial_dims=2, is_complex=True, allow_missing_keys=False)[source]#
基于字典的
monai.apps.reconstruction.transforms.array.RandomKspacemask包装器。其他掩码转换可以继承此类,例如:monai.apps.reconstruction.transforms.dictionary.EquispacedKspaceMaskd。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要转换的相应项的键。另请参见: monai.transforms.MapTransformcenter_fractions (
Sequence[float]) – 要保留的低频列的分数。如果提供了多个值,则每次均匀选择其中一个。accelerations (
Sequence[float]) – 欠采样量。这应与 center_fractions 具有相同的长度。如果提供了多个值,则每次均匀选择其中一个。spatial_dims (
int) – 空间维度数量(例如,2D 数据为 2;对于 pseudo-3D 数据集(如 fastMRI 数据集)也为 2)。选择最后一个空间维度进行采样。对于 fastMRI 数据集,k 空间的形状为 (…,num_slices,num_coils,H,W),沿 W 进行采样。对于形状为 (…,num_coils,H,W,D) 的一般 3D 数据,沿 D 进行采样。is_complex (
bool) – 如果为 True,则最后一个维度将保留用于实部/虚部。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- class monai.apps.reconstruction.transforms.dictionary.EquispacedKspaceMaskd(keys, center_fractions, accelerations, spatial_dims=2, is_complex=True, allow_missing_keys=False)[source]#
基于字典的
monai.apps.reconstruction.transforms.array.EquispacedKspaceMask包装器。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要转换的相应项的键。另请参见: monai.transforms.MapTransformcenter_fractions (
Sequence[float]) – 要保留的低频列的分数。如果提供了多个值,则每次均匀选择其中一个。accelerations (
Sequence[float]) – 欠采样量。这应与 center_fractions 具有相同的长度。如果提供了多个值,则每次均匀选择其中一个。spatial_dims (
int) – 空间维度数量(例如,2D 数据为 2;对于 pseudo-3D 数据集(如 fastMRI 数据集)也为 2)。选择最后一个空间维度进行采样。对于 fastMRI 数据集,k 空间的形状为 (…,num_slices,num_coils,H,W),沿 W 进行采样。对于形状为 (…,num_coils,H,W,D) 的一般 3D 数据,沿 D 进行采样。is_complex (
bool) – 如果为 True,则最后一个维度将保留用于实部/虚部。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
ExtractDataKeyFromMetaKeyd#
- class monai.apps.reconstruction.transforms.dictionary.ExtractDataKeyFromMetaKeyd(keys, meta_key, allow_missing_keys=False)[source]#
将键从元数据 (meta) 移动到数据 (data)。当加载配对样本数据集且某些键应从元数据移动到数据时,这非常有用。
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 要从元数据 (meta) 传输到数据 (data) 的键meta_key (
str) – 存储所有元数据的元键allow_missing_keys (
bool) – 如果键缺失,则不引发异常
示例
当加载 fastMRI 数据集时,“kspace”存储在数据字典中,但键为“reconstruction_rss”的地面实况图像存储在元数据中。在这种情况下,ExtractDataKeyFromMetaKeyd 将“reconstruction_rss”移动到数据中。
ReferenceBasedSpatialCropd#
- class monai.apps.reconstruction.transforms.dictionary.ReferenceBasedSpatialCropd(keys, ref_key, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.SpatialCrop包装器。这类似于monai.transforms.SpatialCropd,后者是一个通用的裁剪器,用于生成感兴趣区域 (ROI) 的子卷。它们的区别在于此转换根据参考图像进行裁剪。如果预期 ROI 大小的一个维度大于输入图像大小,则不会裁剪该维度。
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformref_key (
str) – 用于裁剪“keys”中项目的项目的键allow_missing_keys (
bool) – 如果键缺失,不引发异常。
示例
在图像重建任务中,假设 keys=[“image”] 且 ref_key=[“target”]。此外,假设 data 是数据字典。然后,ReferenceBasedSpatialCropd 通过调用
monai.transforms.SpatialCrop,根据 data[“target”] 的空间大小对 data[“image”] 进行中心裁剪。
ReferenceBasedNormalizeIntensityd#
- class monai.apps.reconstruction.transforms.dictionary.ReferenceBasedNormalizeIntensityd(keys, ref_key, subtrahend=None, divisor=None, nonzero=False, channel_wise=False, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.NormalizeIntensity包装器。这类似于monai.transforms.NormalizeIntensityd,可以规范化非零值或整个图像。区别在于此转换根据参考图像进行规范化。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
ref_key – 用于归一化“keys”中项目的项目的键
subtrahend – 要减去的量(通常是均值)
divisor – 要除以的量(通常是标准差)
nonzero – 是否只归一化非零值。
channel_wise – 如果为 True,则对每个通道分别计算,否则直接在整个图像上计算。默认为 False。
dtype – 输出数据类型,如果为 None,则与输入图像相同。默认为 float32。
allow_missing_keys – 如果键丢失,则不引发异常。
示例
在图像重建任务中,假设 keys=[“image”, “target”] 且 ref_key=[“image”]。此外,假设 data 是数据字典。然后,ReferenceBasedNormalizeIntensityd 通过调用
monai.transforms.NormalizeIntensity,根据 data[“image”] 的均值和标准差对 data[“target”] 和 data[“image”] 进行归一化。
惰性 (Dict)#
ApplyPendingd#
实用工具 (Dict)#
Identityd#
- class monai.transforms.Identityd(keys, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.Identity封装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
AsChannelLastd#
- class monai.transforms.AsChannelLastd(keys, channel_dim=0, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.AsChannelLast包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
EnsureChannelFirstd#
- class monai.transforms.EnsureChannelFirstd(keys, strict_check=True, allow_missing_keys=False, channel_dim=None)[source]#
基于字典的
monai.transforms.EnsureChannelFirst封装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, strict_check=True, allow_missing_keys=False, channel_dim=None)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformstrict_check (
bool) – 当元信息不足时是否引发错误。allow_missing_keys (
bool) – 如果键缺失,不引发异常。channel_dim – 此参数可用于指定输入数组的原始通道维度(整数)。它会覆盖提供的 MetaTensor 输入中的 original_channel_dim。如果输入数组没有通道维度,此值应为
'no_channel'。如果将其设置为 None,此类将依赖 img 或 meta_dict 提供通道维度。
RepeatChanneld#
- class monai.transforms.RepeatChanneld(keys, repeats, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.RepeatChannel封装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
SplitDimd#
- class monai.transforms.SplitDimd(*args, **kwargs)[source]#
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, output_postfixes=None, dim=0, keepdim=True, update_meta=True, list_output=False, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformoutput_postfixes – 用于构建存储分割数据的键的后缀。例如:如果输入数据的键是 pred 并分割成 2 个类别,则输出数据的键将是:pred_(output_postfixes[0]), pred_(output_postfixes[1])。如果为 None,则使用索引号:pred_0, pred_1, … pred_N。
dim – 输入图像的哪个维度是通道,默认为 0。
keepdim – 如果为 True,输出在分割维度上将有一个单维度(singleton)。如果为 False,该维度将被挤压(squeezed)。
update_meta – 如果为 True,为每个输出复制 [key]_meta_dict 并更新仿射变换以反映裁剪后的图像。
list_output – 如果为 True,输出将是一个字典列表,其键与原始字典相同。
allow_missing_keys – 如果键丢失,则不引发异常。
CastToTyped#
- class monai.transforms.CastToTyped(*args, **kwargs)[source]#
基于字典的
monai.transforms.CastToType包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ToTensord#
- class monai.transforms.ToTensord(*args, **kwargs)[source]#
基于字典的
monai.transforms.ToTensor包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, dtype=None, device=None, wrap_sequence=True, track_meta=None, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformdtype – 要转换的目标数据内容类型,例如:torch.float 等。
device – 指定放置张量数据的目标设备。
wrap_sequence – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [tensor(1), tensor(2)];如果 True,则 [1, 2] -> tensor([1, 2])。
track_meta – 如果为 True 则转换为
MetaTensor,否则转换为 PyTorchTensor;如果为None,则根据 py:func:monai.data.meta_obj.get_track_meta 的返回值行为。allow_missing_keys – 如果键丢失,则不引发异常。
ToNumpyd#
- class monai.transforms.ToNumpyd(keys, dtype=None, wrap_sequence=True, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.ToNumpy包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Any]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, dtype=None, wrap_sequence=True, allow_missing_keys=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformdtype (
Union[dtype,type,str,None]) – 转换为 numpy 数组时的目标数据类型。wrap_sequence (
bool) – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [array(1), array(2)];如果 True,则 [1, 2] -> array([1, 2])。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
ToPIL#
ToCupyd#
- class monai.transforms.ToCupyd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ToCupy包装器。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformdtype – 数据类型指定符。默认从输入推断。如果不是 None,则必须是 numpy.dtype 的参数,更多详情请参见:https://docs.cupy.com.cn/en/stable/reference/generated/cupy.array.html。
wrap_sequence – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [array(1), array(2)];如果 True,则 [1, 2] -> array([1, 2])。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ToPILd#
- class monai.transforms.ToPILd(keys, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.ToNumpy包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Any]- 返回值:
应用转换后
data的更新字典版本。
DeleteItemsd#
- class monai.transforms.DeleteItemsd(*args, **kwargs)[source]#
从数据字典中删除指定项目以释放内存。它将移除键值对并复制其他项来构建一个新的字典。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
SelectItemsd#
- class monai.transforms.SelectItemsd(keys, allow_missing_keys=False)[source]#
仅从数据字典中选择指定项目以释放内存。它将复制选定的键值对并构建一个新的字典。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
FlattenSubKeysd#
- class monai.transforms.FlattenSubKeysd(*args, **kwargs)[source]#
如果一个项是字典,它通过将子项(由 sub-keys 定义)移动到顶层来展平该项。 {“pred”: {“a”: …, “b”, … }} –> {“a”: …, “b”, … }
- 参数:
keys – 要展平的相应项的键
sub_keys – 要展平的项的子键。如果未提供,则展平所有子键。
delete_keys – 是否删除子键被展平的项的键。默认为 True。
prefix – 移动到顶层时添加到子键的可选前缀。默认情况下不添加前缀。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
Transposed#
- class monai.transforms.Transposed(*args, **kwargs)[source]#
基于字典的
monai.transforms.Transpose包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
SqueezeDimd#
- class monai.transforms.SqueezeDimd(keys, dim=0, update_meta=True, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.SqueezeDim包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, dim=0, update_meta=True, allow_missing_keys=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformdim (
int) – 要压缩的维度。默认值:0(第一个维度)update_meta (
bool) – 如果输入是 metatensor,是否更新元信息。默认值为True。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
DataStatsd#
- class monai.transforms.DataStatsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.DataStats包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, prefix='Data', data_type=True, data_shape=True, value_range=True, data_value=False, meta_info=False, additional_info=None, name='DataStats', allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformprefix – 将以格式:“{prefix} 统计信息” 打印。它也可以是字符串序列,每个元素对应于
keys中的一个键。data_type – 是否显示输入数据的类型。它也可以是布尔序列,每个元素对应于
keys中的一个键。data_shape – 是否显示输入数据的形状。它也可以是布尔序列,每个元素对应于
keys中的一个键。value_range – 是否显示输入数据的值范围。它也可以是布尔序列,每个元素对应于
keys中的一个键。data_value – 是否显示输入数据的原始值。它也可以是布尔序列,每个元素对应于
keys中的一个键。一个典型示例是打印 Nifti 图像的一些属性:仿射变换(affine)、像素间距(pixdim)等。meta_info – 是否显示 MetaTensor 的数据。它也可以是布尔序列,每个元素对应于
keys中的一个键。additional_info – 用户可以定义可调用函数从输入数据中提取附加信息。它也可以是字符串序列,每个元素对应于
keys中的一个键。name – 要使用的 logging.logger 的标识符,默认为“DataStats”。
allow_missing_keys – 如果键丢失,则不引发异常。
SimulateDelayd#
- class monai.transforms.SimulateDelayd(*args, **kwargs)[source]#
基于字典的
monai.transforms.SimulateDelay包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
CopyItemsd#
- class monai.transforms.CopyItemsd(*args, **kwargs)[source]#
从数据字典复制指定的项并以不同的键名保存。它可以一次复制多个项并复制多次。
- __call__(data)[source]#
- 抛出异常:
KeyError – 当
self.names中的键已存在于data中时。- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]
- __init__(keys, times=1, names=None, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformtimes – 预期的复制次数,例如,如果 keys 是 “img”,times 是 3,它将向字典中添加 3 份 “img” 数据,默认为 1。
names – 新复制数据对应的名称,长度应与
len(keys) x times匹配。例如,如果 keys 是 [“img”, “seg”] 且 times 是 2,names 可以是:[“img_1”, “seg_1”, “img_2”, “seg_2”]。如果为 None,对于复制次数 N,使用 “{key}_{index}” 作为键,索引从 0 到 N-1。allow_missing_keys – 如果键丢失,则不引发异常。
- 抛出异常:
ValueError – 当
times为非正数时。ValueError – 当
len(names)不等于len(keys) * times时。值不兼容。
ConcatItemsd#
- class monai.transforms.ConcatItemsd(keys, name, dim=0, allow_missing_keys=False)[source]#
将数据字典中指定的项沿第一维度连接起来以构建一个大数组。期望所有项都是 numpy 数组、PyTorch Tensor 或 MetaTensor。当项是 MetaTensor 时,返回第一个输入的元信息。
Lambdad#
- class monai.transforms.Lambdad(*args, **kwargs)[source]#
基于字典的
monai.transforms.Lambda包装器。例如
input_data={'image': np.zeros((10, 2, 2)), 'label': np.ones((10, 2, 2))} lambd = Lambdad(keys='label', func=lambda x: x[:4, :, :]) print(lambd(input_data)['label'].shape) (4, 2, 2)
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfunc – 要应用的 Lambda/函数。它也可以是 Callable 的序列,每个元素对应于
keys中的一个键。inv_func – 如果要反转转换,则为逆操作的 Lambda/函数,默认为
lambda x: x。它也可以是 Callable 的序列,每个元素对应于keys中的一个键。track_meta – 如果 False,则将返回标准数据对象(例如,torch.Tensor` 和 np.ndarray),而不是 MONAI 的增强对象。默认情况下,这是 True。
overwrite – 是否用 lambda 函数的输出覆盖输入字典中的原始数据。它可以是 bool 或 str,当设置为 str 时,它将为输出创建一个新键并保留原始键的值不变。默认为 True。它也可以是 bool 或 str 的序列,每个元素对应于
keys中的一个键。allow_missing_keys – 如果键丢失,则不引发异常。
- 注意:逆操作不允许定义
extra_info或访问其他信息,例如图像的原始大小。 如果需要这些复杂信息,请直接编写一个新的 InvertibleTransform。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]- 返回值:
应用转换后
data的更新字典版本。
RandLambdad#
- class monai.transforms.RandLambdad(*args, **kwargs)[source]#
monai.transforms.Lambdad的随机化版本,输入的func可能包含随机逻辑,或者根据prob随机执行函数。因此CacheDataset不会执行并缓存结果。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfunc – 要应用的 Lambda/函数。它也可以是 Callable 的序列,每个元素对应于
keys中的一个键。inv_func – 如果要反转转换,则为逆操作的 Lambda/函数,默认为
lambda x: x。它也可以是 Callable 的序列,每个元素对应于keys中的一个键。track_meta – 如果 False,则将返回标准数据对象(例如,torch.Tensor` 和 np.ndarray),而不是 MONAI 的增强对象。默认情况下,这是 True。
overwrite – 是否用 lambda 函数的输出覆盖输入字典中的原始数据。默认为 True。它也可以是 bool 序列,每个元素对应于
keys中的一个键。prob – 执行随机函数的概率,默认为 1.0,即 100% 概率执行。请注意,
keys指定的所有数据将共享相同的随机概率来决定是否执行。allow_missing_keys – 如果键丢失,则不引发异常。
更多详细信息,请查看
monai.transforms.Lambdad。- 注意:逆操作不允许定义
extra_info或访问其他信息,例如图像的原始大小。 如果需要这些复杂信息,请直接编写一个新的 InvertibleTransform。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
RemoveRepeatedChanneld#
- class monai.transforms.RemoveRepeatedChanneld(keys, repeats, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.RemoveRepeatedChannel包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
LabelToMaskd#
- class monai.transforms.LabelToMaskd(*args, **kwargs)[source]#
基于字典的
monai.transforms.LabelToMask包装器。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformselect_labels – 用于生成掩膜的标签。对于 1 通道标签,select_labels 是期望的标签值,例如:[1, 2, 3]。对于 One-Hot 格式标签,select_labels 是期望的通道索引。
merge_channels – 是否使用 np.any() 在通道维度上合并结果。如果是,将返回一个带有二值数据的单通道掩膜。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
FgBgToIndicesd#
- class monai.transforms.FgBgToIndicesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.FgBgToIndices包装器。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformfg_postfix – 用于在字典中保存计算出的前景索引的后缀。例如,如果在 label 上计算且
postfix = “_fg_indices”,则键将为label_fg_indices。bg_postfix – 用于在字典中保存计算出的背景索引的后缀。例如,如果在 label 上计算且
postfix = “_bg_indices”,则键将为label_bg_indices。image_key – 如果 image_key 不为 None,使用
label == 0 & image > image_threshold来确定负样本(背景)。因此输出项不会映射到标签中的所有体素。image_threshold – 如果启用了 image_key,使用
image > image_threshold来确定有效的图像内容区域,并且仅在此区域中选择背景。output_shape – 输出索引的期望形状。如果不是 None,将索引展开到指定的形状。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ClassesToIndicesd#
- class monai.transforms.ClassesToIndicesd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ClassesToIndices包装器。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformindices_postfix – 用于在字典中保存所有类计算索引的后缀。例如,如果在 label 上计算且
postfix = “_cls_indices”,则键将为label_cls_indices。num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
image_key – 如果 image_key 不为 None,使用
image > image_threshold定义有效区域,并且仅选择有效区域内的索引。image_threshold – 如果启用了 image_key,使用
image > image_threshold来确定有效的图像内容区域,并且仅在此区域中选择类的索引。output_shape – 输出索引的期望形状。如果不是 None,将索引展开到指定的形状。
max_samples_per_class – 每个类别中要采样的索引的最大长度,以减少内存消耗。默认为 None,不进行子采样。
allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
ConvertToMultiChannelBasedOnBratsClassesd#
- class monai.transforms.ConvertToMultiChannelBasedOnBratsClassesd(keys, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.ConvertToMultiChannelBasedOnBratsClasses包装器。根据 brats18 类将标签转换为多通道:标签 1 是坏死和非增强性肿瘤核心,标签 2 是瘤周水肿,标签 4 是 GD 增强性肿瘤。可能的类别包括 TC(肿瘤核心)、WT(整个肿瘤)和 ET(增强肿瘤)。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
AddExtremePointsChanneld#
- class monai.transforms.AddExtremePointsChanneld(*args, **kwargs)[source]#
基于字典的
monai.transforms.AddExtremePointsChannel包装器。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformlabel_key – 用于获取极值点的标签源键。
background – 背景标签的类别索引,默认为 0。
pert – 添加到点的随机扰动量,默认为 0.0。
sigma – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
rescale_min – 输出数据的最小值。
rescale_max – 输出数据的最大值。
allow_missing_keys – 如果键丢失,则不引发异常。
TorchVisiond#
- class monai.transforms.TorchVisiond(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
基于字典的
monai.transforms.TorchVision包装器,用于非随机化转换。对于 TorchVision 的随机化转换,请使用monai.transforms.RandTorchVisiond。注意
由于大多数 TorchVision 转换仅适用于 PIL 图像和 PyTorch Tensor,此转换期望输入数据是 PyTorch Tensors 的字典,用户可以轻松调用
ToTensord转换将 Numpy 转换为 Tensor。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformname (
str) – TorchVision 包中的变换名称。allow_missing_keys (
bool) – 如果键缺失,不引发异常。args – TorchVision 变换的参数。
kwargs – TorchVision 变换的参数。
RandTorchVisiond#
- class monai.transforms.RandTorchVisiond(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
基于字典的
monai.transforms.TorchVision包装器,用于随机化转换。对于 TorchVision 的确定性非随机化转换,请使用monai.transforms.TorchVisiond。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformname (
str) – TorchVision 包中的变换名称。allow_missing_keys (
bool) – 如果键缺失,不引发异常。args – TorchVision 变换的参数。
kwargs – TorchVision 变换的参数。
注意
由于大多数 TorchVision 转换仅适用于 PIL 图像和 PyTorch Tensor,此转换期望输入数据是 PyTorch Tensors 的字典。用户应首先调用
ToTensord转换将 Numpy 转换为 Tensor。此类继承
Randomizable纯粹是为了防止任何数据集缓存跳过转换计算。如果底层 torchvision 转换的随机因子不是派生自self.R,结果可能不是确定性的。另请参阅:monai.transforms.Randomizable。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
MapLabelValued#
- class monai.transforms.MapLabelValued(keys, orig_labels, target_labels, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.MapLabelValue包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, orig_labels, target_labels, dtype=<class 'numpy.float32'>, allow_missing_keys=False)[source]#
- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformorig_labels (
Sequence) – 原始标签,将被映射到其他值。target_labels (
Sequence) – 期望的标签值,与 orig_labels 一一对应。dtype (
Union[dtype,type,str,None]) – 将输出数据转换为指定的 dtype,默认为 float32。如果 dtype 来自 PyTorch,则变换将使用 pytorch 后端,否则使用 numpy 后端。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
EnsureTyped#
- class monai.transforms.EnsureTyped(*args, **kwargs)[source]#
基于字典的
monai.transforms.EnsureType包装器。确保输入数据是 PyTorch Tensor 或 numpy 数组,支持:
numpy array、PyTorch Tensor、float、int、bool、string和保留原始object。如果传入字典、列表或元组,仍返回字典、列表或元组,并且如果wrap_sequence=False,则递归地将每个项转换为预期的数据类型。注意:目前,在逆操作中,我们仅将张量数据转换为 numpy 数组或标量数字。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, data_type='tensor', dtype=None, device=None, wrap_sequence=True, track_meta=None, allow_missing_keys=False)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformdata_type – 目标数据类型,应为 "tensor" 或 "numpy"。
dtype – 要转换的目标数据内容类型,例如:np.float32, torch.float 等。它也可以是 dtype 序列,每个元素对应于
keys中的一个键。device – 对于 Tensor 数据类型,指定目标设备。
wrap_sequence – 如果 False,则列表将递归调用此函数,默认为 True。例如,如果 False,则 [1, 2] -> [tensor(1), tensor(2)];如果 True,则 [1, 2] -> tensor([1, 2])。
track_meta – 当
data_type为 “tensor” 时,是否转换为MetaTensor。如果为 False,则输出数据类型将为torch.Tensor。默认为get_track_meta的返回值。allow_missing_keys – 如果键丢失,则不引发异常。
IntensityStatsd#
- class monai.transforms.IntensityStatsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.IntensityStats包装器。计算输入图像强度值的统计信息并存储到元数据字典中。例如:如果ops=[lambda x: np.mean(x), “max”]且key_prefix=”orig”,可能会生成以下统计信息:{“orig_custom_0”: 1.5, “orig_max”: 3.0}。- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformops – 期望用于计算强度统计的操作。如果是字符串,则映射到预定义的操作,支持:["mean", "median", "max", "min", "std"],分别映射到 np.nanmean、np.nanmedian、np.nanmax、np.nanmin、np.nanstd。如果是可调用的函数,则在输入图像上执行该函数。
key_prefix – 用于与 ops 名称组合生成键,以将结果存储到元数据字典中。如果某些 ops 是可调用函数,则将使用 "{key_prefix}_custom_{index}" 作为键,其中索引从 0 开始计数。
mask_keys – 如果不为 None,则指定图像的掩码数组,以仅提取感兴趣的区域来计算统计信息,掩码必须与图像具有相同的形状。它应该是一个字符串序列或 None,映射到
keys。channel_wise – 是否分别计算输入图像每个通道的统计信息。如果为 True,则对每个操作返回一个值列表,默认为 False。
meta_keys – 显式指示相应元数据字典的键。用于将计算出的统计信息存储到元字典中。例如,对于键为
image的数据,元数据默认位于image_meta_dict中。元数据是一个字典对象,包含:文件名、原始形状等。它可以是字符串序列,映射到keys。如果为 None,将尝试通过key_{meta_key_postfix}构建 meta_keys。meta_key_postfix – 如果 meta_keys 为 None,则使用
key_{postfix}根据键数据获取元数据,默认为meta_dict,元数据是一个字典对象。用于将计算出的统计信息存储到元字典中。allow_missing_keys – 如果键丢失,则不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ToDeviced#
- class monai.transforms.ToDeviced(*args, **kwargs)[source]#
基于字典的
monai.transforms.ToDevice包装器。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Tensor]- 返回值:
应用转换后
data的更新字典版本。
- __init__(keys, device, allow_missing_keys=False, **kwargs)[source]#
- 参数:
keys – 对应要变换的项的键。另请参见:
monai.transforms.compose.MapTransformdevice – 目标设备,用于移动 Tensor,例如:"cuda:1"。
allow_missing_keys – 如果键丢失,则不引发异常。
kwargs – PyTorch Tensor.to() API 的其他参数,更多详情请参见:https://pytorch.ac.cn/docs/stable/generated/torch.Tensor.to.html。
CuCIMd#
- class monai.transforms.CuCIMd(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
基于字典的
monai.transforms.CuCIM包装器,用于非随机化转换。对于 CuCIM 的随机化转换,请使用monai.transforms.RandCuCIMd。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformname (
str) – CuCIM 包中的转换名称。allow_missing_keys (
bool) – 如果键缺失,不引发异常。args – CuCIM 变换的参数。
kwargs – CuCIM 变换的参数。
注意
CuCIM 转换仅适用于 CuPy 数组,此转换期望输入数据为
cupy.ndarray。用户可以调用ToCuPy转换将 numpy 数组或 torch 张量转换为 cupy 数组。
RandCuCIMd#
- class monai.transforms.RandCuCIMd(keys, name, allow_missing_keys=False, *args, **kwargs)[source]#
基于字典的
monai.transforms.CuCIM包装器,用于随机化转换。对于 CuCIM 的确定性非随机化转换,请使用monai.transforms.CuCIMd。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformname (
str) – CuCIM 包中的转换名称。allow_missing_keys (
bool) – 如果键缺失,不引发异常。args – CuCIM 变换的参数。
kwargs – CuCIM 变换的参数。
注意
CuCIM 转换仅适用于 CuPy 数组,因此此转换期望输入数据为
cupy.ndarray。用户应首先调用ToCuPy转换将 numpy 数组或 torch 张量转换为 cupy 数组。此类继承
Randomizable纯粹是为了防止任何数据集缓存跳过转换计算。如果底层 cuCIM 转换的随机因子不是派生自self.R,结果可能不是确定性的。另请参阅:monai.transforms.Randomizable。
AddCoordinateChannelsd#
- class monai.transforms.AddCoordinateChannelsd(keys, spatial_dims, allow_missing_keys=False)[source]#
基于字典的
monai.transforms.AddCoordinateChannels包装器。- 参数:
keys (
Union[Collection[Hashable],Hashable]) – 对应要变换的项的键。另请参见:monai.transforms.compose.MapTransformspatial_dims (
Sequence[int]) – 需要在通道中编码其坐标并附加到输入图像的空间维度。例如,(0, 1, 2) 表示 H, W, D 维度,并向输入图像附加三个通道,编码输入数据的三个空间维度的坐标。allow_missing_keys (
bool) – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ImageFilterd#
- class monai.transforms.ImageFilterd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ImageFilter包装器。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
kernel – 指定核的字符串,或作为
torch.Tenor或np.ndarray的自定义核。可用选项包括:mean、laplacian、elliptical、sobel_{w,h,d}kernel_size – 指定二次或三次核大小的单个整数值。计算复杂度随 kernel_size 呈指数级增长,在选择核大小时应予以考虑。
allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
RandImageFilterd#
- class monai.transforms.RandImageFilterd(*args, **kwargs)[source]#
基于字典的
monai.transforms.RandomFilterKernel包装器。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
kernel – 指定核的字符串,或作为
torch.Tenor或np.ndarray的自定义核。可用选项包括:mean、laplacian、elliptical、sobel_{w,h,d}kernel_size – 指定二次或三次核大小的单个整数值。计算复杂度随 kernel_size 呈指数级增长,在选择核大小时应予以考虑。
prob – 变换应用于数据的概率。
allow_missing_keys – 如果键缺失,不引发异常。
注意
此转换不会自动缩放输出图像值以匹配输入的范围。如果需要,应通过后续转换来缩放输出以匹配输入。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
ApplyTransformToPointsd#
- class monai.transforms.ApplyTransformToPointsd(*args, **kwargs)[source]#
基于字典的
monai.transforms.ApplyTransformToPoints包装器。输入坐标假定为形状 (C, N, 2 或 3),其中 C 表示通道数,N 表示点数。输出与输入具有相同的形状。- 参数:
keys – 要转换的相应项的键。另请参见: monai.transforms.MapTransform
refer_keys – 用于变换的参考项的键。它可以直接引用仿射变换或从中可以推导出仿射变换的图像。它也可以是键序列,在这种情况下,每个键都指向应用于
keys中匹配点的仿射变换。dtype – 输出所需的 数据类型。
affine – 应用于点的 3x3 或 4x4 仿射变换矩阵。此矩阵通常源自图像。对于 2D 点,可以提供 3x3 矩阵,避免添加不必要的 Z 维度。虽然 3D 变换需要 4x4 矩阵,但请注意,将 4x4 矩阵应用于 2D 点时,会相应地处理附加维度。该矩阵始终转换为 float64 进行计算,这在应用于大量点时计算成本可能很高。如果为 None,将尝试使用参考数据中的仿射矩阵。
invert_affine – 是否反转应用于点的仿射变换矩阵。默认为
True。通常,仿射矩阵派生自图像,而点位于世界坐标系中。如果想将点与图像对齐,请将其设置为True。否则,将其设置为False。affine_lps_to_ras – 默认为
False。如果您的点数据采用 RAS 坐标系或您正在使用带有 affine_lps_to_ras=True 的 ITKReader,则设置为 True。这确保了在 LPS (left-posterior-superior) 和 RAS (right-anterior-superior) 坐标系之间正确应用仿射变换。此参数确保点和仿射矩阵位于同一坐标系中。allow_missing_keys – 如果键缺失,不引发异常。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回值:
应用转换后
data的更新字典版本。
MetaTensor#
ToMetaTensord#
- class monai.transforms.ToMetaTensord(keys, allow_missing_keys=False)[source]#
基于字典的转换,用于将字典转换为 MetaTensor。
如果输入是
{“a”: torch.Tensor, “a_meta_dict”: dict, “b”: …},则输出将采用{“a”: MetaTensor, “b”: MetaTensor}的形式。- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
FromMetaTensord#
- class monai.transforms.FromMetaTensord(*args, **kwargs)[source]#
基于字典的转换,用于将 MetaTensor 转换为字典。
如果输入是 {“a”: MetaTensor, “b”: MetaTensor},则输出将具有以下形式 {“a”: torch.Tensor, “a_meta_dict”: dict, “a_transforms”: list, “b”: …}。
- __call__(data)[source]#
data通常来自对可迭代对象(如torch.utils.data.Dataset)的迭代。为简化输入验证,此方法假定
data是一个 Python 字典,data[key]是 Numpy ndarray、PyTorch Tensor 或字符串,其中key是self.keys的元素,数据形状可以是无形状的字符串数据,LoadImaged 转换需要文件路径,
大多数预处理/后处理转换需要:
(通道数, 空间维度_1[, 空间维度_2, ...]),例如 AddChanneld 需要 (spatial_dim_1[, spatial_dim_2, …])
即使通道数为一,通道维度也通常不省略。
- 抛出异常:
NotImplementedError – 当子类未重写此方法时。
- 返回类型:
dict[Hashable,Union[ndarray,Tensor]]- 返回值:
应用转换后
data的更新字典版本。
转换适配器#
如何使用 adaptor 函数#
使用 ‘adaptor’ 的关键在于理解要适配的函数。‘inputs’ 和 ‘outputs’ 参数根据被调用的函数的调用签名,可以是字符串、字符串列表/元组或映射字符串的字典。
adaptor 函数的设计旨在最小化调用者的认知负担。调用者需要设置输入参数的情况应该很少。对于返回单个值的函数,只需要命名字典关键字,该值将被赋值给该关键字。
outputs 的用法#
outputs 可以是字符串、字符串列表/元组或字符串到字符串的字典,具体取决于被适配的转换的返回值。
如果转换返回单个参数,则可以为 outputs 提供一个字符串,该字符串指示在字典中将返回值分配给哪个键。
如果转换返回一个值列表/元组,则可以为 outputs 提供一个相同长度的列表/元组。outputs 中的字符串将相应位置的返回值映射到字典中的键。
如果转换返回一个值字典,则必须为 outputs 提供一个字典,该字典将函数返回字典中的键映射到在函数之间传递的字典。
请注意,调用者可以自由地使用比必需的更复杂的方式来指定 outputs 参数。以下是同义的,将被视为相同:
# single argument
adaptor(MyTransform(), 'image')
adaptor(MyTransform(), ['image'])
adaptor(MyTransform(), {'image': 'image'})
# multiple arguments
adaptor(MyTransform(), ['image', 'label'])
adaptor(MyTransform(), {'image': 'image', 'label': 'label'})
inputs 的用法#
在使用 adaptor 时,通常可以省略 inputs。只有当函数的参数名称与用于链式调用转换的字典中的名称不匹配时才需要它。
class MyTransform1:
def __call__(self, image):
# do stuff to image
return image + 1
class MyTransform2:
def __call__(self, img_dict):
# do stuff to image
img_dict["image"] += 1
return img_dict
xform = Compose([adaptor(MyTransform1(), "image"), MyTransform2()])
d = {"image": 1}
print(xform(d))
>>> {'image': 3}
class MyTransform3:
def __call__(self, img_dict):
# do stuff to image
img_dict["image"] -= 1
img_dict["segment"] = img_dict["image"]
return img_dict
class MyTransform4:
def __call__(self, img, seg):
# do stuff to image
img -= 1
seg -= 1
return img, seg
xform = Compose([MyTransform3(), adaptor(MyTransform4(), ["img", "seg"], {"image": "img", "segment": "seg"})])
d = {"image": 1}
print(xform(d))
>>> {'image': 0, 'segment': 0, 'img': -1, 'seg': -1}
输入
字典输入:None | 名称映射
参数输入(匹配):None | 名称列表 | 名称映射
参数输入(不匹配):名称映射
参数和 **kwargs(匹配):None | 名称映射
参数和 **kwargs(不匹配):名称映射
输出
字典输出:None | 名称映射
列表/元组输出:list/tuple
变量输出:string
FunctionSignature#
adaptor#
apply_alias#
to_kwargs#
实用工具#
- class monai.transforms.utils..Fourier[source]#
存储傅里叶映射的辅助类
- monai.transforms.utils.allow_missing_keys_mode(transform)#
临时设置所有 MapTransforms 在缺少键时不抛出错误。之后恢复原始状态。
- 参数:
transform – MapTransform 或 Compose 之一
示例
data = {"image": np.arange(16, dtype=float).reshape(1, 4, 4)} t = SpatialPadd(["image", "label"], 10, allow_missing_keys=False) _ = t(data) # would raise exception with allow_missing_keys_mode(t): _ = t(data) # OK!
- monai.transforms.utils..attach_hook(func, hook, mode='pre')[source]#
在 func 调用之前或之后添加 hook。如果 mode 是 “pre”,包装器将先调用 hook 再调用 func。如果 mode 是 “post”,包装器将先调用 func 再调用 hook。
- monai.transforms.utils.check_non_lazy_pending_ops(input_array, name=None, raise_error=False)[source]#
检查输入数组是否有待处理的操作,如果存在则抛出错误或发出警告。
- 参数:
input_array – 要检查的输入数组。
name – 可选名称,将包含在错误消息中。
raise_error – 是否抛出错误,默认为 False,此时将发出警告消息。
- monai.transforms.utils.compute_divisible_spatial_size(spatial_shape, k)[source]#
计算目标空间大小,该大小应能被 k 整除。
- 参数:
spatial_shape – 原始空间形状。
k – 每个空间维度的目标 k。如果 k 为负或 0,则保留原始大小。如果 k 是整数,则相同的 k 将应用于所有输入空间维度。
- monai.transforms.utils.convert_applied_interp_mode(trans_info, mode='nearest', align_corners=None)[source]#
递归地更改应用操作栈中的插值模式,默认为“nearest”。
参见:
monai.transform.inverse.InvertibleTransform- 参数:
trans_info – 应用的操作栈,跟踪之前应用的逆变换。
mode – 要转换的目标插值模式,默认为“nearest”,因为它通常用于保存模式输出。
align_corners – PyTorch 插值 API 中的目标 align corner 值,需要与 mode 对齐。
- monai.transforms.utils.convert_pad_mode(dst, mode)[source]#
在 numpy 数组和 PyTorch 张量之间转换填充模式的实用工具。
- 参数:
dst – 要转换填充模式的目标数据,应为 numpy 数组或 PyTorch 张量。
mode – 当前填充模式。
- monai.transforms.utils.convert_points_to_disc(image_size, point, point_label, radius=2, disc=False)[source]#
将 3D 点坐标转换为图像掩码。返回的掩码具有与 image_size 相同的空间大小,而批次维度与 ‘point’ 的批次维度相同。点将转换为半径由 radius 定义的掩码球体。输出包含两个通道,分别用于负点(第一个通道)和正点(第二个通道)。
- 参数:
image_size (
Sequence[int]) – 转换后掩码的输出大小。它应为 3D 元组。point (
Tensor) – [B, N, 3],3D 点坐标。point_label (
Tensor) – [B, N],0 或 2 表示负点,1 或 3 表示正点。radius (
int) – 球体半径大小。disc (
bool) – 如果为 True,使用规则球体,否则使用高斯。
- monai.transforms.utils.convert_to_contiguous(data, **kwargs)[source]#
检查并确保数据中的 numpy 数组或 PyTorch 张量在内存中是连续的。
- 参数:
data – 要转换的输入数据,将递归地转换字典和序列中的 numpy 数组或 PyTorch 张量。
kwargs – 如果 x 是 PyTorch 张量,则为 torch.contiguous 的附加参数,更多详细信息请参阅: https://pytorch.ac.cn/docs/stable/generated/torch.Tensor.contiguous.html#torch.Tensor.contiguous。
- monai.transforms.utils.copypaste_arrays(src_shape, dest_shape, srccenter, destcenter, dims)[source]#
计算切片,以便将 src_shape 数组中的切片区域复制到 dest_shape 数组中。
该区域具有维度 dims(使用 0 或 None 表示复制该维度中的所有内容),源区域的中心位于 src 中 srccenter 索引处,并复制到 dest 中 destcenter 为中心的区域。复制区域的维度将被裁剪以适应源数组和目标数组,因此复制的区域可能比预期的要小。返回值是切片对象组成的元组,分别索引 src 中的复制区域和 dest 中的复制区域。
示例
src_shape = (6,6) src = np.random.randint(0,10,src_shape) dest = np.zeros_like(src) srcslices, destslices = copypaste_arrays(src_shape, dest.shape, (3, 2),(2, 1),(3, 4)) dest[destslices] = src[srcslices] print(src) print(dest) >>> [[9 5 6 6 9 6] [4 3 5 6 1 2] [0 7 3 2 4 1] [3 0 0 1 5 1] [9 4 7 1 8 2] [6 6 5 8 6 7]] [[0 0 0 0 0 0] [7 3 2 4 0 0] [0 0 1 5 0 0] [4 7 1 8 0 0] [0 0 0 0 0 0] [0 0 0 0 0 0]]
- monai.transforms.utils.create_control_grid(spatial_shape, spacing, homogeneous=True, dtype=<class 'float'>, device=None, backend=numpy)[source]#
在每个方向上增加两个附加点的控制网格
- monai.transforms.utils.create_grid(spatial_size, spacing=None, homogeneous=True, dtype=<class 'float'>, device=None, backend=numpy)[source]#
计算 spatial_size 网格。
当
homogeneous=True时,输出形状为 (N+1, dim_size_1, dim_size_2, …, dim_size_N)当
homogeneous=False时,输出形状为 (N, dim_size_1, dim_size_2, …, dim_size_N)
- 参数:
spatial_size – 网格的空间大小。
spacing – 与
spatial_size长度相同,默认为 1.0(密集网格)。homogeneous – 是否生成齐次坐标。
dtype – 输出网格数据类型,默认为 float。
device – 用于计算和存储输出的设备(当后端为 “torch” 时)。
backend – 要使用的 API,
numpy或torch。
- monai.transforms.utils.create_rotate(spatial_dims, radians, device=None, backend=numpy)[source]#
创建一个 2D 或 3D 旋转矩阵
- 参数:
spatial_dims – {
2,3} 空间秩radians – 旋转弧度,当 spatial_dims == 3 时,radians 序列对应于第 1、2、3 维的旋转。
device – 用于计算和存储输出的设备(当后端为 “torch” 时)。
backend – 要使用的 API,
numpy或torch。
- 抛出异常:
ValueError – 当
radians为空时。ValueError – 当
spatial_dims不是 [2, 3] 之一时。
- monai.transforms.utils.create_scale(spatial_dims, scaling_factor, device=None, backend=numpy)[source]#
创建一个缩放矩阵
- 参数:
spatial_dims – 空间秩
scaling_factor – 每个空间维度的缩放因子,默认为 1。
device – 用于计算和存储输出的设备(当后端为 “torch” 时)。
backend – 要使用的 API,
numpy或torch。
- monai.transforms.utils..create_shear(spatial_dims, coefs, device=None, backend=numpy)[source]#
创建一个切变矩阵
- 参数:
spatial_dims – 空间秩
coefs –
切变因子,2D 为 2 个浮点数元组,3D 为 6 个浮点数元组),以 3D 仿射为例
[ [1.0, coefs[0], coefs[1], 0.0], [coefs[2], 1.0, coefs[3], 0.0], [coefs[4], coefs[5], 1.0, 0.0], [0.0, 0.0, 0.0, 1.0], ]
device – 用于计算和存储输出的设备(当后端为 “torch” 时)。
backend – 要使用的 API,
numpy或torch。
- 抛出异常:
NotImplementedError – 当
spatial_dims不是 [2, 3] 之一时。
- monai.transforms.utils.create_translate(spatial_dims, shift, device=None, backend=numpy)[source]#
创建一个平移矩阵
- 参数:
spatial_dims – 空间秩
shift – 每个空间维度的平移像素/体素,默认为 0。
device – 用于计算和存储输出的设备(当后端为 “torch” 时)。
backend – 要使用的 API,
numpy或torch。
- monai.transforms.utils.distance_transform_edt(img, sampling=None, return_distances=True, return_indices=False, distances=None, indices=None, *, block_params=None, float64_distances=False)[source]#
欧几里德距离变换,可基于 CuPy / cuCIM 使用 GPU,也可基于 scipy 使用 CPU。要使用 GPU 实现,请确保已安装 cuCIM 并且数据是位于 GPU 设备上的 torch.tensor。
请注意,不同库的结果可能不同,因此如果可能,请坚持使用一个库。有关详细信息,请查阅 SciPy 和 cuCIM 文档。
- 参数:
img – 要运行距离变换的输入图像。必须是 channel first 数组,形状必须为:(num_channels, H, W [,D])。可以是任何类型,但将被转换为二进制:图像为 True 的地方为 1,其他地方为 0。输入以通道方式传递给距离变换,因此此函数的结果将与直接调用 CuPy 或 SciPy 中的
distance_transform_edt()不同。sampling – 沿每个维度的元素间距。如果是序列,其长度必须等于输入秩减 1;如果是单个数字,则用于所有轴。如果未指定,则表示单位网格间距。
return_distances – 是否计算距离变换。
return_indices – 是否计算特征变换。
distances – 用于存储计算出的距离变换的输出数组,而不是返回它。return_distances 必须为 True。
indices – 用于存储计算出的特征变换的输出数组,而不是返回它。return_indicies 必须为 True。
block_params – 此参数特定于 cuCIM,在 SciPy 中不存在。有关详细信息,请查阅 cuCIM。
float64_distances – 此参数特定于 cuCIM,在 SciPy 中不存在。如果为 True,距离计算使用双精度(以匹配 SciPy 行为)。否则,将使用单精度以提高效率。
- 返回值:
- 计算出的距离变换。仅当 return_distances 为 True 且未提供 distances 时返回。
其形状和类型与图像相同。对于 cuCIM:如果 float64_distances 为 True,则 dtype 将为 torch.float64,否则为 torch.float32。对于 SciPy:dtype 将为 np.float64。
- indices: 计算出的特征变换。每个图像维度都有一个图像形状的数组。
类型将等于图像的类型。仅当 return_indices 为 True 且未提供 indices 时返回。dtype np.float64。
- 返回类型:
distances
- monai.transforms.utils.equalize_hist(img, mask=None, num_bins=256, min=0, max=255)[source]#
根据直方图均衡化输入图像的实用工具。如果安装了 skimage,将利用 skimage.exposure.histogram,否则使用 np.histogram。
- 参数:
img – 要均衡化的输入图像。
mask – 如果提供,必须是布尔或 0 和 1 的 ndarray,并且与 image 形状相同。只有 mask==True 的点才用于均衡化。
num_bins – 直方图中使用的 bin 数量,默认为 256。更多详情请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.histogram.html。
min – 用于归一化输入图像的最小值,默认为 0。
max – 用于归一化输入图像的最大值,默认为 255。
- monai.transforms.utils.extreme_points_to_image(points, label, sigma=0.0, rescale_min=-1.0, rescale_max=1.0)[source]#
请参阅
monai.transforms.AddExtremePointsChannel以了解用法。对极值点图像应用高斯滤波器。然后将极值点图像中的像素值重新缩放到 [rescale_min, rescale_max] 范围。
- 参数:
points – 对象/器官的极值点。
label – 用于获取极值点的标签图像。形状必须是 (1, spatial_dim1, [, spatial_dim2, …])。不支持 one-hot 标签。
sigma – 如果是一个值列表,必须与输入数据的空间维度数匹配,并将列表中的每个值应用于一个空间维度。如果只提供一个值,则将其用于所有空间维度。
rescale_min – 输出数据的最小值。
rescale_max – 输出数据的最大值。
- monai.transforms.utils.fill_holes(img_arr, applied_labels=None, connectivity=None)[source]#
填充提供的图像中的空洞。
标签 0 将被视为背景,封闭的孔将被设置为相邻的类别标签。何为封闭的孔由连通性定义。边缘上的孔总是被视为开放(非封闭)的。
注意
此方法的性能在很大程度上取决于标签数量。如果提供了 applied_labels 列表,则速度会更快一些。限制 applied_labels 的数量会大大减少处理时间。
如果图像是 one-hot-encoded 格式,则 applied_labels 需要与通道索引匹配。
- 参数:
img_arr – 形状为 [C, spatial_dim1[, spatial_dim2, …]] 的 numpy 数组。
applied_labels – 要填充空洞的标签。默认为 None,即填充所有标签的空洞。
connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。默认为 input.ndim 的完全连接性。
- 返回值:
形状为 [C, spatial_dim1[, spatial_dim2, …]] 的 numpy 数组。
- monai.transforms.utils.generate_label_classes_crop_centers(spatial_size, num_samples, label_spatial_shape, indices, ratios=None, rand_state=None, allow_smaller=False, warn=True)[source]#
根据指定的标签类别比例生成有效的样本位置。有效:样本完全位于图像内,预期输入形状:[C, H, W, D] 或 [C, H, W]
- 参数:
spatial_size – 要采样的 ROI 的空间大小。
num_samples – 要生成的总样本中心数量。
label_spatial_shape – 原始标签数据的空间形状,用于展开选定的中心。
indices – 在一维中每个类别的预计算前景索引序列。
ratios – 标签中每个类别(包括背景类别)生成裁剪中心的比例。如果为 None,则每个类别生成裁剪中心的比例相同。
rand_state – numpy randomState 对象,用于与其他模块对齐。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
warn – 如果为 True,则如果标签中不存在某个类别,则打印警告。
- monai.transforms.utils.generate_pos_neg_label_crop_centers(spatial_size, num_samples, pos_ratio, label_spatial_shape, fg_indices, bg_indices, rand_state=None, allow_smaller=False)[source]#
根据标签生成有效的样本位置,并可选择指定前景比例。有效:样本完全位于图像内,预期输入形状:[C, H, W, D] 或 [C, H, W]
- 参数:
spatial_size – 要采样的 ROI 的空间大小。
num_samples – 要生成的总样本中心数量。
pos_ratio – 生成的总位置中,中心为前景的比例。
label_spatial_shape – 原始标签数据的空间形状,用于展开选定的中心。
fg_indices – 预计算的一维前景索引。
bg_indices – 预计算的一维背景索引。
rand_state – numpy randomState 对象,用于与其他模块对齐。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
- 抛出异常:
ValueError – 当提议的 roi 大于图像时。
ValueError – 当前景和背景索引长度为 0 时。
- monai.transforms.utils.generate_spatial_bounding_box(img, select_fn=<function is_positive>, channel_indices=None, margin=0, allow_smaller=True)[source]#
生成图像中前景的空间边界框,包含起始和结束位置。用户可以定义任意函数从整个图像或指定通道中选择预期的前景。它还可以在边界框的每个维度上添加边距。坐标的输出格式为:
[第 1 空间维度起始,第 2 空间维度起始,…,第 N 空间维度起始],[第 1 空间维度结束,第 2 空间维度结束,…,第 N 空间维度结束]
如果不存在正强度,此函数返回 [0, 0, …], [0, 0, …]。
- 参数:
img – 形状为 (C, spatial_dim1[, spatial_dim2, …]) 的“通道优先”图像,用于生成边界框。
select_fn – 用于选择预期前景的函数,默认选择大于 0 的值。
channel_indices – 如果已定义,则仅在图像的指定通道上选择前景。如果为 None,则在整个图像上选择前景。
margin – 向边界框的空间维度添加 margin 值,如果只提供一个值,则将其用于所有维度。
allow_smaller – 当使用 margin 计算框大小时,是否允许图像边缘小于最终框边缘。如果为 True,边界框边缘与输入图像边缘对齐;如果为 False,边界框边缘与最终框边缘对齐。默认为 True。
- monai.transforms.utils.get_extreme_points(img, rand_state=None, background=0, pert=0.0)[source]#
从图像生成极值点。这些用于为标注模型生成初始分割。可以传递可选的扰动以模拟用户点击。
- 参数:
img – 要从中生成极值点的图像。预期形状为
(spatial_dim1, [, spatial_dim2, ...])。rand_state – 用于选择随机索引的 np.random.RandomState 对象。
background – 视为背景的值,默认为 0。
pert – 添加到点的随机扰动量,默认为 0.0。
- 返回值:
极值点列表,其长度等于输入图像空间维度的 2 倍。坐标的输出格式为:
[第 1 空间维度最小值,第 1 空间维度最大值,第 2 空间维度最小值,…,第 N 空间维度最大值]
- 抛出异常:
ValueError – 当输入图像没有任何前景像素时。
- monai.transforms.utils.get_largest_connected_component_mask(img, connectivity=None, num_components=1)[source]#
获取图像的最大连通分量掩码。
- 参数:
img – 要从中获取最大连通分量的图像。形状为 (spatial_dim1 [, spatial_dim2, …])
connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅:https://scikit-image.cn/docs/dev/api/skimage.measure.html#skimage.measure.label。num_components – 要保留的最大连通分量的数量。
- monai.transforms.utils.get_number_image_type_conversions(transform, test_data, key=None)[source]#
获取数据需要转换(例如,numpy 到 torch)的次数。不同设备之间的转换(例如,CPU 到 GPU)也计算在内。
- 参数:
transform – 要测试的组合变换
test_data – 用于计算转换次数的数据
key – 如果使用字典变换,此键将用于检查转换次数。
- monai.transforms.utils.get_transform_backends()[source]#
获取所有 MONAI 变换的后端。
- 返回值:
字典,其中每个键是一个变换,其对应的值是一个布尔列表,说明该变换是否支持 (1) torch.Tensor 和 (2) np.ndarray 作为输入,而无需转换。
- monai.transforms.utils.get_unique_labels(img, is_onehot, discard=None)[source]#
获取图像中非背景标签的列表。
- 参数:
img – 要处理的图像。形状应为 [C, W, H, [D]],如果不是 onehot 则 C=1,否则为 num_classes。
is_onehot – 输入图像是否为 one-hotted 的布尔值。如果是 one-hotted,只返回通道,其中
discard – 可用于移除标签(例如背景)。可以是任何值、值序列或 None(不丢弃任何内容)。
- 返回值:
标签集合
- monai.transforms.utils.has_status_keys(data, status_key, default_message='No message provided')[source]#
检查给定的张量在其任何应用操作上是否具有特定的状态键消息。如果没有,它返回元组 (False, None)。如果存在,它返回一个元组,其中第一个元素是 True,第二个元素是该状态键对应的状态消息列表。
状态键在
TraceStatusKeys中定义。此函数还接受:
张量字典
张量列表或元组
张量字典的列表或元组
在上述任何情况下,它都会迭代集合并递归执行自身,直到操作对象是张量。
- 参数:
data (
Tensor) – torch.Tensor 或 MetaTensor 或 torch.Tensor 或 MetaTensor 的集合,如上所述status_key (
Any) – 要查找的状态键,来自 TraceStatusKeysdefault_message (
str) – 如果状态键条目未设置消息,则使用的默认消息
- 返回值:
一个元组。第一个元素是 False 或 True。第二个元素是可以用于帮助用户调试其管道的状态消息列表。
- monai.transforms.utils.in_bounds(x, y, margin, maxx, maxy)[source]#
如果 (x,y) 位于矩形 (margin, margin, maxx-margin, maxy-margin) 内,则返回 True。
- 返回类型:
bool
- monai.transforms.utils.keep_components_with_positive_points(img, point_coords, point_labels)[source]#
保留包含正点的连通区域。用于仅使用点的推理后处理,以移除不含正点的区域。:type img:
Tensor:param img: [1, B, H, W, D]。来自 VISTA3D 的输出预测。值在 sigmoid 之前且包含 NaN 值。:type point_coords:Tensor:param point_coords: [B, N, 3]。点点击坐标。:type point_labels:Tensor:param point_labels: [B, N]。点点击标签。- 返回类型:
Tensor
- monai.transforms.utils.keep_merge_components_with_points(img_pos, img_neg, point_coords, point_labels, pos_val=(1, 3), neg_val=(0, 2), margins=3)[source]#
分别保留包含正点和负点的 img_pos 和 img_neg 的连通区域。此函数用于在 VISTA3D 中合并自动结果和交互式结果。
- 参数:
img_pos (~NdarrayTensor) – 布尔类型张量,形状 [B, 1, H, W, D],其中 B 表示单个 3D 图像的前景掩码。
img_neg (~NdarrayTensor) – 格式与 img_pos 相同,但对应于负点。
pos_val (
Sequence[int]) – 正点标签值。neg_val (
Sequence[int]) – 负点标签值。point_coords (~NdarrayTensor) – 每个点的坐标,形状 [B, N, 3],其中 N 表示点数。
point_labels (~NdarrayTensor) – 每个点的标签,形状 [B, N]。
margins (
int) – 包含区域外部但在边距内的点。
- 返回类型:
~NdarrayTensor
- monai.transforms.utils.map_and_generate_sampling_centers(label, spatial_size, num_samples, label_spatial_shape=None, num_classes=None, image=None, image_threshold=0.0, max_samples_per_class=None, ratios=None, rand_state=None, allow_smaller=False, warn=True)[source]#
结合“map_classes_to_indices”和“generate_label_classes_crop_centers”函数,返回裁剪中心坐标。此函数调用 map_classes_to_indices 从 label 获取索引,如果给出 label_spatial_shape 则从中获取形状,否则从标签获取形状,调用 generate_label_classes_crop_centers 并返回其结果。
- 参数:
label – 使用标签数据获取每个类别的索引。
spatial_size – 要采样的 ROI 的空间大小。
num_samples – 要生成的总样本中心数量。
label_spatial_shape – 原始标签数据的空间形状,用于展开选定的中心。
indices – 在一维中每个类别的预计算前景索引序列。
num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
image – 如果 image 不为 None,则仅返回图像有效区域(
image > image_threshold)内的每个类别的索引。image_threshold – 如果启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅在该区域中选择类别索引。max_samples_per_class – 每个类别中索引的最大长度,以减少内存消耗。默认为 None,不进行二次采样。
ratios – 标签中每个类别(包括背景类别)生成裁剪中心的比例。如果为 None,则每个类别生成裁剪中心的比例相同。
rand_state – numpy randomState 对象,用于与其他模块对齐。
allow_smaller – 如果为 False,则如果图像在任何维度小于请求的 ROI,将引发异常。如果为 True,任何较小的维度将保持不变。
warn – 如果为 True,则如果标签中不存在某个类别,则打印警告。
- 返回值:
裁剪中心的元组
- monai.transforms.utils.map_binary_to_indices(label, image=None, image_threshold=0.0)[source]#
计算输入标签数据的前景和背景,返回展平后的索引。例如:
label = np.array([[[0, 1, 1], [1, 0, 1], [1, 1, 0]]])foreground indices = np.array([1, 2, 3, 5, 6, 7])和background indices = np.array([0, 4, 8])- 参数:
label – 使用标签数据获取前景/背景信息。
image – 如果 image 不是 None,则使用
label = 0 & image > image_threshold定义背景。因此输出项不会映射到标签中的所有体素。image_threshold – 如果启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅在此区域选择背景。
- monai.transforms.utils.map_classes_to_indices(label, num_classes=None, image=None, image_threshold=0.0, max_samples_per_class=None)[source]#
过滤出输入标签数据中每个类别的索引,返回展平后的索引。它可以处理 One-Hot 格式标签和 Argmax 格式标签,对于 Argmax 标签必须提供 num_classes。
例如:
label = np.array([[[0, 1, 2], [2, 0, 1], [1, 2, 0]]])并且 num_classes=3,将返回一个包含 3 个类别索引的列表:[np.array([0, 4, 8]), np.array([1, 5, 6]), np.array([2, 3, 7])]- 参数:
label – 使用标签数据获取每个类别的索引。
num_classes – Argmax 标签的类别数量,对于 One-Hot 标签不是必需的。
image – 如果 image 不为 None,则仅返回图像有效区域(
image > image_threshold)内的每个类别的索引。image_threshold – 如果启用了 image,则使用
image > image_threshold来确定有效的图像内容区域,并仅在该区域中选择类别索引。max_samples_per_class – 每个类别中索引的最大长度,以减少内存消耗。默认为 None,不进行二次采样。
- monai.transforms.utils.map_spatial_axes(img_ndim, spatial_axes=None, channel_first=True)[source]#
将空间轴映射到 channel first/last 形状中实际轴的实用工具。例如:如果 channel_first 为 True,并且 img 有 3 个空间维度,则空间轴映射到实际轴如下: None -> [1, 2, 3] [0, 1] -> [1, 2] [0, -1] -> [1, -1] 如果 channel_first 为 False,并且 img 有 3 个空间维度,则空间轴映射到实际轴如下: None -> [0, 1, 2] [0, 1] -> [0, 1] [0, -1] -> [0, -2]
- 参数:
img_ndim – 目标图像的维度数。
spatial_axes – 要转换的空间轴,默认为 None。默认的 None 将转换到图像的所有空间轴。如果轴为负,则从最后一个轴到第一个轴计数。如果轴是整数元组。
channel_first – 图像数据是 channel first 还是 channel last,默认为 channel first。
- monai.transforms.utils.rand_choice(prob=0.5)[source]#
如果随机选择的数字小于或等于 prob,则返回 True,默认为 50/50 的几率。
- 返回类型:
bool
- monai.transforms.utils.remove_small_objects(img, min_size=64, connectivity=1, independent_channels=True, by_measure=False, pixdim=None)[source]#
使用 skimage.morphology.remove_small_objects 从图像中移除小物体。请参阅:https://scikit-image.cn/docs/dev/api/skimage.morphology.html#remove-small-objects。
数据应该是一热编码的。
- 参数:
img – 要处理的图像。预期形状:C, H,W,[D]。预期只具有单例通道维度,即非 one-hotted。转换为 int 类型。
min_size – 小于此大小的对象将被移除。
connectivity – 将像素/体素视为邻居的最大正交跳数。接受的值范围为 1 到 input.ndim。如果
None,则使用 input.ndim 的完全连接性。更多详情请参阅链接的 scikit-image 文档。independent_channels – 是否独立考虑每个通道。
by_measure – 指定的 min_size 是否以体素数量为单位。如果为 True,则 min_size 表示图像单位(mm^3, cm^2 等)的表面积或体积值,默认为 False。
pixdim – 输入图像的像素尺寸。如果为单个数字,则用于所有轴。如果是数字序列,序列长度必须等于图像维度。
- monai.transforms.utils.rescale_array(arr, minv=0.0, maxv=1.0, dtype=<class 'numpy.float32'>)[source]#
将 numpy 数组 arr 的值重新缩放到 minv 到 maxv 之间。如果 minv 或 maxv 中的任何一个为 None,则返回 (a - min_a) / (max_a - min_a)。
- 参数:
arr – 要重新缩放的输入数组。
minv – 目标重新缩放数组的最小值。
maxv – 目标重新缩放数组的最大值。
dtype – 如果不是 None,则在计算前将输入数组转换为 dtype。
- monai.transforms.utils.rescale_array_int_max(arr, dtype=<class 'numpy.uint16'>)[source]#
将数组 arr 重新缩放到 dtype 类型的最小值和最大值之间。
- 返回类型:
ndarray
- monai.transforms.utils.rescale_instance_array(arr, minv=0.0, maxv=1.0, dtype=<class 'numpy.float32'>)[source]#
独立地重新缩放 arr 沿第一个维度的每个数组切片。
- monai.transforms.utils.reset_ops_id(data)[source]#
在列表或字典 data 中查找 MetaTensor,并(原地)将
TraceKeys.ID设置为Tracekeys.NONE。
- monai.transforms.utils.resize_center(img, *resize_dims, fill_value=0.0, inplace=True)[source]#
通过从中心裁剪或扩展图像来调整 img 的大小。resize_dims 值是输出维度(或 None 表示使用 img 的原始维度)。如果一个维度小于 img 的相应维度,则结果将被裁剪;如果更大,则用零填充。在这两种情况下,操作都是相对于 img 的中心进行的。结果是一个新图像,具有指定的维度并将 img 中的值复制到其中心。
- monai.transforms.utils.resolves_modes(interp_mode='constant', padding_mode='zeros', backend=torch, **kwargs)#
自动调整重采样插值模式和填充模式,使其与 backend 的相应 API 兼容。根据后端的可用性,当没有精确的对应模式时,将返回类似的模式。
- 参数:
interp_mode – 插值模式。
padding_mode – 填充模式。
backend – TransformBackends 的可选后端。如果为 None,后端将根据 interp_mode 决定。
kwargs – 附加关键字参数。当前支持
torch_interpolate_spatial_nd,用于提供额外信息来确定linear、bilinear和trilinear;以及use_compiled,用于使用 MONAI 的预编译后端 (pytorch c++ 扩展),默认为False。
- monai.transforms.utils.scale_affine(spatial_size, new_spatial_size, centered=True)[source]#
根据新的空间大小计算缩放矩阵
- 参数:
spatial_size – 原始空间大小。
new_spatial_size – 新的空间大小。
centered (
bool) – 缩放是相对于图像中心 (True,默认) 还是角点 (False)。
- 返回值:
缩放矩阵。
- monai.transforms.utils.soft_clip(arr, sharpness_factor=1.0, minv=None, maxv=None, dtype=<class 'numpy.float32'>)[source]#
对输入数组或张量应用软剪裁。强度值将根据 f(x) = x + (1/sharpness_factor)*softplus(- c(x - minv)) - (1/sharpness_factor)*softplus(c(x - maxv)) 进行软剪裁。参考 https://medium.com/life-at-hopper/clip-it-clip-it-good-1f1bf711b291
要执行单边剪裁,将 minv 或 maxv 设置为 None。 :param arr: 要剪裁的输入数组。 :param sharpness_factor: 软剪裁函数的锐度,默认为 1。 :param minv: 目标剪裁数组的最小值。 :param maxv: 目标剪裁数组的最大值。 :param dtype: 如果不为 None,则在计算前将输入数组转换为 dtype。
- monai.transforms.utils.sync_meta_info(key, data_dict, t=True)[source]#
给定键,同步元张量 data_dict[key] 和元字典 data_dict[key_transforms/meta_dict] 之间的信息。t=True:元张量或元字典中 applied_operations 较多的那个是输出,False:较少的那个是输出。
- monai.transforms.utils.weighted_patch_samples(spatial_size, w, n_samples=1, r_state=None)[source]#
给定采样权重图 w 和 patch spatial_size,计算 n_samples 个随机 patch 采样位置。
- 参数:
spatial_size – patch 的每个空间维度的长度。
w – 权重图,权重必须是非负的。每个元素表示空间位置的采样权重。0 表示不采样。权重图的形状假定为
(spatial_dim_0, spatial_dim_1, ..., spatial_dim_n)。n_samples – patch 样本数
r_state – 随机状态容器
- 返回值:
一个包含 n_samples 个 N 维整数的列表,表示 patch 的空间采样位置。
- monai.transforms.utils.zero_margins(img, margin)[source]#
如果 img 在维度 1 和 2 的边缘 margin 索引范围内的值都为 0,则返回 True。
- 返回类型:
bool
- monai.transforms.utils_pytorch_numpy_unification.allclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False)[source]#
np.allclose 函数,在 torch 中有等效实现。
- 返回类型:
bool
- monai.transforms.utils_pytorch_numpy_unification.any_np_pt(x, axis)[source]#
np.any 函数,在 torch 中有等效实现。
对于 pytorch,转换为布尔值以兼容旧版本。
- 参数:
x – 输入数组/张量。
axis – 执行 any 操作的轴。
- 返回值:
返回一个连续的扁平数组/张量。
- monai.transforms.utils_pytorch_numpy_unification.argsort(a, axis=-1)[source]#
np.argsort 函数,在 torch 中有等效实现。
- 参数:
a – 要排序的数组/张量。
axis – 沿其排序的轴。
- 返回值:
沿指定轴对 a 进行排序的索引数组/张量。
- monai.transforms.utils_pytorch_numpy_unification.argwhere(a)[source]#
np.argwhere 函数,在 torch 中有等效实现。
- 参数:
a (~NdarrayTensor) – 输入数据。
- 返回类型:
~NdarrayTensor
- 返回值:
非零元素的索引。索引按元素分组。此数组的形状为 (N, a.ndim),其中 N 为非零元素的数量。
- monai.transforms.utils_pytorch_numpy_unification.ascontiguousarray(x, **kwargs)[source]#
np.ascontiguousarray 函数,在 torch 中有等效实现 (contiguous)。
- 参数:
x – 数组/张量。
kwargs – 如果 x 是 PyTorch 张量,则为 torch.contiguous 的附加参数,更多详情请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.Tensor.contiguous.html。
- monai.transforms.utils_pytorch_numpy_unification.clip(a, a_min, a_max)[source]#
np.clip 函数,在 torch 中有等效实现。
- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.concatenate(to_cat, axis=0, out=None)[source]#
np.concatenate 函数,在 torch 中有等效实现 (torch.cat)。
- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.cumsum(a, axis=None, **kwargs)[source]#
np.cumsum 函数,在 torch 中有等效实现。
- 参数:
a (
Union[ndarray,Tensor]) – 用于计算累加和的输入数据。axis – 预期计算累加和的轴。
kwargs – 如果 a 是 PyTorch 张量,则为 torch.cumsum 的附加参数,更多详情请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.cumsum.html。
- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.floor_divide(a, b)[source]#
np.floor_divide 函数,在 torch 中有等效实现。
从 pt1.8 开始,使用 torch.div(…, rounding_mode=”floor”),在此之前使用 torch.floor_divide。
- 参数:
a (
Union[ndarray,Tensor]) – 第一个数组/张量b – 用于除法的标量
- 返回类型:
Union[ndarray,Tensor]- 返回值:
两个数组/张量之间的逐元素向下取整除法。
- monai.transforms.utils_pytorch_numpy_unification.isfinite(x)[source]#
np.isfinite 函数,在 torch 中有等效实现。
- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.isnan(x)[source]#
np.isnan 函数,在 torch 中有等效实现。
- 参数:
x (
Union[ndarray,Tensor]) – 数组/张量。- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_pytorch_numpy_unification.max(x, dim=None, **kwargs)[source]#
torch.max 函数,在 numpy 中有等效实现。
- 参数:
x – 数组/张量。
- 返回值:
x 的最大值。
- monai.transforms.utils_pytorch_numpy_unification.maximum(a, b)[source]#
np.maximum 函数,在 torch 中有等效实现。
- 参数:
a (
Union[ndarray,Tensor]) – 第一个数组/张量。b (
Union[ndarray,Tensor]) – 第二个数组/张量。
- 返回类型:
Union[ndarray,Tensor]- 返回值:
两个数组/张量之间的逐元素最大值。
- monai.transforms.utils_pytorch_numpy_unification.mean(x, dim=None, **kwargs)[source]#
torch.mean 函数,在 numpy 中有等效实现。
- 参数:
x – 数组/张量。
- 返回值:
x 的均值。
- monai.transforms.utils_pytorch_numpy_unification.median(x, dim=None, **kwargs)[source]#
torch.median 函数,在 numpy 中有等效实现。
- 参数:
x – 数组/张量。
- 返回
x 的中位数。
- monai.transforms.utils_pytorch_numpy_unification.min(x, dim=None, **kwargs)[source]#
torch.min 函数,在 numpy 中有等效实现。
- 参数:
x – 数组/张量。
- 返回值:
x 的最小值。
- monai.transforms.utils_pytorch_numpy_unification.mode(x, dim=-1, to_long=True)[source]#
torch.mode 函数,在 numpy 中有等效实现。
- 参数:
x (~NdarrayTensor) – 数组/张量。
dim (
int) – 执行 mode 操作的维度(在 numpy 中称为 axis)。to_long (
bool) – 在执行 mode 操作之前将输入转换为 long 类型。
- 返回类型:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.moveaxis(x, src, dst)[source]#
用于 pytorch 和 numpy 的 moveaxis 函数。
- monai.transforms.utils_pytorch_numpy_unification.nonzero(x)[source]#
np.nonzero 函数,在 torch 中有等效实现。
- 参数:
x (
Union[ndarray,Tensor]) – 数组/张量。- 返回类型:
Union[ndarray,Tensor]- 返回值:
给定形状的展开索引
- monai.transforms.utils_pytorch_numpy_unification.percentile(x, q, dim=None, keepdim=False, **kwargs)[source]#
np.percentile 函数,在 torch 中有等效实现。
Pytorch 使用 quantile。更多详情请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.quantile.html。https://numpy.com.cn/doc/stable/reference/generated/numpy.percentile.html。
- 参数:
x – 输入数据。
q – 要计算的百分位数(应在 0 <= q <= 100 范围内)。
dim – 计算百分位数的维度。默认为沿数组的展平版本计算百分位数。
keepdim – 输出数据是否保留维度。
kwargs – 如果 x 是 numpy 数组,则为 np.percentile 的附加参数,更多详情请参阅:https://numpy.com.cn/doc/stable/reference/generated/numpy.percentile.html。
- 返回值:
结果值(标量)
- monai.transforms.utils_pytorch_numpy_unification.ravel(x)[source]#
np.ravel 函数,在 torch 中有等效实现。
- 参数:
x (
Union[ndarray,Tensor]) – 要展平的数组/张量。- 返回类型:
Union[ndarray,Tensor]- 返回值:
返回一个连续的扁平数组/张量。
- monai.transforms.utils_pytorch_numpy_unification.repeat(a, repeats, axis=None, **kwargs)[source]#
np.repeat 函数,在 torch 中有等效实现 (repeat_interleave)。
- 参数:
a – 要重复的输入数据。
repeats – 每个元素的重复次数,repeats 将广播以匹配给定轴的形状。
axis – 沿其重复值的轴。
kwargs – 如果 a 是 PyTorch 张量,则为 torch.repeat_interleave 的附加参数,更多详情请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.repeat_interleave.html。
- monai.transforms.utils_pytorch_numpy_unification.searchsorted(a, v, right=False, sorter=None, **kwargs)[source]#
np.searchsorted 函数,在 torch 中有等效实现。
- 参数:
a (~NdarrayTensor) – numpy 数组或张量,在最内层维度上包含单调递增序列。
v (
Union[ndarray,Tensor]) – 包含搜索值。right – 如果为 False,返回找到的第一个合适位置;如果为 True,返回最后一个 such index。
sorter – 如果 a 是 numpy 数组,可选的整数索引数组,用于将数组 a 排序为升序。
kwargs – 如果 a 是 PyTorch 张量,则为 torch.searchsorted 的附加参数,更多详情请参阅:https://pytorch.ac.cn/docs/stable/generated/torch.searchsorted.html。
- 返回类型:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.softplus(x)[source]#
通过 np.logaddexp 实现稳定的 softplus 函数,在 torch 中有等效实现。
- 参数:
x (
Union[ndarray,Tensor]) – 数组/张量。- 返回类型:
Union[ndarray,Tensor]- 返回值:
输入的 Softplus 值。
- monai.transforms.utils_pytorch_numpy_unification.stack(x, dim)[source]#
np.stack 函数,在 torch 中有等效实现。
- 参数:
x (
Sequence[~NdarrayTensor]) – 数组/张量。dim (
int) – 执行堆叠操作的维度(在 numpy 中称为 axis)。
- 返回类型:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.std(x, dim=None, unbiased=False)[source]#
torch.std 函数,在 numpy 中有等效实现。
- 参数:
x – 数组/张量。
- 返回值:
x 的标准差。
- monai.transforms.utils_pytorch_numpy_unification.unique(x, **kwargs)[source]#
torch.unique 函数,在 numpy 中有等效实现。
- 参数:
x (~NdarrayTensor) – 数组/张量。
- 返回类型:
~NdarrayTensor
- monai.transforms.utils_pytorch_numpy_unification.unravel_index(idx, shape)[source]#
np.unravel_index 函数,在 torch 中有等效实现。
- 参数:
idx – 要展开的索引。
shape – 数组/张量的形状。
- 返回类型:
Union[ndarray,Tensor]- 返回值:
给定形状的展开索引
- monai.transforms.utils_pytorch_numpy_unification.unravel_indices(idx, shape)[source]#
从索引计算展开坐标。
- 参数:
idx – 要展开的索引序列。
shape – 数组/张量的形状。
- 返回类型:
Union[ndarray,Tensor]- 返回值:
给定形状的堆叠展开索引。
- monai.transforms.utils_pytorch_numpy_unification.where(condition, x=None, y=None)[source]#
请注意,torch.where 可能会将 y.dtype 转换为 x.dtype。
- 返回类型:
Union[ndarray,Tensor]
- monai.transforms.utils_morphological_ops.dilate(mask, filter_size=3, pad_value=0.0)[source]#
膨胀 2D/3D 二值掩码。
- 参数:
mask – 输入 2D/3D 二值掩码,[N,C,M,N] 或 [N,C,M,N,P] torch 张量或 ndarray。
filter_size – 膨胀滤波器大小,必须是奇数,默认为 3。
pad_value – 填充的值。我们需要在滤波前对输入进行填充,以保持输出与输入大小相同。通常使用默认值且不变。
- 返回值:
膨胀后的掩码,与输入形状和数据类型相同。
示例
# define a naive mask mask = torch.zeros(3,2,3,3,3) mask[:,:,1,1,1] = 1.0 filter_size = 3 erode_result = erode(mask,filter_size) # expect torch.zeros(3,2,3,3,3) dilate_result = dilate(mask,filter_size) # expect torch.ones(3,2,3,3,3)
- monai.transforms.utils_morphological_ops.erode(mask, filter_size=3, pad_value=1.0)[source]#
腐蚀 2D/3D 二值掩码。
- 参数:
mask – 输入 2D/3D 二值掩码,[N,C,M,N] 或 [N,C,M,N,P] torch 张量或 ndarray。
filter_size – 腐蚀滤波器大小,必须是奇数,默认为 3。
pad_value – 填充的值。我们需要在滤波前对输入进行填充,以保持输出与输入大小相同。通常使用默认值且不变。
- 返回值:
腐蚀后的掩码,与输入形状和数据类型相同。
示例
# define a naive mask mask = torch.zeros(3,2,3,3,3) mask[:,:,1,1,1] = 1.0 filter_size = 3 erode_result = erode(mask, filter_size) # expect torch.zeros(3,2,3,3,3) dilate_result = dilate(mask, filter_size) # expect torch.ones(3,2,3,3,3)