0.6 版本新特性#
解批处理作为重要的后处理步骤
Python 风格的 API,用于加载 Clara Train MMAR 中的预训练模型
UNETR: 用于医学图像分割的 Transformer 模型
基础度量接口的增强
通过 PyTorch JIT 编译的 C++/CUDA 扩展模块
向后兼容性及增强的持续集成/持续交付
与 Project-MONAI/MONAILabel 协作实现平滑集成
解批处理作为重要的后处理步骤#
decollate batch 在 MONAI v0.6 中引入,用于简化后处理转换,并对批量模型输出进行灵活操作。它可以将批量数据(例如模型推理结果)解压为张量列表——作为 PyTorch 数据加载器的 collate_fn 的“逆”操作。它的优点包括:
为每个项目独立启用后处理转换,例如,随机转换可以对批处理中的每个预测项目应用不同的方式。
简化转换 API 并减少输入验证负担,因为现在预处理和后处理转换都只支持“channel-first”输入格式。
为不同原始形状的数据项目启用转换逆操作,因为逆转后的项目是列表形式,而不是堆叠在单个张量中。
允许使用“batch-first”张量和“channel-first”张量列表进行灵活的指标计算。
decollate batch 的典型过程如下图所示(以 batch_size=N 的模型预测和标签为例): 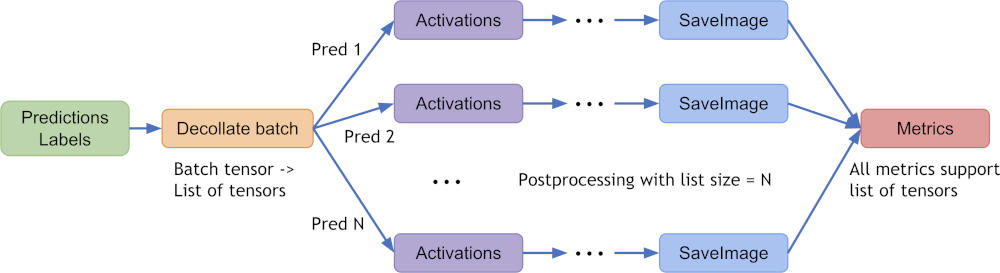
decollate batch 教程 展示了基于 PyTorch 原生工作流的详细使用示例。
将 v0.5 代码迁移到 v0.6 wiki 展示了如何将现有程序从 v0.5 迁移到 v0.6 以适应 decollate batch 逻辑。
UNETR: 用于医学图像分割的 Transformer 模型#
UNETR 是一个基于 Transformer 的体绘制 (3D) 医学图像分割模型,目前在 BTCV 数据集 测试服务器上的多器官语义分割任务中处于领先地位。UNETR 在 MONAI v0.6 中引入,其灵活的实现支持各种分割任务。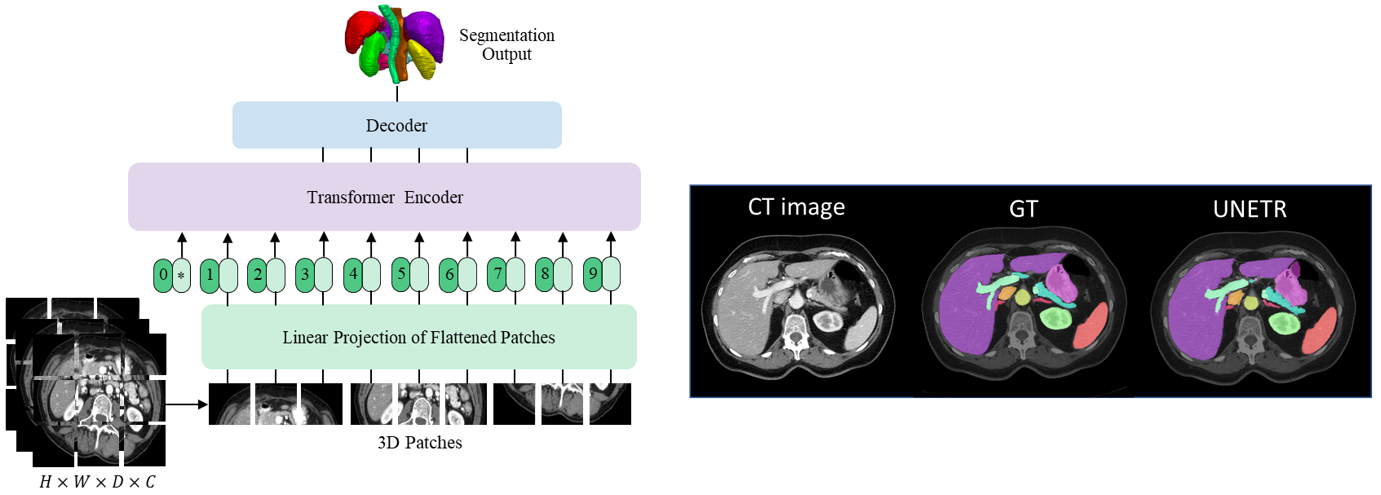
在 project-monai/tutorials 中提供了一个使用 UNETR 进行 3D 多器官语义分割任务的教程。它包含以下特性:
用于字典格式数据的转换,
根据 MONAI 转换 API 定义新的转换,
加载包含元数据的 Nifti 图像,加载图像列表并堆叠它们,
随机调整强度以进行数据增强,
优化缓存 IO 和转换以加速训练和验证,
用于多器官分割任务的 3D UNETR 模型、DiceCE 损失函数和 Mean Dice 度量,
下图展示了在本教程中进行分割的目标身体器官: 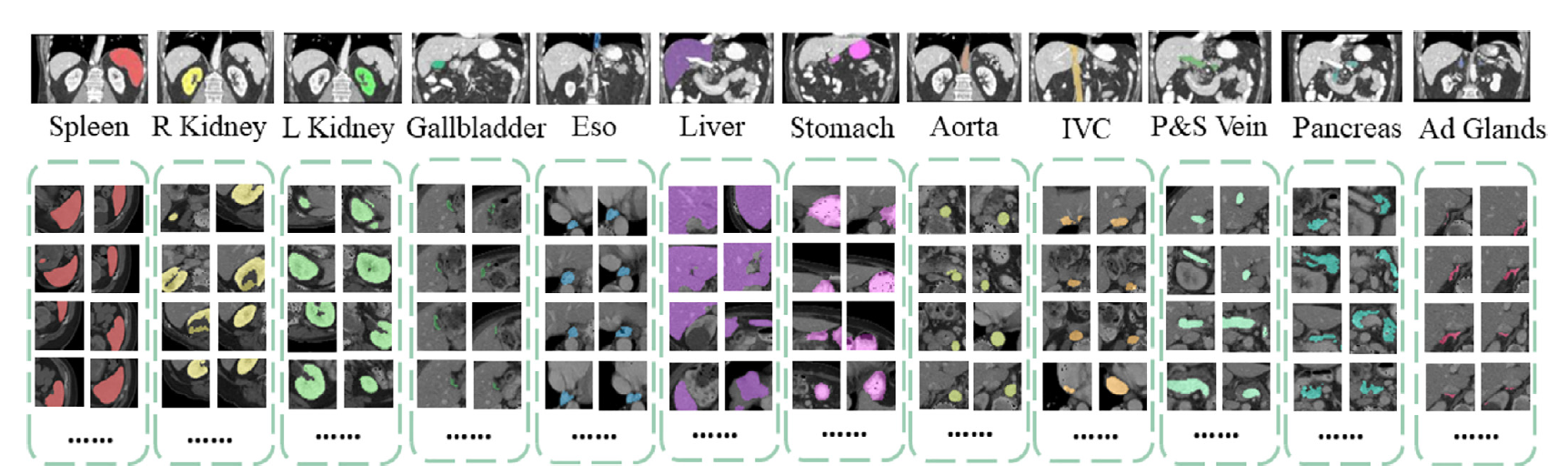
请访问 UNETR 仓库了解更多详情:https://monai.org.cn/research/unetr-btcv-multi-organ-segmentation
Python 风格的 API,用于加载 Clara Train MMAR 中的预训练模型#
MMAR (Medical Model ARchive) 定义了一种数据结构,用于组织模型开发生命周期中产生的所有工件。NVIDIA Clara 提供 各种医学领域特定模型的 MMAR。这些 MMAR 包含关于模型的所有信息,包括配置和脚本,提供一个工作空间来执行模型开发任务。为了更好地利用在 Nvidia GPU 云上发布的已训练 MMAR,MONAI 提供了 Python 风格的 API 来访问它们。
为了演示这一新功能,在 project-monai/tutorials 中创建了一个医学图像分割教程。它主要生成下图,用于比较以下情况的损失曲线和验证分数:
从头开始训练(绿线),
应用预训练 MMAR 权重但不进行训练(品红线),
从 MMAR 模型权重开始训练(蓝线),
根据训练 epoch 数量。
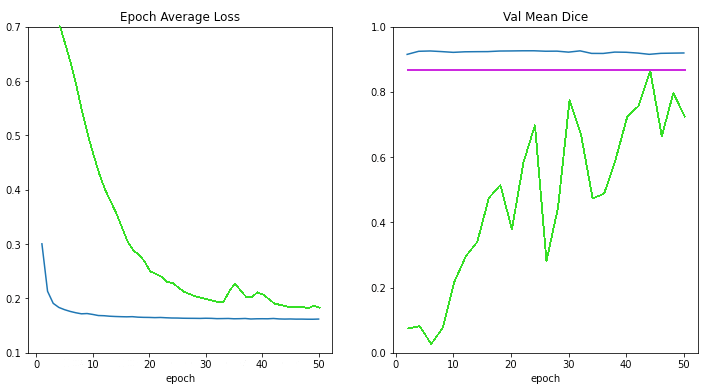
本教程展示了封装 MMAR 解析细节的能力,以及使用预训练 MMAR 进行迁移学习的潜力。这些 API 也被集成到 AI 辅助的交互式工作流中,以加速手动标注过程(例如,通过 project-MONAI/MONAILabel)。
基础度量接口的增强#
基础度量 API 现在得到增强,以支持基于迭代和基于 epoch 的度量的核心计算逻辑。通过此更新,MONAI 度量模块变得更具可扩展性,因此是定制度量的一个良好起点。这些 API 默认也支持数据并行计算并考虑计算效率:通过 Cumulative 基类,中间度量结果可以自动缓存、累加、跨分布式进程同步,并聚合最终结果。多进程计算示例 展示了如何在多进程环境中基于保存的预测和标签计算度量。
通过 PyTorch JIT 编译的 C++/CUDA 扩展模块#
为了进一步加速工作流中的领域特定例程,MONAI 引入了 C++/CUDA 模块作为 PyTorch 原生实现的扩展。它现在提供了使用 从 PyTorch 构建 C++ 扩展的两种方法 的模块:
通过
setuptools(自 MONAI v0.5 起),用于包括Resampler、Conditional random field (CRF)、Fast bilateral filtering using the permutohedral lattice在内的模块。通过即时 (JIT) 编译(自 MONAI v0.6 起),用于
Gaussian mixtures模块。这种方法允许根据用户指定的参数和本地系统环境进行动态优化。下图展示了 MONAI 的高斯混合模型应用于组织和手术工具分割任务的结果:
向后兼容性及增强的持续集成/持续交付#
从这个版本开始,我们尝试基本的向后兼容性策略。在现有的语义版本控制模块和 Git 分支模型之上引入了新的工具。
同时,我们积极分析高效、可扩展和安全的 CI/CD 解决方案,以适应快速协作的代码库开发。
尽管完整的机制仍在开发中,但这为 MONAI 的 API 稳定版本、可持续发布周期以及高效开源协作迈出了又一个重要步骤。
与 Project-MONAI/MONAILabel 协作实现平滑集成#
自 MONAI v0.6 起,我们欢迎 MONAILabel 加入 Project-MONAI。
MONAI Label 是一个智能开源图像标注和学习工具,使用户能够创建带标注的数据集并构建用于临床评估的 AI 标注模型。MONAI Label 使应用程序开发人员能够以无服务器的方式构建标注应用,通过 MONAI Label 服务器将自定义标注应用作为服务公开。
请访问 MONAILabel 文档网站了解详情:https://docs.monai.org.cn/projects/label/en/stable/